Живущее в сети. Откуда берется интернет — Публикации — город Рязань на городском сайте RZN.info
Живущее в сети. Откуда берется интернет
Интернет уже давно стал настолько привычным понятием, что мы не задумываясь говорим о работе в нем «выложи», «скачай», «посмотри».
Пытаясь найти, сколько костей в скелете человека или написав запрос в поисковике «есть ли в продаже билеты на московский концерт Элтона Джона», информацию мы получаем почти мгновенно. Но откуда она к нам приходит? Где хранится? И как туда попадает?
Интернет уже давно стал настолько привычным понятием, что мы не задумываясь говорим о работе в нем «выложи», «скачай», «посмотри». Через интернет мы общаемся, обмениваемся документами, смотрим кино и слушаем музыку. А где, собственно, находится сам интернет, где он живет?
Интернет — это в первую очередь информация. Различные файлы, тексты, фотографии или аудиозаписи, которые люди загружают в сеть, чтобы сделать их общедоступными. Осязаемо, интернет — это всегда носители данных, то есть серверы, на которых эта информация и хранится.
Интернет — это в первую очередь информация
Сами серверы располагаются в специализированных центрах обработки информации или, иначе, дата-центрах, которые располагаются по всему миру. В них же находится оборудование, позволяющее выбрать информацию, отсортировать и выдать пользователю в том виде, в котором он хочет.
Для того, чтобы своими глазами увидеть, как выглядит дата-центр, мы отправились в один из рязанских дата-центров. Перед входом банковская бронированная дверь с многоступенчатой системой допуска: коды, магнитный ключ, реагирующий на отпечаток пальца замок. На двери висит табличка: «Вход строго в бахилах». Внутри — высокие шкафы, паутина проводов, новогоднее мигание множества светодиодов.
Серверы располагаются в специализированных центрах обработки информации или, иначе, дата-центрах
Основное здесь, конечно, стойки с серверами и другим телекоммуникационным оборудованием. Каждая стойка закрыта на ключ, некоторые даже опечатаны. Условно говоря, здесь располагаются компьютеры. Но сравнивать их с привычными нам настольными было бы некорректно — их объединяет лишь умение хранить и обрабатывать информацию.
Каждая стойка закрыта на ключ, некоторые даже опечатаны. Условно говоря, здесь располагаются компьютеры. Но сравнивать их с привычными нам настольными было бы некорректно — их объединяет лишь умение хранить и обрабатывать информацию.
«Как думаешь, что это?» — спрашивает директор дата-центра Михаил Ростов, показывая на большие закрытые шкафы, стоящие вдоль стены, — «Это источники бесперебойного питания» Глядя на эти «холодильники», я вспоминаю маленький «бесперебойник», стоящий у меня дома под столом, и сразу возникает вопрос «какова же их емкость?». Достаточная для того, чтобы в случае отключения электричества с гарантией обеспечить работу всего центра до тех пор, пока не запустится генератор.
Дата-центр имеет мощные источники бесперебойного питания и запасной генератор
Какая часть интернета живет здесь? Ресурсы крупных региональных интернет-операторов, некоторые государственные информационные системы, данные которых по закону должны храниться на территории России.
«Вопрос: как ты говоришь по «Скайпу» с абонентом, например, «Спарка»?» — спрашивает Михаил, и я пожимаю плечами. — «Где-то рано или поздно их коммуникации соединены кабелем. В хорошем случае — в Рязани, в среднем — в Москве, а могут где-нибудь в Стокгольме. Но дата-центр именно та площадка, где они в конце концов встречаются на соседних стойках».
«Вот смотри» — Михаил показывает на одну из панелей с проводами, — «Здесь соединяются два разных интернет-провайдера. Из этого разъема сигнал выходит и в этот заходит. А внутри происходит обмен потоком информации».
Запрос пользователя поступает в дата-центр, обрабатывается и возвращается в виде ответа
«Чем отличается дата центр от обычных помещений, где стоит аналогичное оборудование?» — продолжает Михаил, — «Дата-центр имеет такие качества как отказоустойчивость по питанию — есть мощные источники бесперебойного питания и запасной генератор, который автоматически включается, если отключается электричество.
Здесь физическая безопасность, защита от внешних воздействий, от актов вандализма и разных противоправных действий. Но, главное — качество сети, к которой он подключен. Ведь обязанность дата-центра — обеспечивать непрерывность связи, поэтому кабели, которые сюда подходят, имеют гарантированную пропускную способность, которая не зависит ни от чего».
Дата-центр — промежуточное звено в цепочке между создателем информации и ее потребителем и суть его работы в том, что каждый запрос пользователя — адрес сайта, слово в строке поиска или клик на ссылку — поступает в дата-центр, обрабатывается и возвращается в виде ответа. Например, введенный в адресной строке браузера адрес сайта обрабатывается в дата-центре провайдера и отправляется в итоге на конкретный сервер, где располагается сайт.
Причем, дата-центр, в котором находится этот сервер может быть как в соседнем квартале, так и на другом материке. Если целевая аудитория компании находится в России, Европе и Америке, то ее сайт может быть физически распределенным на три континента. У крупных компаний, таких как, например, Facebook или Google, серверы располагаются в тысяче дата-центров, разбросанных по всему миру. Кстати, крупнейший в России дата-центр расположен в городе Сасово Рязанской области и принадлежит компании Яндекс.
Если целевая аудитория компании находится в России, Европе и Америке, то ее сайт может быть физически распределенным на три континента. У крупных компаний, таких как, например, Facebook или Google, серверы располагаются в тысяче дата-центров, разбросанных по всему миру. Кстати, крупнейший в России дата-центр расположен в городе Сасово Рязанской области и принадлежит компании Яндекс.
Пользователь скорее всего не знает, куда географически направляется сигнал из его компьютера
Человек, заходящий на какой-то сайт, скорее всего он не знает, куда географически направляется сигнал из его компьютера. Но это важно для операторов, которые предоставляют услуги связи. Ведь чем короче маршрут, тем меньше нагружаются каналы связи, а значит, больше людей смогут одновременно быстро получить доступ к нужной им информации.
Например, чтобы зайти на какой-нибудь американский сайт, сигнал от компьютера идет через рязанского провайдера в Москву. Оттуда, скорее всего, куда-нибудь в Стокгольм, из Стокгольма в Амстердам, потом в Лондон, оттуда по трансатлантическому кабелю в Нью-Йорк, оттуда, например, в Лос-Анджелес и в итоге окажется, к примеру, в Сан-Франциско, где находится дата-центр, в котором живет нужный сайт.
Такой маршрут очень длинный, запутанный, и может вызывать достаточные временные задержки даже несмотря на то, что по оптоволоконному кабелю информация движется буквально со скоростью света. Поэтому компании стремятся хранить сайты поближе к своей целевой аудитории.
Компании стремятся хранить сайты поближе к своей целевой аудитории
Однако совсем не обязательно каждый раз ходить за одним и тем же файлом, например, видеороликом на Youtube, в Америку. Для этого компании используют так называемые кэшируюшие серверы, располагая их в каждом городе.
«Например, Google разместил кэширующий сервер в нашем дата-центре», — улыбается Михаил Ростов, — «и рязанский пользователь, открывший видеоролик, первый раз качает его с серверов в Америке, а кэширующий сервер тут же загружает этот ролик к нам. И следующий пользователь, который пойдет за этим роликом, будет грузить его уже отсюда, с рязанского дата-центра. Можно сказать, что у нас тут живет кусочек «Гугла».
А как же пользователи находят нужный файл в информации, хранящейся по всему миру? Один только Google обрабатывает десятки тысяч запросов каждую секунду.
Интернет можно сравнить с огромной библиотекой, имеющей очень подробный каталог
Интернет можно сравнить с огромной библиотекой, имеющей очень подробный каталог, в котором расписано все, что размещено в сети. А также точное указание места, где находится каждый элемент: слово, картинка или видеофайл. Все запросы в поисковой системе проверяются по этому «содержанию».
История создания интернета. Откуда берется интернет?
Современные технологии поражают нас и с каждым днем всё больше. Некоторые люди интересуются, как изобрели то, или иное устройство, откуда поступают различные сигналы и с чего начался интернет.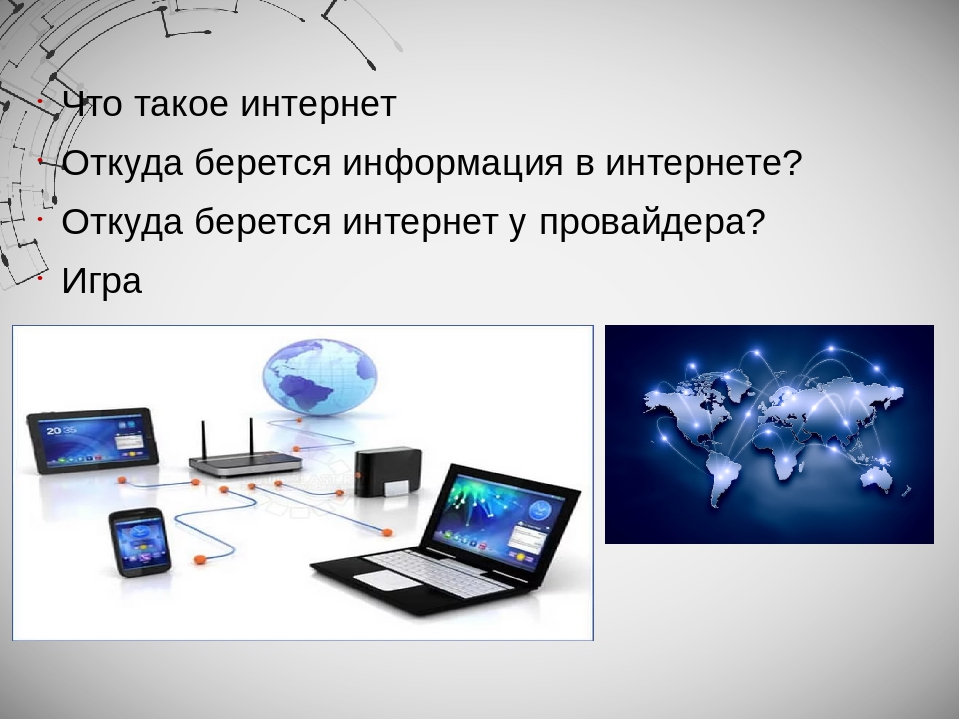
По всемирной паутине задается больше всего вопросов и это не удивительно, ведь данная технология буквально взорвала мир.
Откуда берется интернет? Серьезный вопрос, на который есть простой ответ. Интернет не является каким-то объектом, он как сотовая связь, распространен по всему миру.
Для его функционирования установлено несколько дата-центров в различных точках земного шара, а от них тянутся оптоволоконные сети к провайдерам и всевозможным распределителям.
История создания интернета
Если не вдаваться в подробности и сложные термины (в которых вы вряд ли что-то понимаете), то первый предшественник интернета появился в далеком 1961 году.
Тогда министерство обороны США начала разработку технологий для передачи данных между компьютерами. Ученые пытались передавать информацию между двумя машинами и, через несколько лет им удалось наладить систему.
Тогда проект назывался ARPANET и только в 1972 году придумали протоколы TCP/IP, которые используются, по сей день.
В 1973 году начали проводить международные сети (в Англии и Норвегии), это был новый уровень. До 1984 года проводились различные доработки и управление сетями передавалось от рук одних компаний в руки других.
В то время к сети было подключено уже около 1000 хостов. В 1989 году, к сети подключилось свыше 100 000 хостов, а Россия попала в список подключенных стран в следующем году.
Потом ARPANET прекратила свое существование, но Internet был уже весьма распространен и объединял огромное количество сетей по всему миру. В 1994 году на просторах интернета уже начались торговые операции, а также первые хакерские атаки.
Ещё через год сеть насчитывала 6 млн. серверов (оборудованные точки хранения информации, на которых хранятся данные). Сейчас их количество в несколько раз больше, а каждый желающий может превратить собственный компьютер в сервер.
Проще говоря, сделать домашний мини дата центр, с которого люди смогут что-то скачивать или на котором можно установить сайты.
Откуда берется интернет у провайдера?
Чтобы подключиться к интернету, нужно найти компанию, предоставляющие такие услуги. В каждом городе их несколько, поэтому клиенты могут выбирать подходящие по скорости и цене услуги.
Провайдер не просто перепродает интернет, он получает его по оптоволоконным сетям, а также использует сложные устройства, которые распределяют скорость между клиентами.
Если вы подключены к кабельному интернету, возможно, у вас есть доступ к внутренней сети (когда можно скачивать что-то с компьютеров других пользователей, подключенных к вашему провайдеру).
У каждого провайдера своя сеть из клиентов, поэтому между ними обеспечивается быстрая передача данных.
Для обеспечения доступа ко всемирной паутине, провайдеры закупают дорогое оборудование и потом тянут провода до квартир клиентов. Они используют собственные сервера, подключенные к интернету.
Аналогично всё работает и у тех провайдеров, которые предлагают беспроводной интернет. У них тоже установлены сервера, но вместо протягивания кабеля, они устанавливают мощные антенты.
У них тоже установлены сервера, но вместо протягивания кабеля, они устанавливают мощные антенты.
Данные перемещаются по оптоволоконной сети с огромной скоростью. Когда вы нажимаете «Отправить письмо», оно превращается в специальные данные за счет сетевой карты.
Потом эти данные «улетают» получателю по проводам (или через антенну), опять же обрабатываются сетевой картой, и он может прочитать ваше письмо. В этом не просто разобраться, поэтому специально для новичков мы пытаемся всё объяснить на пальцах.
Откуда берется информация в интернете?
Когда нужно что-то узнать, современные люди открывают поисковик и вводят запрос. Откуда в них появилось столько информации? Её создали другие люди. Смотрите, я создал свой сайт и написал эту статью. Разместил её на своем сайте, и теперь вы её читаете. Точно также наполняются и другие ресурсы.
Всё, что можно прочитать и найти в сети, было написано, записано, создано людьми. За годы развития всемирной паутины она активно наполнялась и теперь в ней можно найти ответ, практически на любой вопрос.
Где это всё хранится? Чтобы создать сайт, я использую услуги хостинг провайдера. Также как и провайдер интернета, эта компания закупила мощное оборудование, на котором можно размещать информацию, чтобы она была открыта для пользователей интернета.
Если объяснять совсем по простому – это мощнейший компьютер, на котором хранятся тексты, фон сайта, его дизайн, меню, настройки и многое другое. Каждый раз, когда вы заходите на мой сайт, ваш компьютер подключается к серверу.
Откуда берутся деньги в интернете?
Ещё один интересный вопрос, ответ на него простой, вы просто не задумывались об этом. Изначально в сети начали появляться деньги за счет рекламы.
Люди начали заказывать рекламу и делать денежные переводы, используя реальные деньги. Платежные системы появились быстро, всем известная компания Webmoney работает с 1998 года. Через неё и не только, проводились транзакции.
Сейчас в сети крутятся огромные деньги, и их резерв пополняется серьезными темпами. Люди оплачивают товары, погашают кредиты, переводят средства друг другу, платят за телефон и так далее. Всё это пополняет резервы виртуальной валюты.
Люди оплачивают товары, погашают кредиты, переводят средства друг другу, платят за телефон и так далее. Всё это пополняет резервы виртуальной валюты.
Хотите откусить часть этого денежного пирога? Нет проблем, узнайте, как заработать и начинайте прямо сейчас.
Подводя итоги этой статьи, хотелось бы расставить точки над i. И коротко ответить на главные вопросы:
- Откуда берется интернет? От серверов – специального оборудования, хранящего огромные объемы информации и работающих без остановки.
- Как работают провайдеры? Они закупают оборудование и подключают его ко всемирной сети через оптоволоконные сети, распределяя ресурсы между клиентами.
- Откуда берется информация и деньги в интернете? Их в мировую паутину добавляют сами люди. Кто-то записывает ролики, кто-то пишет, кто-то рисует, всё это загружается на сервера, к которым подключена общая сеть.
Теперь вы узнали немного больше о том, как работает интернет, с чего всё начиналось и откуда он берется. Хорошая пища для мозга, а если хотите стать умнее и почитать другую полезную информацию, используйте лучшие сайты для саморазвития.
Хорошая пища для мозга, а если хотите стать умнее и почитать другую полезную информацию, используйте лучшие сайты для саморазвития.
Вам также будет интересно:
— Что можно продать, чтобы заработать в интернете?
— Подготовка к работе в интернете
— Почему люди мало зарабатывают в интернете?
Откуда берется интернет? | VOXPOPULI
Интернет – технология, соединяющая миллионы людей во всем мире и дающая доступ к миллиардам терабайт данных. Он давно стал частью нашей жизни. Многие пользователи не знают, какой путь проходит информация перед тем, как попасть на компьютер. Vox Populi посетил центр мониторинга компании Beeline и ознакомился с тем, как контролируется работа сети проводного интернета по всему Казахстану.
Экран, установленный в Центре мониторинга Beeline Казахстан, показывает в режиме реального времени работу всех телекоммуникационных сетей – от границы Казахстана до городских коммуникаций.
О том, какой путь проходят данные, прежде чем появиться на компьютере пользователя, нам рассказал Технический директор компании ТОО «2Day Telecom» Нурлан Сарсебеков:
— Информация, которую мы просматриваем в интернете, зачастую находится на серверах или компьютерах, находящихся за тысячи километров от нас. Мы читаем новости, не задумываясь о том, что электронный сигнал, доставляющий нам информацию, проходит долгий путь. Прежде чем сигнал попадет в компьютер или планшет, он обрабатывается десятками единиц телекоммуникационного оборудования. Сигнал, переходя из одной физической среды в другую, может неоднократно подвергаться трансформации.
Мы читаем новости, не задумываясь о том, что электронный сигнал, доставляющий нам информацию, проходит долгий путь. Прежде чем сигнал попадет в компьютер или планшет, он обрабатывается десятками единиц телекоммуникационного оборудования. Сигнал, переходя из одной физической среды в другую, может неоднократно подвергаться трансформации.
В тот момент, когда мы подключаемся к сети, происходит соединение нашего модема с модемом провайдера. После этого компьютер связывается с маршрутизатором – устройством, пересылающим пакеты данных между различными сегментами сети. Маршрутизатор отправляет имя и пароль пользователя на сервер. После успешной авторизации маршрутизатор договаривается с компьютером о протоколе, с помощью которого система будет общаться с другими устройствами в интернете. Провайдер присваивает пользователю IP-адрес, на который будет отправляться вся запрашиваемая информация.
Когда мы вводим в строке браузера адрес сайта, мы обращаемся к веб-серверу, на котором расположен данный сайт. На этом этапе нам необходима помощь DNS-сервера. Дело в том, что привычные для нас имена сайтов используются только людьми. Компьютер же распознает только IP-адреса, состоящие из четырех групп чисел, разделенных точками. Например, адрес www.google.com соответствует IP-адресу 64.233.164.147. DNS-сервер помогает преобразовывать доменные имена в IP-адреса. Веб-серверы отсылают нам информацию в виде HTML-страниц, изображений, медиа-потоков, файлов и т.д
На этом этапе нам необходима помощь DNS-сервера. Дело в том, что привычные для нас имена сайтов используются только людьми. Компьютер же распознает только IP-адреса, состоящие из четырех групп чисел, разделенных точками. Например, адрес www.google.com соответствует IP-адресу 64.233.164.147. DNS-сервер помогает преобразовывать доменные имена в IP-адреса. Веб-серверы отсылают нам информацию в виде HTML-страниц, изображений, медиа-потоков, файлов и т.д
Физической средой для передачи информации могут быть волоконные линии связи, спутниковые системы, радиорелейные линии. В данный момент наиболее распространены волоконно-оптические линии. По словам Нурлана Сарсебекова, оптоволокно обладает рядом преимуществ. Основное достоинство волоконных линий – высокая пропускная способность, позволяющая передавать информацию на скорости, недостижимой для других систем связи. Кроме того, такая среда считается более надежной – оптические волокна, в отличие от медных проводов, не окисляются и не подвержены слабому электромагнитному воздействию. Эти системы отличаются высоким уровнем информационной безопасности – съем или искажение информации в такой среде сложно организовать и практически невозможно сделать это без прямого физического вмешательства.
Эти системы отличаются высоким уровнем информационной безопасности – съем или искажение информации в такой среде сложно организовать и практически невозможно сделать это без прямого физического вмешательства.
Есть у волоконных сетей и свои недостатки – высокая стоимость организации линий связи и немалые эксплуатационные издержки.
Оптоволоконные кабели тянутся на тысячи километров по дну морей и океанов, соединяя континенты и страны. Этими линиями владеют транснациональные провайдеры первого уровня (компании UUNET, AT&T, MCI, GTE/BBN, Sprint), продающие свои услуги международным и национальным провайдерам.
На корпоративном рынке услуг связи Казахстана, мобильные услуги и интернет предоставляются под брендом Beeline Business. Интернет закупается напрямую у международных операторов связи (таких, как VimpelCom). Общая пропускная емкость этих стыков составляет 150 гбит/сек. В случае неисправности одного из них, сеть автоматически переключится на другой. Для того, чтобы подстраховать услугу на стороне клиента, Beeline Business запустил первый в корпоративном сегменте Казахстана продукт, объединивший фиксированную и мобильную связь. Сервис «Резервирование офисного интернета через 3G канал» дает гарантию доступа в интернет на постоянной основе благодаря объединению двух независимых технологий доступа: проводной и беспроводной. В случае прерывании интернета по проводному каналу происходит автоматическое переключение на резервный 3G канал.
Сервис «Резервирование офисного интернета через 3G канал» дает гарантию доступа в интернет на постоянной основе благодаря объединению двух независимых технологий доступа: проводной и беспроводной. В случае прерывании интернета по проводному каналу происходит автоматическое переключение на резервный 3G канал.
Магистральная волоконно-оптическая сеть компании объединяет все регионы РК в рамках единой телекоммуникационной инфраструктуры. Общая протяженность магистрали 12300 км. И из одного конца Казахстана до другого сигнал доходит за десятые доли секунды.
Чтобы отслеживать работу такой обширной сети, а также следить за исправностью каналов телефонной связи, в 2008 году был открыт Центр мониторинга и управления. На момент запуска он был первой и единственной структурой подобного рода в республике.
Операторы центра круглосуточно следят за состоянием телекоммуникационной сети и качеством предоставляемых услуг. Для того, чтобы операторы могли локализовать неисправность при ее появлении, информация о работе всего оборудования собирается в одном месте. С помощью такой системы мониторинга работники компании могут быстро реагировать на любые аварийные ситуации.
С помощью такой системы мониторинга работники компании могут быстро реагировать на любые аварийные ситуации.
Чаще всего причиной аварийных инцидентов становятся отключения электроэнергии, тяжелые погодные условия, вредительство, сбои в системе. Однако лишь небольшая часть аварийных ситуаций приводит к реальным сбоям сети у пользователей. В случае сбоя или проблем в работе одной системы происходит автоматическое переключение на другую.
Независимо от того, привел ли аварийный случай к сбою в сети или нет, операторы Центра управления немедленно начинают работу по устранению неполадок. Для каждой аварийной ситуации разработан четкий алгоритм действий. Сначала локализуется место аварии и определяется ее причина. Затем оператор начинает работу по устранению или минимизации последствий, координируя работу технической группы на выезде.
Все аварийные ситуации классифицируются по приоритетам важности. При приоритете первой степени неисправность должна быть ликвидирована в течение четырех часов. Максимальное время устранения последствий любой поломки – двенадцать часов с момента оповещения об аварии, независимо от того, где установлено оборудование. Устранением неполадок занимаются группы полевых инженеров, имеющиеся в каждом крупном населенном пункте страны.
Максимальное время устранения последствий любой поломки – двенадцать часов с момента оповещения об аварии, независимо от того, где установлено оборудование. Устранением неполадок занимаются группы полевых инженеров, имеющиеся в каждом крупном населенном пункте страны.
Максат Алибаев уже шесть лет работает в Центре мониторинга и управления. В данный момент он является главным оперативным дежурным смены:
– Как и во всякой другой работе, у нас бывают авралы. Главное в такой ситуации – правильно распределить задачи между сменными сотрудниками, полевыми инженерами. Именно это и входит в мои обязанности. Я, как главный дежурный, собираю данные со всех участков, закрепленных за каждым отдельным сотрудником.
Главным предметом гордости работников центра мониторинга является высокая надежность сети – 99,96%. Добившись такого показателя, Beeline стремится постоянно расширять покрытие. В этом году к быстрому проводному интернету были подключены Рудный, Хромтау, Абай и Балхаш.
– Мы стремимся к тому, чтобы каждый пользователь имел возможность получить интересующую его информацию из любой точки мира за доли секунды. Надежность, качество, конкурентная цена – вот наши главные стратегические задачи, – добавляет Нурлан Сарсебеков.
Откуда берется интернет в России и в мире?
Следите за нашими обновлениями ВКонтакте, чтобы читать статьи одними из первых.
По проводам и магистралям: откуда берется интернет в России
Откуда берется интернет? Что собой представляет? Люди пользуются сетевыми ресурсами ежедневно. Одни загружают фотографии в соц. сетях, другие переписываются в чатах и мессенджерах, третьи скачивают программы с сайтов или же часами «зависают» в онлайн-играх. Но как все это работает, и можно ли отключить интернет всем сразу? Давайте разбираться.
С чего все начинается
Во многих информационных источниках интернет называют «виртуальной мировой паутиной», и, надо сказать, такое сравнение ему более чем подходит. Ведь любая сеть (не важно, на уровне небольшого офиса или всего мира) – это переплетение множества оптоволоконных кабелей, на концах которых находятся серверы, коммутаторы и пользовательское оборудование.
Ведь любая сеть (не важно, на уровне небольшого офиса или всего мира) – это переплетение множества оптоволоконных кабелей, на концах которых находятся серверы, коммутаторы и пользовательское оборудование.
Чтобы было понятнее, рассмотрим этот процесс на примере:
Двое людей, живущих по соседству, хотят быстро обмениваться друг с другом текстовыми сообщениями, музыкой, фотографиями и прочими медиа-файлами. Для этого они объединяют свои компьютеры в единую сеть при помощи коммутатора и патч-кордов. Затем к ним таким же способом подключается третий сосед, четвертый, пятый десятый. Чтобы выйти за пределы дома. Провода протягиваются к другим жилым постройкам, где к сети присоединяются новые участники. И так, шаг за шагом, виртуальная паутина разрастается в масштабах. Начавшаяся с одного этажа она выходит на уровень подъезда, дома, страны, а затем и всего земного шара. И вот мы уже имеем всемирную сеть, которая непрерывно объединяет миллиарды устройств.
А как же беспроводной интернет, спросите вы. Само его название уже подразумевает отсутствие каких-либо проводов. Однако это утверждение не совсем корректно. Да, конечный потребитель получает сигнал по радиоканалам, которые принимает роутер. Но оборудование, которое транслирует эти самые сигналы, должно быть включено в единую сеть, иначе доступа в интернет вы не получите.
Само его название уже подразумевает отсутствие каких-либо проводов. Однако это утверждение не совсем корректно. Да, конечный потребитель получает сигнал по радиоканалам, которые принимает роутер. Но оборудование, которое транслирует эти самые сигналы, должно быть включено в единую сеть, иначе доступа в интернет вы не получите.
Кто платит за интернет и кому
Конечный потребитель ежемесячно платит своему провайдеру за определенные объемы выкачиваемого трафика. Но откуда берется интернет у самих провайдеров? Ответ прост, городские провайдеры закупают его у региональных, те – у федеральных, и так далее по цепочке. Во главе же этой пирамиды стоят 11 транснациональных корпораций, которые владеют абсолютным большинством подводных кабелей и магистралей, проложенных между континентами. Между собой они обмениваются трафиком бесплатно, а более мелким игрокам информационного рынка продают его по оговоренной цене. Если глобальные игроки того пожелают, люди по всей планете (или в конкретно взятой стране) могут остаться без интернета за секунды. Но поскольку бизнес этот сверхприбылен, риски подобного развития событий ничтожны.
Но поскольку бизнес этот сверхприбылен, риски подобного развития событий ничтожны.
Это интересно: лимитный безлимит
Сегодня большинство интернет-провайдеров заманивает клиентов безлимитными тарифами. И действительно, возможность выкачивать любые объемы данных за фиксированную цену выглядит весьма заманчиво. Однако не все так просто, ведь зафиксирована не только цена услуги, но и скорость подключения. Иначе говоря, если мы возьмем для примера скорость 100 Мбит/сек, то, условно, платя 10 р в день за безлимит, вы, по факту, платите за 8640000 Мбит (т.к. в сутках 86400 секунды). Больший объем вы за это время вы выкачать не сможете. Однако большинство даже половины из этого не тратят, в итоге переплачивая за «воздух».
Как в интернете заводятся сайты
Если интернет – это множество компьютеров, соединенные между собой проводами, то, что же такое сайты? И где они находятся. Если говорить по-простому, сайт – это веб-страница или несколько связанных между собой страниц. Желая избежать проблем с нехваткой места или потерей соединения, многие владельцы сайтов за плату размещают свои ресурсы на рабочих машинах хостеров. Те же, в свою очередь, присваивают страницам индивидуальный IP-адрес, по которому их в дальнейшем будет искать DNS-сервер.
Желая избежать проблем с нехваткой места или потерей соединения, многие владельцы сайтов за плату размещают свои ресурсы на рабочих машинах хостеров. Те же, в свою очередь, присваивают страницам индивидуальный IP-адрес, по которому их в дальнейшем будет искать DNS-сервер.
Чтобы перейти по ссылке, компьютер пользователя путешествует через целую сеть коммутаторов. Когда же требуемый IP-адрес будет найден, сервер хостера сгенерирует html-код, расшифровывать который предстоит уже вашему браузеру.
Получается, что:
- Хотите пользоваться чужими благами (покупать товары, читать новости), достаточно будет оплатить трафик (доступ ко всем, представленным в сети, сайтам).
- Хотите продавать, информировать или продвигать какие-то свои наработки, придется арендовать у хостера место под «виртуальный домик» (сайт, на котором будет размещена необходимая информация и медиа-материалы).
Для того, чтобы подключить интернет в офис оставьте заявку на нашем сайте.
Остались вопросы? Есть что добавить? Ждем ваши комментарии.
Google Chrome – Политика конфиденциальности
Последнее обновление: 15 января 2021 г.
Предыдущие версии: Выберите дату20 мая 2020 г.17 марта 2020 г.10 декабря 2019 г.31 октября 2019 г.12 марта 2019 г.30 января 2019 г.4 декабря 2018 г.24 октября 2018 г.24 сентября 2018 г.6 марта 2018 г.25 апреля 2017 г.7 марта 2017 г.24 января 2017 г.30 ноября 2016 г.11 октября 2016 г.30 августа 2016 г.21 июня 2016 г.1 сентября 2015 г.12 ноября 2014 г.26 августа 2014 г.20 мая 2014 г.20 февраля 2014 г.
Здесь рассказано, как управлять данными, которые получает, хранит и использует Google, когда Вы работаете в браузере Google Chrome на компьютере или мобильном устройстве, в Chrome OS или в режиме Безопасного просмотра. Хотя перечисленные ниже правила относятся к браузеру Chrome, вся личная информация, которую Вы предоставляете Google или храните в аккаунте, обрабатывается строго в соответствии с Политикой конфиденциальности Google, которая иногда меняется. Информацию о хранении данных в Google можно посмотреть в соответствующей политике.
Информацию о хранении данных в Google можно посмотреть в соответствующей политике.
Если на Вашем устройстве Chromebook можно устанавливать приложения из Google Play, использование и защита Ваших данных, собираемых сервисом Google Play или системой Android, регулируется Условиями использования Google Play и Политикой конфиденциальности Google. В этом Примечании Вы найдете дополнительные правила, касающиеся Google Chrome.
О Примечании
В этом Примечании для удобства мы будем использовать термин «Chrome» в отношении всего ряда продуктов линейки Chrome, указанных выше. Если правила для разных продуктов отличаются, это будет оговорено отдельно. Иногда положения Примечания меняются.
Версии «Chrome (бета)», «Chrome для разработчиков» и Chrome Canary позволяют тестировать новые функции браузера, которые ещё не были выпущены официально. Настоящее Примечание относится ко всем версиям Chrome, но может не учитывать функции, находящиеся в разработке.
Подробнее о том, как изменить настройки конфиденциальности в Chrome…
Содержание
Режимы браузера
Начать использовать Chrome можно без предоставления какой-либо личной информации. Тем не менее в некоторых режимах браузер может собирать данные о Вас для Вашего удобства. Меры по обеспечению конфиденциальности зависят от выбранного режима.
Тем не менее в некоторых режимах браузер может собирать данные о Вас для Вашего удобства. Меры по обеспечению конфиденциальности зависят от выбранного режима.
Основной режим браузера
При работе браузера в основном режиме на Вашем компьютере сохраняется информация, в том числе:
История просмотра сайтов. Chrome сохраняет URL посещенных страниц, файлы кеша с текстом, картинками и другим контентом со страниц, а также список IP-адресов некоторых ресурсов, на которые размещены ссылки на посещенных страницах (если включена предварительная визуализация).
Персональные данные и пароли для быстрого заполнения форм и входа на сайты, где Вы уже бывали раньше.
Список разрешений, предоставленных веб-сайтам.
Файлы cookie или другие данные с посещенных вами веб-сайтов.
Данные, сохраненные дополнениями.
Информация о скачиваниях с веб-сайтов.
Вы можете:
Личная информация из Chrome отправляется в Google только в том случае, если вы решили хранить ее в аккаунте Google, включив синхронизацию. Платежные данные, карты и пароли передаются, только если вы сохранили их в аккаунте Google. Подробнее…
Платежные данные, карты и пароли передаются, только если вы сохранили их в аккаунте Google. Подробнее…
Как Chrome обрабатывает Вашу информацию
Информация для владельцев сайтов. Сайты, которые Вы открываете с помощью Chrome, автоматически получают стандартные данные журналов, включая Ваш IP-адрес и данные из файлов cookie. Используя Chrome для работы с сервисами Google (например, Gmail), Вы не предоставляете компании Google какой-либо дополнительной информации о себе. Если в Chrome будет автоматически обнаружено, что пользователь сервиса Google или партнерского сайта стал жертвой сетевой атаки типа «человек посередине», то данные об этом могут быть направлены в Google или на тот ресурс, где произошла атака. Это нужно, чтобы определить ее серьезность и принцип организации. Владельцы сайтов, сотрудничающие с Google, получают отчеты об атаках, которые были произведены на их ресурсах.
Предварительная визуализация. Чтобы быстрее загружать веб-страницы, Chrome может искать IP-адреса ссылок, размещенных на текущей странице, и создавать сетевые подключения. Сайты и приложения Android также иногда запрашивают у браузера предварительную загрузку веб-страниц, на которые Вы можете перейти дальше. Запросы от веб-сайтов выполняются всегда и не зависят от системы подсказок Chrome. Если от браузера Chrome, веб-сайта или приложения поступил запрос на предварительную визуализацию страницы, она будет сохранять и считывать файлы cookie, как будто ее уже посетили (даже если этого не произойдет). Подробнее…
Сайты и приложения Android также иногда запрашивают у браузера предварительную загрузку веб-страниц, на которые Вы можете перейти дальше. Запросы от веб-сайтов выполняются всегда и не зависят от системы подсказок Chrome. Если от браузера Chrome, веб-сайта или приложения поступил запрос на предварительную визуализацию страницы, она будет сохранять и считывать файлы cookie, как будто ее уже посетили (даже если этого не произойдет). Подробнее…
Местоположение. Чтобы предоставить Вам наиболее подходящую информацию, некоторые сайты могут запрашивать данные о Вашем местоположении. Chrome предупреждает об этом и предоставляет такие данные только с Вашего разрешения. Однако на мобильных устройствах браузер Chrome автоматически передает их поисковой системе по умолчанию, если Вы открыли доступ к своим геоданным мобильному приложению Chrome и не блокировали передачу этих данных для конкретного сайта. Для определения Вашего местоположения Chrome использует геолокацию Google и может передавать ей следующую информацию:
- список маршрутизаторов Wi-Fi поблизости;
- идентификаторы базовых станций сотовой связи поблизости;
- данные о мощности сигнала Wi-Fi или сотовой связи;
- текущий IP-адрес Вашего мобильного устройства.


Google не несет ответственности за сторонние веб-сайты и их меры по обеспечению конфиденциальности. Будьте внимательны, предоставляя им информацию о своем местоположении.
Обновления. Chrome иногда отправляет в Google запросы, чтобы проверить обновления, определить статус соединения, синхронизировать настройки времени и узнать количество активных пользователей.
Функции поиска. Если Вы вошли в аккаунт на сайте Google и используете поисковую систему Google по умолчанию, запросы через омнибокс или окно поиска на странице быстрого доступа в Chrome будут сохраняться в аккаунте Google.
Поисковые подсказки. Чтобы Вы могли искать информацию быстрее, Chrome предлагает варианты запросов. Для этого он отправляет символы, которые Вы вводите в омнибокс или окно поиска на странице быстрого доступа, в Вашу поисковую систему по умолчанию (даже если Вы ещё не нажали клавишу «Ввод»). Если Вы выбрали Google в качестве поисковой системы по умолчанию, она предлагает подсказки на основе Вашей истории поиска, запросов других людей, а также тем, связанных с Вашими запросами в омнибоксе и окне поиска на странице быстрого доступа. О том, как ускорить поиск в Google, рассказано в этой статье. Подсказки также могут быть основаны на истории браузера. Подробнее…
О том, как ускорить поиск в Google, рассказано в этой статье. Подсказки также могут быть основаны на истории браузера. Подробнее…
Похожие страницы. Если Вы не сможете открыть нужную веб-страницу, Chrome отправит ее адрес в Google и предложит похожие сайты.
Автозаполнение, платежи и управление паролями. Когда включено автозаполнение или управление паролями, Chrome отправляет в Google анонимную информацию о веб-формах, которые вы открываете или отправляете (в том числе хешированный URL веб-страницы и данные о полях для ввода). Эти сведения позволяют нам улучшать сервисы автозаполнения и управления паролями. Подробнее…
Если вы вошли в Chrome, используя аккаунт Google, то можете увидеть предложение сохранить в аккаунте пароли, способы оплаты и другую подобную информацию. Кроме того, Chrome может подставлять в веб-формы пароли и способы оплаты из аккаунта Google. Если пароли и другие данные сохранены только в Chrome, вы увидите предложение сохранить их в аккаунте Google. Если вы используете способ оплаты из аккаунта Google или сохраняете такой способ оплаты в нем на будущее, Chrome будет собирать информацию о вашем компьютере и передавать ее в Google Pay для защиты от мошеннических операций и в целях предоставления сервиса. Вы также сможете оплачивать покупки через Chrome с помощью Google Pay, если эта функция поддерживается продавцом.
Если вы используете способ оплаты из аккаунта Google или сохраняете такой способ оплаты в нем на будущее, Chrome будет собирать информацию о вашем компьютере и передавать ее в Google Pay для защиты от мошеннических операций и в целях предоставления сервиса. Вы также сможете оплачивать покупки через Chrome с помощью Google Pay, если эта функция поддерживается продавцом.
Язык. Chrome запоминает язык сайтов, которые Вы посещаете чаще всего, и отправляет эти данные в Google, чтобы сделать использование браузера более удобным для Вас. Если Вы включили синхронизацию Chrome, языковой профиль будет связан с Вашим аккаунтом Google. Если Вы добавили историю Chrome в историю приложений и веб-поиска, информация о языке может использоваться для персонализации других сервисов Google. Отслеживание действий можно настроить здесь.
Веб-приложения для Android. Если Вы добавите на главный экран устройства Android сайт, оптимизированный для быстрой и надежной работы на мобильных устройствах, Chrome свяжется с серверами Google и создаст на Вашем устройстве оригинальный пакет приложения. Благодаря ему Вы сможете использовать веб-приложение как обычное приложение для Android. Например, веб-приложение появится в списке приложений, установленных на устройстве. Подробнее…
Благодаря ему Вы сможете использовать веб-приложение как обычное приложение для Android. Например, веб-приложение появится в списке приложений, установленных на устройстве. Подробнее…
Статистика использования и отчеты о сбоях. По умолчанию эти данные отправляются в Google, чтобы с их помощью мы могли улучшать свои продукты. Статистика использования содержит информацию о настройках, нажатиях кнопок и задействованных ресурсах памяти. Как правило, в статистику не входят URL веб-страниц и личная информация. Однако, если Вы включили функцию «Помогать улучшить просмотр страниц и поиск» или «Отправлять URL посещенных страниц в Google», в статистике будут данные о том, какие страницы Вы открывали и как их использовали. Если у Вас включена синхронизация Chrome, то данные о поле и возрасте, указанные в Вашем аккаунте Google, могут использоваться вместе с нашей статистикой. Это позволяет нам создавать продукты для всех групп населения. К примеру, мы можем собирать статистику, чтобы определять страницы, которые загружаются медленно. Мы используем эту информацию, чтобы совершенствовать свои продукты и сервисы, а также помогать разработчикам в улучшении их сайтов. Отчеты о сбоях содержат системную информацию на момент сбоя, а также могут включать URL веб-страниц и личные данные (в зависимости от того, как использовался браузер). Мы можем передавать партнерам (например, издателям, рекламодателям и разработчикам) обобщенную информацию, по которой нельзя установить личность пользователя. Вы можете в любой момент запретить или снова разрешить Chrome отправлять в Google статистику и отчеты. Если Вы используете приложения из Google Play на устройстве Chromebook и разрешили Chrome отправлять статистику, в Google также будут передаваться данные диагностики и сведения об использовании Android.
Мы используем эту информацию, чтобы совершенствовать свои продукты и сервисы, а также помогать разработчикам в улучшении их сайтов. Отчеты о сбоях содержат системную информацию на момент сбоя, а также могут включать URL веб-страниц и личные данные (в зависимости от того, как использовался браузер). Мы можем передавать партнерам (например, издателям, рекламодателям и разработчикам) обобщенную информацию, по которой нельзя установить личность пользователя. Вы можете в любой момент запретить или снова разрешить Chrome отправлять в Google статистику и отчеты. Если Вы используете приложения из Google Play на устройстве Chromebook и разрешили Chrome отправлять статистику, в Google также будут передаваться данные диагностики и сведения об использовании Android.
Медиалицензии. Некоторые сайты шифруют медиаконтент, чтобы защитить его от несанкционированного доступа и копирования. Если сайт создан на HTML5, обмен выполняется с помощью Encrypted Media Extensions API. При этом на устройстве пользователя может сохраняться лицензия и идентификатор сеанса. Чтобы стереть их, воспользуйтесь инструментом Удаление данных о просмотренных страницах (установите флажок «Файлы cookie и другие данные сайтов»). Если на сайте используется Adobe Flash Access, Chrome предоставляет сайту или провайдеру контента уникальный идентификатор, который хранится в Вашей системе. Чтобы закрыть доступ к идентификатору, в меню Chrome выберите «Настройки > Дополнительные > Настройки контента > Защищенный контент» или воспользуйтесь инструментом Удаление данных о просмотренных страницах (установите флажок «Файлы cookie и другие данные сайтов»). Когда Вы хотите получить доступ к защищенному контенту в Chrome для Android, HD или офлайн-контенту в Chrome OS, поставщик контента может потребовать подтверждение, что устройство подходит для его воспроизведения. В таком случае Ваше устройство передаст сайту идентификатор, подтверждающий безопасность ключей шифрования. Подробнее…
Чтобы стереть их, воспользуйтесь инструментом Удаление данных о просмотренных страницах (установите флажок «Файлы cookie и другие данные сайтов»). Если на сайте используется Adobe Flash Access, Chrome предоставляет сайту или провайдеру контента уникальный идентификатор, который хранится в Вашей системе. Чтобы закрыть доступ к идентификатору, в меню Chrome выберите «Настройки > Дополнительные > Настройки контента > Защищенный контент» или воспользуйтесь инструментом Удаление данных о просмотренных страницах (установите флажок «Файлы cookie и другие данные сайтов»). Когда Вы хотите получить доступ к защищенному контенту в Chrome для Android, HD или офлайн-контенту в Chrome OS, поставщик контента может потребовать подтверждение, что устройство подходит для его воспроизведения. В таком случае Ваше устройство передаст сайту идентификатор, подтверждающий безопасность ключей шифрования. Подробнее…
Другие сервисы Google. В настоящем Примечании рассматриваются сервисы Google, которые включены в Chrome по умолчанию. Chrome может предлагать Вам воспользоваться и другими сервисами Google, например Google Переводчиком, если Вы открыли страницу на другом языке. При первом использовании этих сервисов появятся их настройки. Подробную информацию можно найти в Политике конфиденциальности Chrome.
Chrome может предлагать Вам воспользоваться и другими сервисами Google, например Google Переводчиком, если Вы открыли страницу на другом языке. При первом использовании этих сервисов появятся их настройки. Подробную информацию можно найти в Политике конфиденциальности Chrome.
Идентификаторы в Chrome
В Chrome используются различные уникальные и неуникальные идентификаторы, необходимые для правильной работы функций. Например, при push-рассылке браузеру присваивается идентификатор для корректной доставки уведомлений. Мы стараемся использовать неуникальные идентификаторы, а также своевременно удалять ненужные. Кроме того, есть несколько идентификаторов, которые нужны для улучшения и продвижения Chrome, но не связаны с пользовательскими функциями напрямую.
Отслеживание установок. Каждая копия Chrome для Windows содержит генерируемый случайным образом номер, который отправляется в Google при первом запуске, а затем удаляется при первом обновлении Chrome.
С помощью этого временного идентификатора мы оцениваем количество установок браузера. В мобильной версии Chrome вместо этого используется своеобразный идентификатор устройства, который также помогает нам узнать количество установок.Отслеживание промоакций. Для контроля эффективности промоакций Chrome генерирует уникальный токен, который отправляется в Google при первом запуске и использовании браузера. Если Вы скачали или повторно активировали браузер на компьютере в ходе рекламной кампании и выбрали Google в качестве поисковой системы по умолчанию, Chrome также отправляет в Google неуникальную промометку из запросов, которые Вы вводите в омнибоксе. Все запросы в омнибоксе мобильной версии Chrome также содержат неуникальную промометку. То же самое могут делать устройства с Chrome OS (например, во время первой установки и при отправке поисковых запросов). Подробнее…
Тестирование. Иногда мы организуем закрытые тесты новых функций.
При первом запуске браузеру присваивается случайный идентификатор, который нужен для выбора фокус-групп. Тестирование может быть ограничено страной (определяется по IP-адресу), операционной системой, версией Chrome и другими параметрами. Список тестовых функций, которые сейчас активны в Вашем браузере Chrome, прилагается ко всем запросам, которые отправляются в Google. Подробнее…
 С помощью этого временного идентификатора мы оцениваем количество установок браузера. В мобильной версии Chrome вместо этого используется своеобразный идентификатор устройства, который также помогает нам узнать количество установок.
С помощью этого временного идентификатора мы оцениваем количество установок браузера. В мобильной версии Chrome вместо этого используется своеобразный идентификатор устройства, который также помогает нам узнать количество установок. При первом запуске браузеру присваивается случайный идентификатор, который нужен для выбора фокус-групп. Тестирование может быть ограничено страной (определяется по IP-адресу), операционной системой, версией Chrome и другими параметрами. Список тестовых функций, которые сейчас активны в Вашем браузере Chrome, прилагается ко всем запросам, которые отправляются в Google. Подробнее…
При первом запуске браузеру присваивается случайный идентификатор, который нужен для выбора фокус-групп. Тестирование может быть ограничено страной (определяется по IP-адресу), операционной системой, версией Chrome и другими параметрами. Список тестовых функций, которые сейчас активны в Вашем браузере Chrome, прилагается ко всем запросам, которые отправляются в Google. Подробнее…Режимы входа и синхронизации Chrome
Вы можете использовать браузер Chrome, в котором выполнен вход в аккаунт Google, независимо от того, включена ли синхронизация.
Вход в аккаунт. Если вы входите в любой сервис Google или выходите из него, пользуясь версией Chrome для ПК, вход в аккаунт Chrome или выход из него выполняется автоматически. Эту функцию можно отключить в настройках. Подробнее… Если вы входите в любой веб-сервис Google в версии Chrome для Android, то можете увидеть предложение войти с помощью аккаунтов Google, которые уже используются на этом устройстве. Эту функцию можно отключить в настройках. Подробнее… Если вы вошли в Chrome, используя аккаунт Google, то можете увидеть предложение сохранить в аккаунте пароли, способы оплаты и другую подобную информацию. В отношении этой персональной информации действует Политика конфиденциальности Google.
Эту функцию можно отключить в настройках. Подробнее… Если вы вошли в Chrome, используя аккаунт Google, то можете увидеть предложение сохранить в аккаунте пароли, способы оплаты и другую подобную информацию. В отношении этой персональной информации действует Политика конфиденциальности Google.
Синхронизация. Когда Вы входите в Chrome или в систему на устройстве Chromebook и включаете синхронизацию с аккаунтом Google, Ваша личная информация сохраняется в аккаунте на серверах Google. Это позволяет Вам получать доступ к своим данным с любого устройства, на котором Вы вошли в Chrome. В отношении персональной информации действует Политика конфиденциальности Google. Вот что может синхронизироваться:
- история посещения страниц;
- закладки;
- вкладки;
- пароли и параметры автозаполнения;
- другие настройки браузера, например установленные расширения.
Синхронизация будет работать, только если вы ее включите. Подробнее… В меню «Настройки» можно выбрать конкретную информацию, которая будет синхронизироваться. Подробнее… Для управления данными Chrome, которые хранятся в аккаунте Google, нужно перейти на эту страницу. Там же можно отключить синхронизацию и удалить все связанные с аккаунтом данные с серверов Google (если аккаунт не был создан через сервис Family Link). Подробнее… Вход в аккаунты Google, созданные с помощью Family Link, обязателен, и для них нельзя отключить синхронизацию, так как с ее помощью родители управляют устройствами детей, например доступом к определенным сайтам. Однако дети с управляемыми аккаунтами могут удалить свои данные и отключить синхронизацию для большинства типов данных. Подробнее… К данным, которые хранятся в таких аккаунтах, применяются положения Примечания о конфиденциальности данных в аккаунтах Google, созданных для детей младше 13 лет и управляемых с помощью Family Link.
Подробнее… Для управления данными Chrome, которые хранятся в аккаунте Google, нужно перейти на эту страницу. Там же можно отключить синхронизацию и удалить все связанные с аккаунтом данные с серверов Google (если аккаунт не был создан через сервис Family Link). Подробнее… Вход в аккаунты Google, созданные с помощью Family Link, обязателен, и для них нельзя отключить синхронизацию, так как с ее помощью родители управляют устройствами детей, например доступом к определенным сайтам. Однако дети с управляемыми аккаунтами могут удалить свои данные и отключить синхронизацию для большинства типов данных. Подробнее… К данным, которые хранятся в таких аккаунтах, применяются положения Примечания о конфиденциальности данных в аккаунтах Google, созданных для детей младше 13 лет и управляемых с помощью Family Link.
Как Chrome обрабатывает синхронизированную информацию
Когда включена синхронизация с аккаунтом Google, мы используем сохраненные данные, чтобы делать Вашу работу в браузере максимально комфортной. Чтобы Вам было удобнее пользоваться и другими нашими продуктами, Вы можете добавить историю Chrome в историю приложений и веб-поиска.
Чтобы Вам было удобнее пользоваться и другими нашими продуктами, Вы можете добавить историю Chrome в историю приложений и веб-поиска.
Вы можете изменить эту настройку на странице отслеживания действий, а также управлять личной информацией по своему усмотрению. Если Вы решили не использовать в других сервисах данные Chrome, они будут обрабатываться Google только в анонимном виде и после объединения их с данными других пользователей. Мы используем эти данные для создания и улучшения функций, продуктов и сервисов. Если Вы хотите использовать облако Google для хранения и синхронизации данных Chrome, но не желаете предоставлять Google доступ к ним, включите шифрование с помощью кодовой фразы. Подробнее…
Режим инкогнито и гостевой режим
Воспользуйтесь режимом инкогнито или гостевым режимом, чтобы ограничить объем информации, который Chrome хранит у Вас на компьютере. В этих режимах некоторая информация не сохраняется, например:
- основная информация об истории просмотра сайтов, включая URL, кешированный текст страниц и IP-адреса, связанные с посещенными вами веб-сайтами;
- уменьшенные изображения посещаемых вами сайтов;
- записи о скачивании файлов (при этом скачанные файлы будут храниться в указанной вами папке на компьютере или мобильном устройстве).

Как Chrome обрабатывает Вашу информацию в режиме инкогнито и гостевом режиме
Файлы cookie. Chrome не предоставляет сайтам доступ к файлам cookie, если Вы используете режим инкогнито или гостевой режим. При работе в этих режимах сайты могут сохранять в системе новые файлы cookie, но все они будут удалены, когда Вы закроете окно браузера.
Изменения конфигурации браузера. Когда Вы вносите изменения в конфигурацию браузера, например создаете закладку для веб-страницы или меняете настройки, эта информация сохраняется. В режиме инкогнито и в гостевом режиме такого не происходит.
Разрешения. Разрешения, которые Вы предоставляете в режиме инкогнито, не сохраняются в существующем профиле.
Информация из профиля. В режиме инкогнито у Вас есть доступ к информации из существующего профиля, например к подсказкам на базе истории посещения страниц и к сохраненным паролям. В гостевом режиме данные профилей не используются.
Управление пользователями Chrome
Управление пользователями в персональной версии Chrome
Вы можете создать в браузере Chrome отдельный профиль для каждого человека, который работает на компьютере или мобильном устройстве. При этом любой пользователь устройства будет иметь доступ ко всем сведениям всех профилей. Если Вы хотите защитить свою информацию, используйте разные аккаунты в операционной системе. Подробнее…
Управление пользователями в Chrome для организаций
Если браузер Chrome или устройство Chromebook контролируется компанией или учебным заведением, системный администратор может устанавливать для них правила. Когда пользователь в первый раз начинает работу в браузере (кроме гостевого режима), Chrome обращается к Google и получает нужные правила и в дальнейшем периодически проверяет их обновление.
Администратор может включить создание отчетов о статусе и активности Chrome, которые будут содержать данные о местоположении устройств с Chrome OS. Кроме того, администратор может иметь доступ к информации на управляемом устройстве, а также отслеживать и раскрывать ее.
Кроме того, администратор может иметь доступ к информации на управляемом устройстве, а также отслеживать и раскрывать ее.
Безопасный просмотр веб-страниц
Google Chrome и другие браузеры (включая некоторые версии Mozilla Firefox и Safari) поддерживают функцию Безопасного просмотра Google. При безопасном просмотре браузер получает от серверов Google информацию о подозрительных веб-сайтах.
Как работает функция Безопасного просмотра
Браузер периодически обращается к серверам Google для загрузки постоянно обновляемого списка сайтов, замеченных в фишинге и распространении вредоносного программного обеспечения. Текущая копия списка хранится в Вашей системе локально. При этом в Google не поступают ни сведения об аккаунте, ни другие идентификационные данные. Передается только стандартная информация журнала, включая IP-адрес и файлы cookie.
Каждый посещенный вами сайт сверяется с загруженным списком. При обнаружении соответствий браузер отправляет в Google хешированную частичную копию URL, чтобы получить дополнительную информацию. Определить настоящий URL на основе этой информации невозможно. Подробнее…
Определить настоящий URL на основе этой информации невозможно. Подробнее…
Ряд функций Безопасного просмотра работает только в Chrome:
Если Вы включили режим улучшенной защиты с помощью Безопасного просмотра, в Chrome используются дополнительные средства защиты. При этом в Google отправляется больше данных (см. настройки Chrome). Подробнее… Когда включен стандартный режим, некоторые средства защиты также могут быть доступны в качестве самостоятельных функций. Такие функции настраиваются индивидуально.
Если Вы включили Безопасный просмотр, а также параметр «Помогать улучшить просмотр страниц и поиск / Отправлять URL посещенных страниц в Google», Chrome отправляет в Google полный URL каждого открытого Вами сайта. Это помогает определить, безопасен ли ресурс. Если Вы также включили синхронизацию истории браузера без кодовой фразы, эти URL будут на время связаны с Вашим аккаунтом Google. Это обеспечит более персонализированную защиту. В режиме инкогнито и гостевом режиме эта функция не работает.
В некоторых версиях Chrome используется технология Безопасного просмотра, позволяющая определять потенциально опасные сайты и типы файлов, которых ещё нет в списках Google. Информация о них (включая полный URL сайта или загрузочный файл) может отправляться в Google на проверку.
Chrome использует технологию Безопасного просмотра и периодически сканирует Ваш компьютер, чтобы обнаружить нежелательное программное обеспечение. Такое ПО может мешать изменению настроек браузера или другим способом ухудшать его безопасность и стабильность. Обнаружив нежелательные программы, Chrome может предложить Вам скачать Инструмент очистки Chrome, чтобы удалить их.
Чтобы помочь нам усовершенствовать режим Безопасного просмотра, Вы можете настроить отправку дополнительных данных. Они будут передаваться при переходе на подозрительный сайт или при обнаружении нежелательного ПО на Вашем компьютере. Подробнее…
Если Вы пользуетесь Диспетчером паролей Chrome, то при вводе сохраненного пароля на странице, вызывающей подозрения, функция «Безопасный просмотр» проверяет эту страницу, чтобы защитить Вас от фишинговых атак.
При этом Chrome не отправляет Ваши пароли в Google. Кроме того, функция «Безопасный просмотр» защищает пароль Вашего аккаунта Google. Если Вы введете его на подозрительном сайте, то увидите предложение сменить пароль в аккаунте Google. Если история браузера синхронизируется или если Вы вошли в свой аккаунт и разрешили уведомлять Google, Chrome сделает отметку, что Ваш аккаунт Google мог подвергнуться фишинговой атаке.Google. Когда Вы входите на какой-нибудь сайт, Chrome передает в Google часть хеша Вашего имени пользователя и зашифрованную информацию о пароле, а Google возвращает список возможных совпадений из тех сведений, которые стали доступны посторонним в результате известных утечек. По списку Chrome определяет, были ли Ваши данные раскрыты. При этом имя пользователя и пароль, а также факт их утечки, не становятся известны Google. Эту функцию можно отключить в настройках Chrome. Подробнее…
Вы можете отключить функцию «Безопасный просмотр» в настройках Chrome на устройстве Android или компьютере.
В версии для iOS технология безопасного просмотра контролируется компанией Apple, которая может отправлять данные в другие компании, предоставляющие сервисы безопасного просмотра.

 При этом Chrome не отправляет Ваши пароли в Google. Кроме того, функция «Безопасный просмотр» защищает пароль Вашего аккаунта Google. Если Вы введете его на подозрительном сайте, то увидите предложение сменить пароль в аккаунте Google. Если история браузера синхронизируется или если Вы вошли в свой аккаунт и разрешили уведомлять Google, Chrome сделает отметку, что Ваш аккаунт Google мог подвергнуться фишинговой атаке.
При этом Chrome не отправляет Ваши пароли в Google. Кроме того, функция «Безопасный просмотр» защищает пароль Вашего аккаунта Google. Если Вы введете его на подозрительном сайте, то увидите предложение сменить пароль в аккаунте Google. Если история браузера синхронизируется или если Вы вошли в свой аккаунт и разрешили уведомлять Google, Chrome сделает отметку, что Ваш аккаунт Google мог подвергнуться фишинговой атаке. В версии для iOS технология безопасного просмотра контролируется компанией Apple, которая может отправлять данные в другие компании, предоставляющие сервисы безопасного просмотра.
В версии для iOS технология безопасного просмотра контролируется компанией Apple, которая может отправлять данные в другие компании, предоставляющие сервисы безопасного просмотра.Меры по обеспечению конфиденциальности при работе с приложениями, расширениями, темами, сервисами и другими дополнениями
В Chrome можно использовать приложения, расширения, темы, сервисы и прочие дополнения, включая предустановленные или интегрированные. Дополнения, разработанные и предоставленные компанией Google, могут отправлять данные на ее серверы и контролируются Политикой конфиденциальности Google, если не указано иное. Сторонние дополнения контролируются их разработчиками, у которых может действовать другая политика конфиденциальности.
Управление дополнениями
Перед установкой дополнения проверьте, какие разрешения оно запрашивает. Вот некоторые из возможных разрешений:
- хранить, просматривать и публиковать данные с Вашего устройства или из аккаунта Google Диска;
- просматривать контент на сайтах, которые Вы посещаете;
- использовать уведомления, которые отправляются через серверы Google.

Chrome может взаимодействовать с дополнениями следующими способами:
- проверять обновления;
- скачивать и устанавливать обновления;
- отправлять показатели использования дополнений в Google.
Некоторые дополнения могут запрашивать доступ к уникальному идентификатору для управления цифровыми правами или доставки push-уведомлений. Чтобы отменить доступ к идентификатору, удалите дополнение из Chrome.
Иногда мы узнаем, что некоторые дополнения представляют угрозу безопасности, нарушают условия интернет-магазина Chrome для разработчиков или другие юридические соглашения, нормы, законы и правила. Chrome периодически скачивает список таких дополнений с серверов, чтобы отключить или удалить их с Вашего устройства.
Конфиденциальность журналов сервера
Как и большинство сайтов, наши серверы автоматически записывают, какие страницы были запрошены пользователями при посещении наших ресурсов. Записи журналов сервера обычно включают Ваш интернет-запрос, IP-адрес, тип браузера, язык браузера, дату и время запроса и один или несколько файлов cookie, которые позволяют однозначно идентифицировать браузер.
Вот пример типовой записи в журнале, относящейся к поисковому запросу «машины». Ниже объясняется, что означает каждая ее часть.
123.45.67.89 - 25/Mar/2003 10:15:32 - https://www.google.com/search?q=машины - Firefox 1.0.7; Windows NT 5.1 - 740674ce2123e969
123.45.67.89– IP-адрес, назначенный пользователю интернет-провайдером. Этот адрес может меняться при каждом подключении пользователя к Интернету.25/Mar/2003 10:15:32– дата и время запроса.https://www.google.com/search?q=машины– запрашиваемый URL, который включает в себя поисковый запрос.Firefox 1.0.7; Windows NT 5.1– браузер и используемая операционная система.740674ce2123a969– идентификатор уникального файла cookie, присвоенный этому компьютеру при первом посещении сайта Google. Пользователь может удалить файлы cookie. В таком случае здесь будет указан идентификатор уникального файла cookie, добавленный при следующем посещении сайта Google с этого же компьютера.

Дополнительная информация
Вся информация, которую Google получает при использовании Chrome, обрабатывается и хранится в соответствии с Политикой конфиденциальности Google. Данные, которые получают владельцы других сайтов и разработчики дополнений, включая файлы cookie, регулируются политикой конфиденциальности таких сайтов.
Уровень защиты информации и законодательные нормы в этой сфере могут отличаться в разных странах. Мы защищаем информацию в соответствии с нашей Политикой конфиденциальности независимо от места обработки данных. Кроме того, мы соблюдаем ряд законодательных ограничений относительно передачи данных, в том числе европейские рамочные соглашения, описанные на этой странице. Подробнее…
Основные понятия
Файлы cookie
Файл cookie – небольшой файл, который содержит строку символов и отправляется на Ваш компьютер, когда Вы открываете какую-то страницу. С его помощью веб-сайт идентифицирует браузер при Вашем повторном посещении. Такие файлы используются в разных целях, например позволяют запоминать Ваши настройки. Вы можете запретить браузеру сохранять файлы cookie или включить уведомления о них, но иногда это приводит к некорректной работе сайтов и сервисов. Подробнее о том, как Google использует файлы cookie и аналогичные данные, полученные от партнеров…
Такие файлы используются в разных целях, например позволяют запоминать Ваши настройки. Вы можете запретить браузеру сохранять файлы cookie или включить уведомления о них, но иногда это приводит к некорректной работе сайтов и сервисов. Подробнее о том, как Google использует файлы cookie и аналогичные данные, полученные от партнеров…
Аккаунт Google
Чтобы получить доступ к некоторым из наших сервисов, пользователь должен создать аккаунт Google, предоставив определенную информацию (обычно это имя, адрес электронной почты и пароль). Она будет использоваться для аутентификации и защиты от несанкционированного доступа к аккаунту. Изменить данные или удалить аккаунт можно в любой момент в его настройках.
Откуда берутся биткоины при майнинге. Как появляются биткоины
Итак, мы выяснили, что сеть биткойнов позволяет хранить транзакции, и по факту это — один большой лог транзакций, связанных последовательностью — цепочкой блоков — через вычисляемые хеши, без возможности их несанкционированного изменения третьими лицами. Данный концепт цепочки блоков (блокчейн) позволяет сделать децентрализованную сеть равноправных участников, которые взаимно подтверждают такую цепочку транзакций. Существует единственная проблема — как вовлечь в такую систему новых участников? Как сделать привлекательным участие в системе и, главное, заинтересовать участников в работе — в процессе подтверждении транзакций?
Данный концепт цепочки блоков (блокчейн) позволяет сделать децентрализованную сеть равноправных участников, которые взаимно подтверждают такую цепочку транзакций. Существует единственная проблема — как вовлечь в такую систему новых участников? Как сделать привлекательным участие в системе и, главное, заинтересовать участников в работе — в процессе подтверждении транзакций?
Сатоши Накомото, разработчик протокола криптовалюты биткойн, в своей статье вводит концепт «Incentive» (стимулирования) с целью заинтересовать участников процесса подтверждения транзакций. Вводится два вида стимулирования: первый — оплата за подтверждение транзакций, второй — комиссия за перевод. И тут как раз кроется ответ на вопрос, откуда добывают биткоины. Новые биткоины появляются на свет (эмитируются) именно в момент подтверждения транзакции, никакой иной способ появления биткойнов не предусмотрен. Биткойны выплачиваются тому, кто первый найдет хеш (ключ) с заданными параметрами для первой платёжной транзакции в блоке. Блок включает в себя транзакции, появившиеся в системе за последние 10 минут, — хеши следующих транзакций и хеш самого блока вычисляется за один расчёт, в отличие от хеша первой транзакции в блоке, для которого вводится понятие «сложность».
Блок включает в себя транзакции, появившиеся в системе за последние 10 минут, — хеши следующих транзакций и хеш самого блока вычисляется за один расчёт, в отличие от хеша первой транзакции в блоке, для которого вводится понятие «сложность».
Сумма вознаграждения фиксирована и изначально составляла 50 биткойнов. Каждые 4 года сумма вознаграждения уменьшалась ровно в 2 раза. Сегодня она составляет 12,5 биткойнов. В итоге, когда вознаграждение будет 0, эмиссия биткойнов прекратится. Всего в систему может быть эмитировано 21 млн биткойнов. На сегодняшний день их более 16 млн. Таким образом, в сеть в начале эмитировалось много биткойнов, затем эмиссия плавно пошла на спад. Те, кто приступили к подтверждению транзакций первыми, получили больше преференций, чем те, кто это стал делать позже.
Но здесь заложен ещё один принцип работы сети, а именно — конкуренция за майнинг (подтверждение транзакций). Что это такое и откуда берутся биткоины при майнинге — рассказано в другой нашей статье. Вознаграждение биткойнами приводит к стимулированию прихода новых участников. Снижение размера вознаграждения останавливает легкость эмиссии биткойнов в сети при увеличении участников — в саму систему заложен принцип «охлаждения» от чрезмерного притока новых участников, которые приходят за получением исключительно новых биткойнов. Причём подтверждать транзакции (добывать или майнить биткойн) с каждым разом становится всё сложнее из-за роста затрат на вычислительные мощности. Через 2016 блоков происходит вычисление коэффициента сложности, в соответствии с которым происходит вычисление хеша с заданными параметрами — так, чтобы новый блок появлялся в среднем каждые 10 минут. Таким образом, в систему заложен принцип защиты от необоснованной эмиссии, поэтому эмиссия всегда идёт с заданной скоростью.
Вознаграждение биткойнами приводит к стимулированию прихода новых участников. Снижение размера вознаграждения останавливает легкость эмиссии биткойнов в сети при увеличении участников — в саму систему заложен принцип «охлаждения» от чрезмерного притока новых участников, которые приходят за получением исключительно новых биткойнов. Причём подтверждать транзакции (добывать или майнить биткойн) с каждым разом становится всё сложнее из-за роста затрат на вычислительные мощности. Через 2016 блоков происходит вычисление коэффициента сложности, в соответствии с которым происходит вычисление хеша с заданными параметрами — так, чтобы новый блок появлялся в среднем каждые 10 минут. Таким образом, в систему заложен принцип защиты от необоснованной эмиссии, поэтому эмиссия всегда идёт с заданной скоростью.
Веб-консоль — Инструменты разработчика Firefox
Веб-консоль:
- Выводит информацию, связанную с веб-страницей: сетевые запросы, ошибки и предупреждения JavaScript и CSS, а также сообщения об ошибках, предупреждения и информационные сообщения, выдаваемые кодом JavaScript, выполняющимся в контексте страницы;
- Позволяет взаимодействовать с веб-страницей, выполняя выражения JavaScript в её контексте.

Это часть замены старой Консоли Ошибок, встроенной в Firefox. Старая Консоль Ошибок выводила ошибки, предупреждения и сообщения от всех веб-страниц, ошибки самого выполнения самого браузера и его дополнений. Из-за этого было трудно выделить, сообщения от конкретной страницы. Новая Веб-консоль всегда привязана к определенной веб-странице и показывает только связанную с ней информацию.
На другой половине Консоли ошибок заменили — Консоль браузера, которая выводит ошибки, предупреждения и сообщения от кода браузера и от дополнений.
Чтобы открыть Веб-консоль, выберите «Веб-консоль» в меню (Веб-)разработка в Меню Firefox (или меню Инструменты, если Вы настроили показывать панель меню или Вы работаете на Mac OS X), или нажмите её комбинацию клавиш CtrlShiftK (CommandOptionK в OS X).
Внизу окна браузера появится Набор инструментов с выбранной Веб-консолью (в Панели инструментов разработчика она называется просто «Консоль»):
Под панелью инструментов окна инструментов разработчика, интерфейс веб-консоли разделён на три части:
- Панель инструментов: вдоль верхнего края — панель инструментов с кнопками типа «Сеть» («Net»), «CSS», «JS», «Защита» («Security»), «Журнал» («Logging») и «Сервер». Эта панель — для фильтрации выводимых сообщений.
- Командная строка: вдоль нижнего края — командная строка, в которую можно вводить выражения JavaScript
- Поле вывода сообщений: между панелью инструментов и командной строкой, занимая большую часть окна, располагается пространство, в которое Веб-консоль выводит сообщения.
 Эта панель — для фильтрации выводимых сообщений.
Эта панель — для фильтрации выводимых сообщений.Большую часть Веб-консоли занимает поле вывода сообщений:
В поле вывода сообщений можно увидеть:
Каждое сообщение показывается в отдельной строке:
| Время (Time) | Время когда сообщение было записано. Начиная с Firefox 28 и новее, по умолчанию время сообщения не выводится. Но при необходимости можно изменить это поведение активировав вывод времени в настроках Инструментов. |
| Категория (Category) | Категория: указывает на тип сообщения:
|
| Тип (Type) | Для все сообщений за исключением HTTP запросов и интерактивного input/output, иконка обозначает тип сообщения: ошибка (X), предупреждение(!), или просто информационное сообщение(i). |
| Сообщение (Message) | Само сообщение. |
| Количество повторов (Occurrences) | Если строка которая генерирует предупреждение или ошибку выполняется больше одного раза, то на поле сообщений она попадет только один раз, но рядом появится счётчик который укажет сколько раз это сообщение было выведено в поле сообщений. |
| Имя файля и номер строки (Filename:Line number) | Для сообщений JavaScript, CSS, и консольного API, можно отследить строку с кодом которая стала причиной этого сообщения. Консоль также покажет ссылку на файл и номер строки ставшей причиной сообщения.. Начиная с Firefox 36, сообщение также включает в себя в номер колонки в строке. |
По умолчанию консоль очищается каждый раз когда вы открываете новую страницу или перезагружает текущую. Чтобы переопределить это поведение, активируйте опцию «Enable persistent logs» в Настройках.
HTTP запросы
HTTP запросы записываются следующим образом:
| Время (Time) | Время записи сообщения |
| Категория (Category) | Показывает что сообщение является HTTP запросом. |
| Метод (Method) | Вид запроса HTTP |
| URI | целевая ссылка URI |
| Резюме (Summary) | Версия и статус HTTP протокола, время выполнения запроса. |
Нажав мышкой на сообщение вы увидите следующее окно с более детальной информацией о запросе и ответе на него:
Прокрутка вниз показывает заголовки ответа. По умолчанию веб-консоль не записывает в журнал запрос и ответ тела: чтобы сделать это, войдите в контекстное меню веб-консоли и выберите «Log Request and Response Bodies», перезагрузите страницу, а затем вы увидите их в окне » Inspect Network Request «.
Только первый мегабайт данных регистрируется для каждого запроса или ответа тела, поэтому очень большие запросы и ответы будут обрезаны.
Сообщения журнала сети не отображаются по умолчанию. Используйте filtering чтобы показать их.
XHR
С Firefox 38 и далее, веб-консоль показывает, когда сетевой запрос был сделан как XMLHttpRequest:
Кроме того, с Firefox 38 и далее, вы можете filter сетевые запросы так, чтобы только видеть XMLHttpRequests.
Как и обычный журнал запроса сетевых сообщений, журналы запросы XMLHttpRequest не отображаются по умолчанию. Использовать filtering feature to show them.
JavaScript ошибки и предупреждения
JavaScript ошибки выглядят вот так:
CSS ошибки, сообщения и переформатирование сообщения
CSS сообщения выглядят так:
По умолчанию, CSS предупреждения и регистрирования сообщений не отображаются.
Отправка-события
Веб-консоль также регистрирует события переформатированые в CSS категорию. Переформатирование это название операции, которой браузер вычисляет расположение части или всей страницы. Переформатирования происходят, когда изменение произошли на странице, чтобы браузер считал, что влияет на расположение. . Многие события могут вызвать переформатирование, в том числе: изменение размера окна браузера, активируя как псевдо-классы :hover, или манипулирование DOM в JavaScript.
Переформатирования происходят, когда изменение произошли на странице, чтобы браузер считал, что влияет на расположение. . Многие события могут вызвать переформатирование, в том числе: изменение размера окна браузера, активируя как псевдо-классы :hover, или манипулирование DOM в JavaScript.
Поскольку переформатирования могут быть дорогостоящими вычислениями и непосредственно влияют на пользовательский интерфейс, они могут иметь большое влияние на отзывчивость веб-сайта или веб-приложения. При переформатировании события веб-консоль может дать вам понять в какой момент оно начинает инициацию, как долго они принимаются к выполнению и, если есть переформатирования synchronous reflows сработавшие от JavaScript, то какой код вызвал их .
Переформатирования события регистрируются как «Журнал» сообщений, в отличие от ошибок CSS или предупреждений. По умолчанию они отключены. Вы можете включить их, нажав на кнопку «CSS» в toolbar и выбрать «Журнал».
Каждое сообщение маркируется «переформатирование» и показывает время, необходимое для выполнения переформатирования :
Если переформатирование является синхронным переформатированием, вызванным JavaScript, будет также показанна ссылка на строку кода, инициировавшего переформатирование:
Нажмите на ссылку, чтобы открыть файл в Debugger.
Синхронные и асинхронные переформатирования
Если сделанное изменение аннулирует текущую схему — например, окно браузера изменяется или некоторые JavaScript изменяют CSS элемент — макет не пересчитывается немедленно. Вместо переформатирования в асинхронном режиме, в следующий раз браузер решает что это должно быть сделано (как правило, в следующий раз браузер перекрашивается). Таким образом, браузер может накопить коллекцию основаную на недействующих изменениях и пересчитать их эффект сразу.
Тем не менее, если какой-то JavaScript код читает что стиль был изменен, то браузер должен выполнить синхронное переформатирование в порядке вычисленным расчетом стиля чтобы вернуться. Например, код как этот хочет вызовать немедленное, синхронное, переформатирование, когда вызовет window.getComputedStyle(thing).height:
var thing = document.getElementById("the-thing");
thing.style.display = "inline-block";
var thingHeight = window.getComputedStyle(thing). height; height;
height;Из-за этого, эта хорошая идея избежать чередования чтения и записи вызовов выше указанных основ стилей, когда воздействует DOM, потому что каждый раз, когда вы возвращаете стиль, который был недействительным в ранее вызваной записи, вы принуждаете к синхронному переформатированию.
Предупреждения безопасности и ошибки
Предупреждения безопасности и ошибки выглядят следующим образом :
Сообщения безопасности показанные в веб-консоли помогают разработчикам найти потенциальные или фактические уязвимости в своих сайтах. Кроме того, многие из этих сообщений помогают обучающимся разработчикам, потому что они заканчиваются «Подробной» ссылкой ведущей вас на страницу со справочной информации и рекомендациями для смягчения этой проблемы.
Полный список сообщений безопасности выглядит следующим образом :
| Сообщение | Подробности |
|---|---|
| Blocked loading mixed active content | Страница содержит смешанные активные доли: то есть, главная страница была подана через HTTPS, но попросил браузер для загрузки «активные доли», такие как скрипты, через HTTP. Браузер заблокировал активные доли. Смотрите Mixed Content чтобы узнать подробнее. Браузер заблокировал активные доли. Смотрите Mixed Content чтобы узнать подробнее. |
| Blocked loading mixed display content | Страница содержит смешанное отображение долей: то есть, главная страница была подана через HTTPS, но попросил браузер, чтобы загрузить «отображение долей», таких как изображения, через HTTP. Браузер заблокировал эти отображения долей. Смотрите Mixed Content чтобы узнать подробнее. |
| Loading mixed (insecure) active content on a secure page | Страница содержит смешанные активные доли: то есть, главная страница была подана через HTTPS, но попросил браузер для загрузки «активные доли», такие как скрипты, через HTTP. Браузер загрузил эти активные доли. Смотрите Mixed Content чтобы узнать подробнее. |
| Loading mixed (insecure) display content on a secure page | Страница содержит смешанное отображение долей: то есть, главная страница была подана через HTTPS, но попросил браузер, чтобы загрузить «отображение долей», таких как изображения, через HTTP. Браузер загрузил эти отображения долей. Смотрите Mixed Content чтобы узнать подробнее. Браузер загрузил эти отображения долей. Смотрите Mixed Content чтобы узнать подробнее. |
| This site specified both an X-Content-Security-Policy/Report-Only header and a Content-Security-Policy/Report-Only header. The X-Content-Security-Policy/Report-Only header(s) will be ignored. | Смотрите Content Security Policy чтобы узнать подробнее. |
| The X-Content-Security-Policy and X-Content-Security-Report-Only headers will be deprecated in the future. Please use the Content-Security-Policy and Content-Security-Report-Only headers with CSP spec compliant syntax instead. | Смотрите Content Security Policy чтобы узнать подробнее. |
| Password fields present on an insecure (http://) page. This is a security risk that allows user login credentials to be stolen. | Страницы, содержащие регистрационные формы должны быть поданы через HTTPS, а не HTTP. |
Password fields present in a form with an insecure (http://) form action. This is a security risk that allows user login credentials to be stolen. This is a security risk that allows user login credentials to be stolen. | Формы, содержащие поля пароля должны представить их через HTTPS, а не HTTP. |
| Password fields present on an insecure (http://) iframe. This is a security risk that allows user login credentials to be stolen. | плавающие фреймы, содержащие регистрационные формы должны быть поданы через HTTPS, а не HTTP. |
| The site specified an invalid Strict-Transport-Security header. | Смотрите HTTP Strict Transport Security чтобы узнать подробнее. |
This site makes use of a SHA-1 Certificate; it’s recommended you use certificates with signature algorithms that use hash functions stronger than SHA-1. | Сайт использует сертификат чья подпись использует алгоритм хеширования SHA-1. SHA-1 по-прежнему до сих пор широко используется в сертификатах, но он начинает показывать свой возраст. Веб-сайтам и центрам сертификации рекомендуется перейти на более сильные хэш-алгоритмы в будущем. Обратите внимание, что сертификат SHA-1 не может быть собственным сертификатом вашего сайта, но может свидетельствовать о принадлежности к сертификации, которая использовалась для подписи сертификата вашего сайта. |
 Смотрите Weak Signature Algorithm статью рассказывающюю подробнее.
Смотрите Weak Signature Algorithm статью рассказывающюю подробнее.Bug 863874 это мета-ошибка для регистрации соответствующих сообщений о проблемах безопасности в веб-консоль. Если у вас есть идеи для полезных функций, таких как те, что обсуждаемые здесь, или заинтересованы в содействии, проверьте мета-ошибку и ее зависимости.
Сообщения консоли API
This section describes the Web Console output for those console API calls that actually result in output. For more general documentation on the console API, please refer to its documentation page.
From Firefox 40 onwards, the Web Console can display console messages from Shared Workers, Service Workers, and Chrome Workers. Check the relevant options in the Filtering dropdown menu to see them.
Сообщения об ошибках
| API | Message content |
|---|---|
error() | The argument to The console will display a full stack trace for errors: |
exception() | An alias for error(). |
assert() | If the assertion succeeds, nothing. If the assertion fails, the argument: The console will display a full stack trace for assertions: |
Предупреждающие сообщения
| API | Message content |
|---|---|
warn() | The argument to |

Информативные сообщения
| API | Message content |
|---|---|
info() | The argument to |
Журнальные сообщения
| API | Message content |
|---|---|
count() | The label supplied, if any, and the number of times this occurrence of |
dir() | Listing of the object’s properties: |
dirxml() | Aliased to log(). |
log() | The argument to Если аргумент — это узел DOM, консоль выдаст его в виде инспектируемого rich text: |
table() | Display tabular data as a table. |
time() | Notification that the specified timer started. |
timeEnd() | Duration for the specified timer. |
trace() | Stack trace: |
Группировка сообщений
Вы можете использовать console.group() для создания indented groups в выводе консоли. Смотрите Использование групп в консоли для более детальной информации.
Оформление сообщений
Начиная с Firefox 31, вы можете использовать спецификатор формата "%c" для стилизации консольных сообщений:
console.log("%cMy stylish message", "color: red; font-style: italic");Сообщения ввода/вывода
Команды, отправленные браузеру через командную строку, как и результаты их выполнения, выводятся в поле вывода сообщений Веб-консоли в следуюем виде:
Темно-серая полоса служит индикатором того, что это сообщения ввода/вывода, тогда как направление стрелки обозначает разлчия между вводом и выводом.
Фильтрация и поиск
Фильтрация по типу
Для фильтрации сообщений в поле вывода сообщений Веб-консоли используется панель вверху.
Чтобы увидеть только сообщения определённого типа, нажмите на кнопку, название которой соответствует желаемому типу сообщений («Net», «CSS», и т.д.). Нажатие на основную часть кнопки включает/выключает отображение сообщений выбранного типа, тогда как нажатие на стрелку в правой части кнопки вызывает выпадающее меню с более специфическими вариантами фильтров для сообщений выбранного типа (например, вывод только предупреждений и сообщений об ошибках).
Начиная с Firefox 40, можно настроить опции фильтра «Logging», чтобы видеть сообщения от workers и add-ons:
Фильтрация по тексту
Чтобы видеть только сообщения, содержащие определённую строку, введите её в поле с меткой «Filter output».
Очистка содержимого
Наконец, Вы можете использовать эту панель для очистки всех выведенных сообщений.
Вы можете выполнять JavaScript-код в реальном времени, используя командную строку в Web-консоли.
Ввод выражений
Для ввода выражений просто введите в командную строку и нажмите Enter. Для ввода выражений, состоящих из нескольких строк, используйте комбинацию ShiftEnter вместо Enter.
Введённое выражение отобразится в окне сообщений, с выводом результата последующей строкой:
Получение переменных
Вы можете получить доступ к переменным на странице; это могут быть как внутренние переменные например в объекте window , так и переменные, добавленные с помощью Javascript кода — например с помощью jQuery:
Автоподстановка
У командной строки есть функционал автоподстановки: начните вводить несколько начальных букв — и появится всплывающее окно с возможными вариантами завершения команды:
Нажмите Enter или Tab, чтобы принять нужную подсказку, перемещайтесь вверх/вниз с помощью стрелок к другим вариантам подсказок или просто продолжайте набирать текст, если Вам не подходит ни один из вариантов.
Консоль выдает подсказки из области видимости текущего активного фрейма. Это значит, что если Вы уже достигли точки останова в функции, то у Вас будут доступны автоподстановки только для объектов, которые находятся в одной области видимости с этой функцией.
Вы можете получать такие же подсказки для элементов массива:
Объявление переменных
Вы можете объявить ваши собственные переменные, и в последующем обращаться к ним:
История команд
Командная строка запоминает введённые ранее команды: чтобы перемещаться вперёд и назад по истории, используйте стрелки вниз и вверх на клавиатуре.
Начиная с Firefox 39, эта история сохраняется между сессиями. Чтобы очистить историю, используйте clearHistory() helper function.
Работа с iframes
Если страница содержит встроенные iframes, Вы можете использовать команду cd() чтобы изменить область видимости в консоли на область определенного iframe, и после этого Вы сможете выполнять функции, которые содержит объект document в этом iframe. Существует три способа выбрать iframe используя
Существует три способа выбрать iframe используя cd():
Вы можете передать DOM-элемент для определенного iframe :
var frame = document.getElementById("frame1");
cd(frame);Вы можете передать CSS селектор для определенного iframe:
cd("#frame1");Вы можете передать глобальный объект Window для определенного iframe:
var frame = document.getElementById("frame1");
cd(frame.contentWindow);
Для переключения контекста видимости обратно к окну верхнего уровня, введите cd() без аргументов:
cd();Предположим у нас есть документ, который содержит iframe:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<iframe src="static/frame/my-frame1.html"></iframe>
</body>
</html>В этом iframe определена новая функция:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<script>
function whoAreYou() {
return "I'm frame1";
}
</script>
</head>
<body>
</body>
</html>Вы можете переключиться на контекст iframe например так:
cd("#frame1");Сейчас Вы сможете видеть, что глобальный объект Window это теперь наш iframe:
и сможете выполнить вызов функции, определенной в этом iframe:
Helper commands
The JavaScript command line provided by the Web Console offers a few built-in helper functions that make certain tasks easier.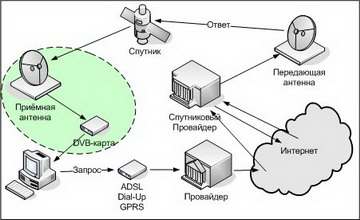
$(selector, element)Looks up a CSS selector string
selector, returning the first node descended fromelementthat matches. If unspecified,elementdefaults todocument. Equivalent todocument.querySelector()or calls the $ function in the page, if it exists.See the QuerySelector code snippet.
$$(selector, element)- Looks up a CSS selector string
selector, returning an array of DOM nodes descended fromelementthat match. If unspecified,elementdefaults todocument. This is like fordocument.querySelectorAll(), but returns an array instead of aNodeList. $0- The currently-inspected element in the page.
$_- Stores the result of the last expression executed in the console’s command line. For example, if you type «2+2 <enter>», then «$_ <enter>», the console will print 4.
$x(xpath, element, resultType)- Evaluates the XPath
xpathexpression in the context ofelementand returns an array of matching nodes. If unspecified,elementdefaults todocument. The resultType parameter specifies the type of result to return; it can be an XPathResult constant, or a corresponding string:"number","string","bool","node", or"nodes"; if not provided,ANY_TYPEis used. :block- (Starting in Firefox 80) Followed by an unquoted string, blocks requests where the URL contains that string. In the Network Monitor, the string now appears and is selected in the Request Blocking sidebar. Unblock with
:unblock. clear()- Clears the console output area.
clearHistory()- Just like a normal command line, the console command line remembers the commands you’ve typed. Use this function to clear the console’s command history.
copy()- Copies the argument to the clipboard. If the argument is a string, it’s copied as-is. If the argument is a DOM node, its
outerHTMLis copied. Otherwise,JSON.stringifywill be called on the argument, and the result will be copied to the clipboard. help()Deprecated since Gecko 62:help- Displays help text. Actually, in a delightful example of recursion, it brings you to this page.
inspect()- Given an object, generates rich output for that object. Once you select the object in the output area, you can use the arrow keys to navigate the object.
keys()- Given an object, returns a list of the keys (or property names) on that object. This is a shortcut for
Object.keys. pprint() Obsolete since Gecko 74- Formats the specified value in a readable way; this is useful for dumping the contents of objects and arrays.
:screenshot- Creates a screenshot of the current page with the supplied filename. If you don’t supply a filename, the image file will be named with the following format:
Screen Shot yyy-mm-dd at hh.mm.ss.pngThe command has the following optional parameters:
Command Type Description --clipboardboolean When present, this parameter will cause the screenshot to be copied to the clipboard. --delaynumber The number of seconds to delay before taking the screenshot. --dprnumber The device pixel ratio to use when taking the screenshot. --fileboolean When present, the screenshot will be saved to a file, even if other options (e.g. --clipboard) are included.--filenamestring The name to use in saving the file. The file should have a «.png» extension. --fullpageboolean If included, the full webpage will be saved. With this parameter, even the parts of the webpage which are outside the current bounds of the window will be included in the screenshot. When used, «-fullpage» will be appended to the file name. --selectorstring The CSS query selector for a single element on the page. When supplied, only this element will be included in the screenshot. :unblock- (Starting in Firefox 80) Followed by an unquoted string, removes blocking for URLs containing that string. In the Network Monitor, the string is removed from the Request Blocking sidebar. No error is given if the string was not previously blocked.
values()- Given an object, returns a list of the values on that object; serves as a companion to
keys().

 Use this function to clear the console’s command history.
Use this function to clear the console’s command history.


Please refer to the Console API for more information about logging from content.
When the Web console prints objects, it includes a richer set of information than just the object’s name. In particular, it:
Type-specific rich output
The Web Console provides rich output for many object types, including the following:
Examining object properties
When an object is logged to the console it appears in italics. Click on it, and you’ll see a new panel appear containing details of the object:
To dismiss this panel press Esc..
Выделение и инспектирование узлов DOM
If you hover the mouse over any DOM element in the console output, it’s highlighted in the page:
In the screenshot above you’ll also see a blue «target» icon next to the node in the console output: click it to switch to the Inspector with that node selected.
You can use the console alongside other tools. While you’re in another tool in the Toolbox, just press Esc or press the «Toggle split console» button in the Toolbar. The toolbox will now appear split, with the original tool above and the web console underneath.
As usual, $0 works as a shorthand for the element currently selected in the Inspector:
When you use the split console with the debugger, the console’s scope is the currently executing stack frame. So if you hit a breakpoint in a function, the scope will be the function’s scope. You’ll get autocomplete for objects defined in the function, and can easily modify them on the fly:
| Команда | Windows | OS X | Linux |
|---|---|---|---|
| Открыть веб-консоль | Ctrl + Shift + K | Cmd + Opt + K | Ctrl + Shift + K |
| Искать в панели показа сообщений | Ctrl + F | Cmd + F | Ctrl + F |
| Очистить панель инспектирования объекта | Esc | Esc | Esc |
| Переместить фокус на командную строку | Ctrl + Shift + K | Cmd + Opt + K | Ctrl + Shift + K |
| Очистить | Ctrl + L С Firefox 44: Ctrl + Shift + L | Ctrl + L | Ctrl + L С Firefox 44: Ctrl + Shift + L |
Интерпретатор командной строки
Эти клавиатурные сокращения работают, пока вы находитесь в Интерпретаторе командной строки.
| Команда | Windows | OS X | Linux |
|---|---|---|---|
| Прокрутить в начало вывода в консоль (новое в Firefox 34, и только при пустой командной строке) | Home | Home | Home |
| Прикрутить в конец вывода в консоль (новое в Firefox 34, и только при пустой командной строке) | End | End | End |
| Прокрутить вверх вывод консоли | Page up | Page up | Page up |
| Прокрутить вниз вывод консоли | Page down | Page down | Page down |
| Переместиться назад по истории команд | Up arrow | Up arrow | Up arrow |
| Переместиться вперёд по истории команд | Down arrow | Down arrow | Down arrow |
| Перейти в начало строки | Home | Ctrl + A | Ctrl + A |
| Перейти в конец строки | End | Ctrl + E | Ctrl + E |
| Выполнить текущее выражение | Enter | Enter | Enter |
| Добавить новую строку, чтобы войти в режим ввода многострочного выражения | Shift + Enter | Shift + Enter | Shift + Enter |
Эти клавиатурные сокращения работают, когда открыто всплывающее окно автодополнения:
| Команда | Windows | OS X | Linux |
|---|---|---|---|
| Выбрать текущее предложение в окне автодополнения | Tab | Tab | Tab |
| Закрыть окно автодополнения | Esc | Esc | Esc |
| Перейти к предыдущему предложению в окне автодополнения | вверх | вверх | вверх |
| Перейти к следующему предложению в окне автодополнения | вниз | вниз | вниз |
| Прокрутить вверх предложения в окне автодополнения | Page up | Page up | Page up |
| Прокрутить вниз предложения в окне автодополнения | Page down | Page down | Page down |
| Прокрутить в начало списка (новое в Firefox 34) | Home | Home | Home |
| Прокрутить в конец списка (новое в Firefox 34) | End | End | End |
Global shortcuts
Эти сокращения работают для всех инструментов, находящихся в окне набора инструментов.
| Команда | Windows | OS X | Linux |
|---|---|---|---|
| Увеличить размер шрифта | Ctrl + + | Cmd + + | Ctrl + + |
| Уменьшить размер шрифта | Ctrl + - | Cmd + - | Ctrl + - |
| Сбросить размер шрифта | Ctrl + 0 | Cmd + 0 | Ctrl + 0 |
Откуда берется Интернет? (ВИДЕО)
Интернет — это сеть сетей — кластеры компьютеров и серверов, все подключенные друг к другу для отправки информации по всему миру.
Интернет: мы используем его каждый день для всего, от игр до новостей и видео про запыхавшихся кошек. Но, несмотря на легкость доступа практически из любого места в наши дни, это не волшебное информационное поле.
Но, несмотря на легкость доступа практически из любого места в наши дни, это не волшебное информационное поле.
Так откуда это взялось? Нет ни одной большой комнаты, которая распределяет пропускную способность.
Интернет — это сеть сетей.Он связывает все отдельные серверы, компьютеры и устройства по всей планете. Все больше и больше наших сообщений — и всех наших веб-сайтов — живут там и путешествуют по ним.
Для большинства домашних пользователей доступ в Интернет начинается у провайдера интернет-услуг или ISP. Некоторые интернет-провайдеры покупают собственные услуги у даже более крупных интернет-провайдеров. В верхней части стека находятся поставщики уровня 1.
ПОДРОБНЕЕ: Гигабитный Интернет по-прежнему почти бесполезно быстр — на данный момент
Эти огромные сети соединяются друг с другом с помощью подводных кабелей передачи данных.Именно они делают Интернет глобальным.
Однако не все проходит через эти кабели каждый день. Такие компании, как Netflix и Google, имеют свои собственные центры обработки данных, которые подключаются к остальной части сети в скучных зданиях, называемых точками обмена данными в Интернете.
Если вы проверяете свою электронную почту или потоковое видео, скорее всего, оно проходит через одну из этих точек обмена, а затем через вашего интернет-провайдера.
В общем, трафик большой. По оценкам Международного союза электросвязи, их было около трех.2 миллиарда человек в сети в 2015 году отправляли более 20 000 гигабайт в секунду — и ожидается, что к 2020 году трафик утроится. Это много видео с котиками.
Это видео включает отрывки из The Wildlife Docs / CC BY 3.0 , Facebook , TE Connectivity , Google , NASA и Matthew Burton / CC BY 3.0 и изображения из Getty Images, The Opte Project / CC BY 2.5 , Эдвард Боутман / CC BY 3.0 , Марек Полакович / CC BY 3.0 и John Arundel / CC BY SA 3.0 .
Откуда приходит Интернет? Почему ты не можешь сделать свой собственный?
Кажется, что в Интернет так легко попасть; просто подключите компьютер к маршрутизатору и вперед. Но как создать свой собственный Интернет или даже занять место провайдера и иметь собственное подключение к Интернету?
Но как создать свой собственный Интернет или даже занять место провайдера и иметь собственное подключение к Интернету?
Давайте узнаем, откуда появился Интернет и как создать свой собственный Интернет.
Откуда приходит Интернет?
Вы можете видеть красный цвет каждый раз, когда представляете, как ваш интернет-провайдер сидит в кресле и наблюдает за вашими ежемесячными платежами, поскольку он, очевидно, ничего не делает. Однако для того, чтобы предоставить вам доступ в Интернет, требуется много работы.
Однако для того, чтобы предоставить вам доступ в Интернет, требуется много работы.
Подключение к вашему интернет-провайдеру (ISP)
Во-первых, инфраструктура. Ваше интернет-соединение не выходит прямо в интернет; сначала он должен быть доставлен вашему интернет-провайдеру. В конце концов, ISP означает «Интернет-провайдер»; вы не получите доступ в Интернет, пока не подключитесь к ним!
Ваше интернет-соединение не выходит прямо в интернет; сначала он должен быть доставлен вашему интернет-провайдеру. В конце концов, ISP означает «Интернет-провайдер»; вы не получите доступ в Интернет, пока не подключитесь к ним!
Для этого вам необходимо каким-то образом подключиться к вашему интернет-провайдеру. Проводное соединение — самый распространенный метод. Здесь кабель передает данные от вашего маршрутизатора до вашего интернет-провайдера.
Проводное соединение — самый распространенный метод. Здесь кабель передает данные от вашего маршрутизатора до вашего интернет-провайдера.
Если у вас есть оптоволокно, скорее всего, у вас есть медный кабель, идущий от вашего дома к придорожному шкафу или столбу на обочине.Как только он достигнет этой точки, он будет использовать оптоволокно на оставшейся части пути к вашему интернет-провайдеру.
Однако некоторые удачливые люди могут подключиться к дому напрямую.Это означает, что у них есть оптоволокно от дома до провайдера, что намного быстрее, чем соединение оптоволокно / медь.
Эти технологии называются «волокно до обочины» (FttC) и «волокно до помещения» (FttP) соответственно. Если вы используете последний для подключения к дому, он обычно называется «Fiber to the Home» (FttH).
Если вы используете последний для подключения к дому, он обычно называется «Fiber to the Home» (FttH).
Подробнее об этих методах вы можете прочитать в нашей статье о разнице между FttC и FttP.
Получение IP-адреса
Теперь, когда у вас есть соединение между вами и вашим интернет-провайдером, вам нужен IP-адрес. Ваш интернет-провайдер назначает это, что дает серверам, к которым вы подключаетесь, возможность связаться с вами.
Ваш интернет-провайдер назначает это, что дает серверам, к которым вы подключаетесь, возможность связаться с вами.
Когда вы получаете IP-адрес, ваш провайдер не будет извлекать из сумки четыре случайных числа и выдавать вам результат в виде адреса.Ваш интернет-провайдер должен зарегистрироваться в организации, занимающейся IP-адресами вашей страны, и получить блок адресов, который он может разослать своим клиентам.
В каждом географическом регионе есть своя собственная IP-организация.В Северной Америке вашему интернет-провайдеру необходимо связаться с ARIN, чтобы получить его адреса. В Европе есть RIPE NNC, а в Азии — APNIC.
Отправляем вас туда, куда вы хотите
Теперь, когда у вас есть соединение с вашим интернет-провайдером и адрес, пора выйти в мир. Ваш интернет-провайдер поможет определить, куда нужно ваше соединение, и отправит его по назначению.
Ваш интернет-провайдер поможет определить, куда нужно ваше соединение, и отправит его по назначению.
Для этого ваш интернет-провайдер предоставляет вам сервер системы доменных имен (DNS).Это преобразует URL-адрес веб-сайта в IP-адрес, который серверы могут затем использовать для направления вашего запроса туда, куда он должен пойти.
Мы подробно рассказали об этой технологии о том, что такое DNS-серверы и почему они становятся недоступными.
Как видите, ваш интернет-провайдер очень многое делает, чтобы помочь вам выйти в Интернет. Однако, если вы действительно захотите, можете ли вы создать свой собственный Интернет?
Однако, если вы действительно захотите, можете ли вы создать свой собственный Интернет?
Как сделать свой Интернет
Допустим, однажды вы просыпаетесь и решаете, что с вас достаточно; вы хотите установить собственное подключение к Интернету. Вы больше не хотите платить своему интернет-провайдеру и хотите делать все технические вещи самостоятельно.
Вы больше не хотите платить своему интернет-провайдеру и хотите делать все технические вещи самостоятельно.
Для этого вам понадобится сервер, который сможет использовать ваше соединение и направить его в Интернет.Вы можете купить все оборудование самостоятельно или вместо этого нанять чужой сервер.
Затем вам необходимо обратиться в организацию интернет-провайдера вашей страны, чтобы получить IP-адрес. К сожалению, вы не можете просто попросить его; вам нужно будет купить их кучу.
К сожалению, вы не можете просто попросить его; вам нужно будет купить их кучу.
Как только это будет сделано, вам нужно подключить свой сервер к дому, чтобы вы могли выходить в Интернет.Вы можете сделать это, проложив свои собственные оптоволоконные кабели (очень дорого!) Или наняв инфраструктуру другой компании.
На данный момент, вероятно, вы уже потратили пятизначную сумму, возможно, с некоторыми дорогостоящими арендными платежами.Скорее всего, вы попадете в большие долги, если не начнете предлагать свои услуги и другим людям.
В конце концов, у вас есть большой пакет IP-адресов; вы можете привлечь клиентов, которые будут ежемесячно платить вам за использование ваших услуг. Мы надеемся, что это компенсирует затраты и поможет вам окупить невозвратные затраты.
Мы надеемся, что это компенсирует затраты и поможет вам окупить невозвратные затраты.
Есть только одна проблема; ты стал тем, что поклялся уничтожить! Теперь вы официально являетесь интернет-провайдером и берете на себя клиентов, чтобы покрыть ваши расходы.
Вам наконец-то удалось избавиться от надоедливых счетов за Интернет, но теперь вы управляете целым бизнесом. Наверное, лучше всего заплатить интернет-провайдеру, который сделает за вас всю эту тяжелую работу!
Наверное, лучше всего заплатить интернет-провайдеру, который сделает за вас всю эту тяжелую работу!
Остров Оркас, пример общественного провайдера
 youtube.com/embed/CeYKIDIcBsc» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/CeYKIDIcBsc» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
Хотя создание собственного интернет-провайдера только для себя не является грандиозной идеей, есть примеры людей, объединившихся, чтобы создать интернет-провайдера для своего местного сообщества. Это ближайший пример того, как кто-то настраивает подключение к Интернету для собственных нужд.
Это ближайший пример того, как кто-то настраивает подключение к Интернету для собственных нужд.
Ars Technica рассказала историю пятидесяти человек на острове Оркас.У них был интернет через интернет-провайдера, но поскольку они находились на сельском острове, связь была нестабильной.
Жители острова Оркас взяли дело в свои руки. Они заметили, что на берегу в 10 милях от них стоит вышка широкополосного микроволнового диапазона, принадлежащая StarTouch Broadband Services. Все, что нужно было сделать жителям, — это присоединиться к этой сети.
Они заметили, что на берегу в 10 милях от них стоит вышка широкополосного микроволнового диапазона, принадлежащая StarTouch Broadband Services. Все, что нужно было сделать жителям, — это присоединиться к этой сети.
Они потратили 11000 долларов, чтобы получить разрешение на использование микроволновой башни, а затем построили свою собственную, используя водонапорную башню в качестве базы.
Затем сигналы будут отправляться на деревья возле домов людей, которые были подключены к их дому. Жители острова Оркас в конечном итоге получили стабильную скорость загрузки 30 Мбит / с — неплохо для удаленного острова!
Жители острова Оркас в конечном итоге получили стабильную скорость загрузки 30 Мбит / с — неплохо для удаленного острова!
Таким образом, вы можете создать свой собственный Интернет; однако вам понадобится большой толчок сообщества, чтобы финансировать и настроить его, вместо того, чтобы пытаться найти способы сэкономить деньги на ваших ежемесячных счетах.
Как создать Интернет
Хотя приведенная выше информация актуальна для людей, которые хотят создать собственное интернет-соединение, она не отвечает на вопрос некоторых людей о том, как создать свой собственный интернет.
Если вам интересно, как это сделать, скорее всего, вы хотите достичь одной из двух целей; либо вы хотите создать веб-сайт, который могут посещать другие люди, либо вы хотите создать «небольшой интернет» для своего дома.
Создание веб-сайта в Интернете
Если вы хотите создать веб-сайт, на самом деле вы не создаете новый Интернет для этого. Что вы делаете, так это создаете веб-страницу, которая живет в Интернете. Это все равно что пойти к агенту по недвижимости и попросить планету Земля, когда все, что вам действительно нужно, — это собственный дом!
Что вы делаете, так это создаете веб-страницу, которая живет в Интернете. Это все равно что пойти к агенту по недвижимости и попросить планету Земля, когда все, что вам действительно нужно, — это собственный дом!
К счастью, создать веб-сайт намного проще, чем создать целый Интернет.Обязательно ознакомьтесь с нашим руководством по созданию веб-сайта для получения более подробной информации.
Если кодирование — не ваше дело, вы можете использовать конструктор веб-сайтов для создания своего присутствия в Интернете.Просто ознакомьтесь с нашим полным руководством по созданию блога с помощью WordPress и избавьтесь от лишних хлопот.
Создание «локального Интернета» для вашего дома
Если вы хотите настроить свои домашние компьютеры так, чтобы все они подключались друг к другу в «локальном Интернете», это возможно.
Однако здесь нам нужно отойти от термина «Интернет».Обычно вы используете Интернет для подключения к устройствам за пределами вашего дома; здесь вы пытаетесь связаться с устройствами поблизости.
Для этого типа «Интернета» существует термин «локальная сеть» (LAN). Часть имени «Локальная область» является здесь ключевой; мы подключаемся только к устройствам, к которым физически можем дойти пешком.
Часть имени «Локальная область» является здесь ключевой; мы подключаемся только к устройствам, к которым физически можем дойти пешком.
Если вы хотите узнать больше, ознакомьтесь с нашей статьей о том, как играть в игры по локальной сети в вашей сети Wi-Fi.
Получение контроля от вашего ISP
Хотя очень возможно установить собственное подключение к Интернету, это очень дорого и стоит усилий только в том случае, если вы хотите сами стать интернет-провайдером. Таким образом, лучше всего создавать свой собственный Интернет, только если вы планируете привлечь к себе все сообщество.
Таким образом, лучше всего создавать свой собственный Интернет, только если вы планируете привлечь к себе все сообщество.
Не волнуйтесь, если вы по-прежнему хотите вернуть контроль над своим интернет-провайдером.Существует множество причин, по которым вам следует заменить маршрутизатор вашего интернет-провайдера на что-то по вашему выбору.
Изображение предоставлено: jamesteohart / DepositPhotos
7 причин, по которым следует заменить маршрутизатор поставщика услуг Интернета Ваш интернет-провайдер отправил вам маршрутизатор, когда вы зарегистрировались, и он работает нормально. Но дает ли это вам максимальную скорость?
Но дает ли это вам максимальную скорость?
Выпускник бакалавриата по компьютерным наукам, глубоко увлеченный безопасностью.После работы в инди-игровой студии он обнаружил страсть к писательству и решил использовать свои навыки, чтобы писать обо всем, что связано с технологиями.
Более От Саймона БаттаПодпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.
Кто размещает всю информацию в Интернете?
В 2018 году трудно думать о жизни без Интернета. Интернет открыл так много новых возможностей. Если бы кто-то сказал мне 10 лет назад, что я буду ходить с часами, с которыми я могу разговаривать, и скажу им выключить свет дома, я бы ни секунды не поверил. Тем не менее, вот и мы.
Жизнь в век информации имеет много преимуществ. Если у нас есть вопросы, мы просто используем Google, чтобы выяснить это.Однако Google — это не просто шахта, которую мы используем для поиска информации, ее нужно помещать туда вручную. Но как мы смогли вручную разместить всю эту информацию в Интернете всего за несколько лет?
Что такое Интернет?
Это уместный вопрос, который следует задать, прежде чем мы продолжим его обсуждение. С появлением в последние годы нового модного слова «облако», я предполагаю, что большинство людей рассматривают Интернет как просто облако. Он где-то наверху, над всеми нами, связывает наши жизни вместе.Поскольку вы находитесь на сайте networkguides.com, я предполагаю, что вы знаете, что это неправда.
Он где-то наверху, над всеми нами, связывает наши жизни вместе.Поскольку вы находитесь на сайте networkguides.com, я предполагаю, что вы знаете, что это неправда.
Интернет — это огромная сеть, построенная в 70-х годах для Министерства обороны США. Она была построена из узлов, соединяющихся друг с другом без централизованного управления. С развитием Интернета в него было вовлечено больше компаний и организаций, которые добавили свои узлы и подключения к Интернету, тем самым сделав Интернет всемирной сетью.
Интернет — это не облако и не спутник в синем.Он состоит из маршрутизаторов, коммутаторов и тонны кабелей. Есть отличный веб-сайт, который показывает количество кабелей, под названием submarinecablemap.com. Посмотрите, сколько кабелей проложено под поверхностью воды.
Настоящий Интернет основан на маршрутизаторах, коммутаторах и множестве кабелей. Как уже упоминалось, нет централизованного управления, а это означает, что никто не владеет Интернетом. Компании владеют оборудованием и частью сети, но не контролируют весь Интернет. Из-за этого не существует единой точки отказа, поэтому, если Интернет-провайдер выходит из строя, нарушается не весь Интернет, а только его клиенты.
Из-за этого не существует единой точки отказа, поэтому, если Интернет-провайдер выходит из строя, нарушается не весь Интернет, а только его клиенты.
Интересным фактом является то, что в молодости Интернет был намного более уязвим. В 1980-х годах произошла первая серьезная атака на Интернет, получившая название червя Морриса. Это был человек, который хотел увидеть, насколько велик Интернет, но из-за плохого программирования он нанес большой ущерб. Совсем недавно инциденту исполнилось 30 лет, и вы можете прочитать об этом в этом блоге ФБР.
Интернет не зависит от других и, скорее всего, никогда не отключится из-за этого. Информация в Интернете всегда будет там и всегда доступна для поиска.Если вы хотите узнать больше об Интернете, я настоятельно рекомендую серию мини-статей с Code.org.
Правительства и организации
С гораздо лучшим пониманием того, что такое Интернет, теперь мы можем сосредоточиться на том, какая информация там находится. Часто бывает так, что правительства, органы власти, компании и другие организации имеют свои собственные веб-сайты в Интернете. Они используют Интернет, чтобы информировать своих клиентов и пользователей о том, что происходит.
Часто бывает так, что правительства, органы власти, компании и другие организации имеют свои собственные веб-сайты в Интернете. Они используют Интернет, чтобы информировать своих клиентов и пользователей о том, что происходит.
Для компании нередко есть блог, в котором они пишут интересные сообщения, которые имеют некоторую связь с их продуктом.Власти часто используют Интернет, чтобы сообщить о предстоящих событиях или предупреждениях. Это та информация, которую ищут граждане, когда они в чем-то нуждаются или обеспокоены.
Пример: вы плохо себя чувствуете. Если вы погуглите свои симптомы, вы, скорее всего, найдете веб-сайт, принадлежащий вашему правительству, с объяснением, в чем может быть проблема. Это типичная информация, которую власти помещают туда для обеспокоенных граждан.
Наличие такой информации значительно облегчило контакт с властями и облегчило понимание того, что делать.Когда я планировал открыть собственную компанию, я не имел ни малейшего представления о том, как это сделать, но вместо того, чтобы заплатить какую-то дорогую рывок, чтобы помочь мне, я сам узнал об этом в Интернете, потому что власти опубликовали это там.
Сообщества
Очень популярный тип сайтов в Интернете — это сообщества и форумы. Это тип веб-сайтов, на которых вы являетесь участником и обсуждаете темы с другими участниками. Я уверен, что вы являетесь участником по крайней мере некоторых из этих типов веб-сайтов, где обсуждаете свои любимые интересы и увлечения.
Два очень распространенных типа веб-сайтов, которые часто появляются в результатах поиска в Google, — это Quora и Reddit. И Quora, и Reddit — это веб-сайты, на которых по сути вообще нет информации от компаний. Они просто предоставляют платформу. Контент на сайтах принадлежит таким людям, как вы и я. Мы идем туда, чтобы задавать вопросы и отвечать другим. Таким образом, создается огромная библиотека вопросов и ответов, которые могут найти другие.
Обычные люди, такие как вы и я
В 2000-е годы были чрезвычайно популярны веб-сайты, которые были бы отнесены к категории сетевых руководств, и создаваемые обычными людьми.Обычно это блог или какой-то фан-сайт.
В Интернете миллионы блогов. Некоторые из них обсуждают, что человек ел на обед или во что одет, в то время как другие обсуждают определенные темы (например, Интернет и нетворкинг). За этими сайтами стоят обычные люди. Хороший пример — я. Мне 26 лет, я работаю системным администратором в компании среднего размера, и я веду блог о сетях.
Многие веб-сайты начинались как небольшие блоги, а затем выросли до нынешних веб-сайтов.TechCrunch — очень популярный технический блог, за которым стоит много людей, это не шоу одного актера. Но все началось как единое целое. Майкл Аррингтон создал свой личный блог TechCrunch.
Блоги по-прежнему очень популярны среди обычных людей, и они продолжают расти до более крупных веб-сайтов. Но я бы сказал, без каких-либо цифр, подтверждающих это, что блоги — самая большая часть информации в Интернете. Таким образом, именно мы, обычные пользователи, размещаем большую часть информации в Интернете и продолжаем делать это.
Обычные люди вроде нас с вами размещают информацию в Интернете в наших блогах.
Что нам делать со всей информацией?
Этот вопрос стал искрой в этом сообщении в блоге. Однажды на работе, во время дневного перерыва, мы обсудили количество информации в Интернете и не может ли ее стать слишком много. Это информационная перегрузка и что она может сделать с нами как обществом?
Я понимаю, что это довольно философская тема, и я не буду вдаваться в нее, поскольку я не специалист по философии.Но в целом я считаю, что чем больше у нас информации, тем лучше. Никто не должен знать всего, но все должны знать кое-что.
Но есть и некоторые риски, к которым вы можете относиться серьезно, а можете и не принимать. Мне понравилось читать статью на Medium, в которой спрашивается, не слишком ли много информации мы потребляем. Я настоятельно рекомендую эту статью, если вас интересует информационное общество, в котором мы живем сегодня.
Лично я не считаю, что слишком много информации — плохо.Я думаю, что наш мозг хорошо оснащен фильтром, который может удалить ненужную информацию и сохранить то, что актуально. Проблема в том, что наш мозг принимает неправильные решения и удаляет что-то полезное. Но я думаю, что могу снова быстро поискать в Google…
Проблема в том, что наш мозг принимает неправильные решения и удаляет что-то полезное. Но я думаю, что могу снова быстро поискать в Google…
Как найти информацию в Интернете
Обновлено: 30.04.2020 компанией Computer Hope
Большую часть информации можно найти в Интернете с помощью поисковых систем. Поисковая машина — это веб-служба, которая использует веб-роботов для запроса миллионов страниц в Интернете и создает индекс этих веб-страниц.Пользователи Интернета могут затем использовать эти службы для поиска информации в Интернете. При поиске информации в Интернете имейте в виду следующее.
Объемный поиск в кавычках
Если вы ищете определенную фразу, например компьютерная справка , заключите фразу в кавычки, чтобы получить результаты для этой точной комбинации слов. Например, введите «компьютерная справка» в качестве критерия поиска, чтобы найти страницы, на которых эти два слова встречаются вместе.
Этот прием также можно использовать в частях вашего поискового запроса. Например, «компьютерная справка» Microsoft будет искать все, что содержит Microsoft , а также компьютерную справку вместе.
Например, «компьютерная справка» Microsoft будет искать все, что содержит Microsoft , а также компьютерную справку вместе.
Вы можете включить в поиск несколько цитируемых фраз. Например, поиск «Microsoft Windows» «компьютерная справка» даст результаты для страниц, содержащих обе эти точные фразы.
Помните о стоп-словах
Многие поисковые системы будут вырезать общие слова, которые они называют стоп-словами, для каждого выполняемого поиска.Например, вместо поиска , почему мой компьютер не загружается , поисковая система будет искать компьютер и boot . Чтобы избежать удаления этих стоп-слов, заключите поиск в кавычки.
КончикЕсли стоп-слова не важны, не вводите их в поиск.
Ознакомьтесь с логическими значениями
Многие поисковые системы позволяют использовать логические операторы для фильтрации плохих результатов. Хотя общие логические значения включают «и», «или» и «не», большинство поисковых систем заменили эти ключевые слова символами. Например, чтобы найти справку компьютера без результатов, содержащих Linux, введите компьютерная справка -linux . «-Linux» указывает поисковой системе исключить любые результаты, содержащие слово Linux.
Например, чтобы найти справку компьютера без результатов, содержащих Linux, введите компьютерная справка -linux . «-Linux» указывает поисковой системе исключить любые результаты, содержащие слово Linux.
Узнайте, какие функции доступны
Многие поисковые системы позволяют использовать дополнительный синтаксис для ограничения строк поиска. Например, Google позволяет пользователям искать ссылки на определенную страницу, вводя «ссылка:» и другие ключевые слова в начале поискового запроса.Например, чтобы узнать, кто связан с Computer Hope, введите: ссылка: https: //www.computerhope.com в поле поиска.
- Дополнительные советы и функции см. В разделе «Советы Google».
Попробуйте альтернативные поисковые системы
Наконец, если вы по-прежнему не можете найти то, что ищете, попробуйте другую поисковую систему. Список поисковых систем можно найти в статье о поисковых системах в Интернете.
Вот все данные, полученные от вас, когда вы просматриваете Интернет
Фотоиллюстрация Елены Скотти / Gizmodo / GMG, фотографии через Shutterstock Если вы не защитите себя, то как только вы откроете интернет-браузер, вы начнете оставлять цифровые следы за собой чтобы посещаемые вами сайты могли отслеживать ваши действия и узнавать, кто вы. Мы не говорим о какой-то безумной правительственной операции по сбору данных. Это абсолютно законное отслеживание, осуществляемое сайтами и службами, которые вы используете каждый день. Собираемые данные включают ваше текущее местоположение и ссылки, по которым вы переходите, вне зависимости от того, используете ли вы компьютер или мобильное устройство. И это только начало.
Мы не говорим о какой-то безумной правительственной операции по сбору данных. Это абсолютно законное отслеживание, осуществляемое сайтами и службами, которые вы используете каждый день. Собираемые данные включают ваше текущее местоположение и ссылки, по которым вы переходите, вне зависимости от того, используете ли вы компьютер или мобильное устройство. И это только начало.
Утечка информации начинается с вашего браузера, который по умолчанию передает различные биты основных данных сайтам, которые вы посещаете.Например, как только вы окажетесь в сети, вы начнете сообщать об IP-адресе, вашей конкретной точке входа в Интернет, по которой можно приблизительно определить ваше местоположение.
Ваш браузер также сообщает свое имя, чтобы сайты знали, являетесь ли вы приверженцем Chrome или пользователем Firefox, а также информацию о компьютерной системе, на которой он работает, включая ваш настольный компьютер или мобильную ОС, модели ЦП и графических процессоров, разрешение экрана и даже текущий уровень заряда батареи, если вы используете ноутбук, планшет или телефон.
G / O Media может получить комиссию
Чтобы увидеть некоторые из этих данных, откройте сайт Webkay и прокрутите вниз. Если сайт Webkay может читать эту информацию, то может и любая другая страница в сети.
Сайты также могут более внимательно отслеживать ваши входные данные. Чтобы увидеть часть этого отслеживания в действии, перейдите к Click, который будет сообщать вам о ваших движениях мыши, щелчках мыши и других действиях браузера.
Эти фрагменты данных — лишь первые, которые помогают сайтам идентифицировать вас.Ваш браузер, который показывает, что вы используете Microsoft Edge откуда-то из Нью-Йорка, мало что говорит о вас веб-сайту, но его можно объединить с другими данными, чтобы выделить вас из толпы.
Изображение: снимок экрана Откройте тест Panopticlick от Electronic Frontier Foundation, и вы сможете узнать больше о том, как ваш браузер может транслировать уникальный отпечаток пальца в Интернет — ваше собственное сочетание программного обеспечения браузера, оборудования, языка по умолчанию, даже установленные вами шрифты, которые могут идентифицировать вас даже без какой-либо другой информации.
Другими словами, маловероятно, что кто-то еще использует вашу особую комбинацию глубины цвета монитора, размера экрана, комбинации плагинов браузера и т. Д. Даже если вы не ввели ни одной идентифицируемой информации, веб-сайт может точно угадать, являетесь ли вы тем же парнем, что и в прошлый вторник, и соответственно предложит вам релевантную рекламу.
Данные, передаваемые браузером, — это только начало. Следующий уровень — это сайты данных, которые могут собирать сами для себя.
Какие сайты могут собиратьБольшинство сайтов очень заинтересованы в том, чтобы узнать о вас как можно больше, будь то персонализация своих услуг для вас или нацеливание на вас рекламы. Чтобы облегчить регистрацию этих данных, они обычно оставляют в вашей системе так называемый файл cookie, когда вы включаете его впервые. Эти файлы cookie представляют собой небольшие файлы, которые служат маркерами для вашей идентификации.
Как панировочные сухари в лесу, они сообщают сайту, что вы бывали там раньше. Они также могут содержать небольшие фрагменты данных: файл cookie может избавить вас от необходимости выбирать конкретный город каждый раз, когда вы посещаете веб-сайт с прогнозом погоды, потому что сайт знает, что вы выбрали в прошлый раз; файл cookie также может хранить товары в вашей корзине, чтобы они все еще ждали вас, когда вы вернетесь через несколько дней.
Они также могут содержать небольшие фрагменты данных: файл cookie может избавить вас от необходимости выбирать конкретный город каждый раз, когда вы посещаете веб-сайт с прогнозом погоды, потому что сайт знает, что вы выбрали в прошлый раз; файл cookie также может хранить товары в вашей корзине, чтобы они все еще ждали вас, когда вы вернетесь через несколько дней.
Все это очень полезно как для сайтов, так и для пользователей. Но файлы cookie могут пойти дальше и помочь добавить все больше и больше элементов в головоломку личного профиля, которая впервые начала обретать форму благодаря данным, сообщаемым вашим браузером.
Протокол безопасности браузера требует, чтобы сайты могли получить доступ только к своим собственным файлам cookie — довольно важная мера безопасности, — но у вас также есть так называемые сторонние файлы cookie, которые не связаны с конкретным сайтом, но внедряются на несколько страниц через рекламу. сети и другие технологии отслеживания.
Именно эти файлы cookie приводят к тому, что вы видите рекламу рыболовных снастей в течение целой недели только потому, что вы пару раз открывали рыболовный веб-сайт, и именно с этими файлами cookie Apple борется в последней версии своего веб-браузера Safari. , к большому огорчению рекламодателей.
По сути, все это используется, чтобы узнать, кто вы есть, и улучшить таргетинг рекламы. Данные о посещениях веб-сайтов, поиске, файлах cookie и вашем браузере собираются вместе с некоторыми обоснованными предположениями, чтобы попытаться определить, какие объявления вам будут интересны больше всего.
Изображение: Princeton University Более того, недавнее исследование, проведенное в Принстонском университете, показало, что межсайтовые трекеры, встроенные в 482 из 50 000 самых популярных сайтов в Интернете, записывают практически все действия их пользователей в браузерах для анализа. Эти записи якобы предназначены для управления и оптимизации веб-сайта; но хотя конфиденциальная информация якобы удаляется от них, это еще один случай, когда пользователи вынуждены доверять свое доверие и свои данные сторонним компаниям.
И еще одна группа фирм добавляет к этой груде данных: наши интернет-провайдеры, которые теперь могут зарабатывать деньги, продавая вашу историю просмотров, сообщая рекламодателям, где вы были и что вас интересует. Ничего из этого данные работают изолированно: маркетинговые фирмы обмениваются деталями и объединяют детали, чтобы составить очень подробный профиль. И это становится еще более подробным …
Другая информация, которую вы предоставляетеПока что так много информации, но мы еще не говорили о данных, которые вы добровольно отказываетесь: поисковые запросы, которые вы выполняете при входе в Google, места, в которые вы регистрируетесь при использовании Facebook, данные о дате рождения, которые вы указываете в Twitter, и т. д.
Сайты имеют свои собственные политики конфиденциальности в отношении того, как эти данные могут быть использованы — обычно для таргетинга на вас с помощью рекламы и, возможно, для одновременного улучшения реальных продуктов и услуг — и вы обычно соглашаетесь с этими данными. сбор, если вы хотите использовать рассматриваемые услуги.
сбор, если вы хотите использовать рассматриваемые услуги.
Итак, если вы чувствуете, что, например, у вас должна быть учетная запись Tumblr, то по сути вы даете Tumblr разрешение отслеживать все, что вы делаете в сети. Отчасти это просто здравый смысл, так что сайты могут контролировать поведение пользователей и исправлять ошибки, но это еще больше данных, которые нужно добавить поверх всего остального, о чем мы говорили
Добавьте всю эту личную информацию вместе с данными, которые уже были собраны из ваших онлайн-сессий, и крупнейшие операторы, такие как Google и Facebook, могут легко узнать вас лучше, чем вы сами.
В прошлом году Google внес поправки в свою политику конфиденциальности, чтобы данные из его рекламной сети DoubleClick могли быть объединены с другими данными, которые он знает о вас, например, с вашим именем и вашими любимыми каналами YouTube, чтобы создать очень полную картину о вас и ваших вкусах. . Не у каждой компании есть доступ к Google или Facebook, но данные можно легко покупать и продавать между фирмами, специализирующимися на этом виде профилирования.
Только на Facebook вы могли бы раскрыть, кто ваши самые близкие друзья, места, которые вы любите больше всего посещать, как часто вы заказываете пиццу, и какие лучшие живые или мертвые группы вы бы хотели включить в концертную линейку своей мечты. вверх.
Изображение: снимок экранаБлагодаря информации, которую вы предлагаете Facebook, и данным, которые он собирает, когда вы просматриваете страницы, он знает, когда вы ждете ребенка, на которого вы работали в прошлом, и что вы, вероятно, склоняетесь к политике , время суток, в которое вы любите пользоваться Интернетом, и многое другое — вы можете увидеть некоторую информацию, которую, по его мнению, он знает о вас, посетив эту страницу.
Крупнейшая в мире социальная сеть может отличаться по количеству личных данных, которые она может использовать, но принципы одинаковы для других сайтов, будь то те, которые вы используете для покупок, путешествий или чтения новостей.
На самом деле все зависит от политики конфиденциальности каждого отдельного сайта относительно того, как все эти собранные данные регистрируются и используются, если вообще используются. И хотя эти правила обычно достаточно просты для доступа, они, как правило, сформулированы в очень общих терминах, что дает сайтам большую свободу действий, когда дело доходит до работы с профилями, которые они создали на вас.
И хотя эти правила обычно достаточно просты для доступа, они, как правило, сформулированы в очень общих терминах, что дает сайтам большую свободу действий, когда дело доходит до работы с профилями, которые они создали на вас.
Что вы можете сделать
Сбор данных по своей сути не является вредоносным. Веб-сайтам нужны данные, чтобы делать их продукты лучше и продавать вам рекламу, которая удерживает их на плаву.Тем не менее, вы должны осознавать, от чего вы отказываетесь и кому. Подробнее об этом см. В нашем сопутствующем руководстве о том, как избежать отслеживания при просмотре веб-страниц.
Этот рассказ был подготовлен при поддержке Mozilla Foundation в рамках его миссии по обучению людей их безопасности и конфиденциальности в Интернете.
Как работает Интернет — Изучите веб-разработку
Как работает Интернет предоставляет упрощенное представление о том, что происходит, когда вы просматриваете веб-страницу в веб-браузере на своем компьютере или телефоне.
Эта теория не важна для написания веб-кода в краткосрочной перспективе, но вскоре вы действительно начнете получать пользу от понимания того, что происходит в фоновом режиме.
Компьютеры, подключенные к Интернету, называются клиентами и серверами . Упрощенная схема их взаимодействия может выглядеть так:
- Клиенты — это типичные устройства веб-пользователя, подключенные к Интернету (например, ваш компьютер, подключенный к вашему Wi-Fi, или ваш телефон, подключенный к вашей мобильной сети) и программное обеспечение для доступа в Интернет, доступное на этих устройствах (обычно это веб-браузер, такой как Firefox или Chrome).
- Серверы — это компьютеры, на которых хранятся веб-страницы, сайты или приложения. Когда клиентское устройство хочет получить доступ к веб-странице, копия веб-страницы загружается с сервера на клиентский компьютер для отображения в веб-браузере пользователя.
Клиент и сервер, которые мы описали выше, не раскрывают всей истории. Есть много других частей, и мы опишем их ниже.
Есть много других частей, и мы опишем их ниже.
А пока представим, что Интернет — это дорога. На одном конце дороги клиент, который похож на ваш дом.На другом конце дороги находится сервер, в котором вы хотите что-то купить.
В дополнение к клиенту и серверу нам также нужно передать привет:
- Ваше подключение к Интернету : Позволяет отправлять и получать данные в Интернете. По сути, это как улица между вашим домом и магазином.
- TCP / IP : Протокол управления передачей и Интернет-протокол — это протоколы связи, которые определяют способ передачи данных в Интернете.Это как транспортные механизмы, позволяющие оформить заказ, зайти в магазин и купить товар. В нашем примере это похоже на машину или байк (или что-то еще, что вы можете обойти).
- DNS : Серверы доменных имен похожи на адресную книгу для веб-сайтов. Когда вы вводите веб-адрес в своем браузере, браузер просматривает DNS, чтобы найти реальный адрес веб-сайта, прежде чем он сможет найти веб-сайт. Браузеру необходимо выяснить, на каком сервере находится веб-сайт, чтобы отправлять HTTP-сообщения в нужное место (см. Ниже).Это похоже на поиск адреса магазина, чтобы получить к нему доступ.
- HTTP : протокол передачи гипертекста — это протокол приложения, который определяет язык, на котором клиенты и серверы могут общаться друг с другом. Это похоже на язык, на котором вы заказываете товары.
- Компонентные файлы : веб-сайт состоит из множества разных файлов, которые подобны различным частям товаров, которые вы покупаете в магазине. Эти файлы бывают двух основных типов:
- Файлы кода : Веб-сайты создаются в основном на основе HTML, CSS и JavaScript, хотя вы познакомитесь с другими технологиями чуть позже.
- Активы : это собирательное название для всего остального, что составляет веб-сайт, например изображений, музыки, видео, документов Word и PDF-файлов.
 Браузеру необходимо выяснить, на каком сервере находится веб-сайт, чтобы отправлять HTTP-сообщения в нужное место (см. Ниже).Это похоже на поиск адреса магазина, чтобы получить к нему доступ.
Браузеру необходимо выяснить, на каком сервере находится веб-сайт, чтобы отправлять HTTP-сообщения в нужное место (см. Ниже).Это похоже на поиск адреса магазина, чтобы получить к нему доступ.Когда вы вводите веб-адрес в свой браузер (для нашей аналогии это похоже на прогулку в магазин):
- Браузер переходит к DNS-серверу и находит реальный адрес сервера, на котором находится веб-сайт (вы найдете адрес магазина).
- Браузер отправляет на сервер сообщение HTTP-запроса с просьбой отправить копию веб-сайта клиенту (вы идете в магазин и заказываете товары).Это сообщение и все другие данные, передаваемые между клиентом и сервером, отправляются через ваше интернет-соединение с использованием TCP / IP.
- Если сервер одобряет запрос клиента, сервер отправляет клиенту сообщение «200 OK», что означает «Конечно, вы можете посмотреть этот веб-сайт! Вот он», а затем начинает отправлять файлы веб-сайта в браузер в качестве серия небольших фрагментов, называемых пакетами данных (магазин дает вам товары, а вы приносите их домой).
- Браузер собирает небольшие фрагменты в целую веб-страницу и отображает ее вам (товары прибывают к вам — новые блестящие вещи, круто!).

Настоящие веб-адреса — это не приятные запоминающиеся строки, которые вы вводите в адресную строку, чтобы найти свои любимые веб-сайты. Это специальные числа, которые выглядят так: 63.245.215.20 .
Это называется IP-адресом, и он представляет собой уникальное место в сети. Однако запомнить это непросто, не так ли? Вот почему были изобретены серверы доменных имен. Это специальные серверы, которые сопоставляют веб-адрес, который вы вводите в браузере (например, «mozilla.org»), с реальным (IP) адресом веб-сайта.
На сайтыможно попасть напрямую через их IP-адреса. Вы можете узнать IP-адрес веб-сайта, введя его домен в такой инструмент, как IP Checker.
Ранее мы использовали термин «пакеты» для описания формата, в котором данные отправляются от сервера к клиенту. Что мы здесь имеем в виду? В основном, когда данные отправляются через Интернет, они отправляются в виде тысяч небольших фрагментов, так что многие разные веб-пользователи могут загружать один и тот же веб-сайт одновременно. Если бы веб-сайты отправлялись как отдельные большие куски, только один пользователь мог бы загружать их по одному, что, очевидно, сделало бы Интернет очень неэффективным и не очень интересным в использовании.
Общее количество веб-сайтов — статистика в реальном времени в Интернете
Сегодня во всемирной паутине более 1,5 миллиарда веб-сайтов. Из них менее 200 миллионов являются активными. График в 1 миллиард веб-сайтов был впервые достигнут в сентябре 2014 года, что подтверждено NetCraft в своем обзоре веб-серверов в октябре 2014 года и впервые оценено и объявлено Internet Live Stats (см. Твит изобретателя мира). Wide Web, Тим Бернерс-Ли). Впоследствии это число снизилось, вернувшись к уровню ниже 1 миллиарда (из-за ежемесячных колебаний количества неактивных веб-сайтов), а затем снова достигло и стабилизировалось выше отметки в 1 миллиард, начиная с марта 2016 года.В течение 2016 года общее количество сайтов значительно выросло — с 900 миллионов в январе 2016 года до 1,7 миллиарда в декабре 2016 года. С 2016 по 2018 год уровень практически не изменился. От 1 веб-сайта в 1991 году до 1 миллиарда в 2014 году диаграмма и таблица ниже показывают общее количество веб-сайтов по годам за всю историю:
Под « Веб-сайт » мы подразумеваем уникальных имени хоста (имя, которое можно разрешить, используя DNS-сервер в IP-адрес).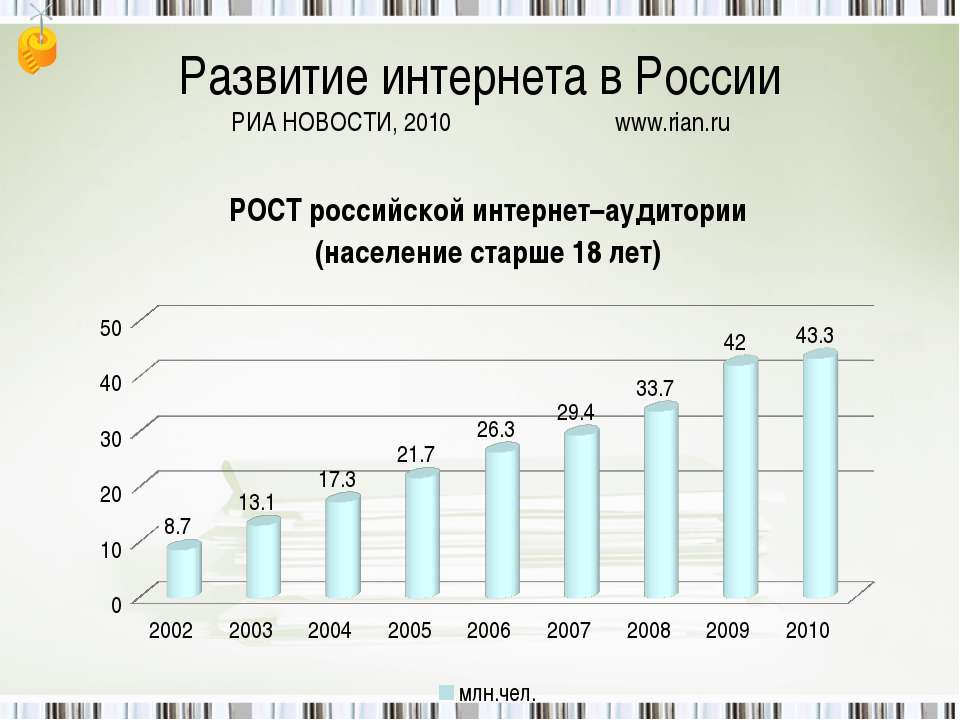
Следует отметить, что около 75% веб-сайтов сегодня неактивны, но имеют припаркованные домены или подобные. [1]
| 2018 | 1,630,322,579 | -8% | ||||||
| 2017 | 69507 | 1,045,534,808 | 21% | |||||
| 2015 | 863,105,652 | -11% | 3,185,996,155 * | 3.7 | ||||
| 2014 | 968,882,453 | 44% | 2,925,249,355 | 3,0 | ||||
| 697,089,489 | 101% | 2,518,453,530 | 3,6 | |||||
| 2011 | 346,004,403 | 67% | 2,282,955,130 | 6.6 | ||||
| 2010 | 206,956,723 | -13% | 2,045,865,660 | 9,9 | Pinterest, Instagram | |||
| 2009 | 238,027850650 9050 | 2008 | 172,338,726 | 41% | 1,571,601,630 | 9,1 | Dropbox | |
| 2007 | 121,892,559 | 43% | 1,373,32750690. 3 3 | Tumblr | ||||
| 2006 | 85,507,314 | 32% | 1,160,335,280 | 13,6 | Twttr | |||
| 2005 | 64,780,650 9050 9050 9050 9018 | |||||||
| 2004 | 51,611,646 | 26% | 910,060,180 | 18 | Thefacebook, Flickr | |||
| 2003 | 40,912,332 | 6% | 7 90,650650 9050 | 38,760,373 | 32% | 662,663,600 | 17 | |
| 2001 | 29,254,370 | 71% | 500,609,240 | 17 | 50650 017 | 50 9050 , 1 9024 | Baidu | |
| 1999 | 3,177,453 | 32% | 280,866,670 | 88 | PayPal | |||
| 1998 90,067 | 50 9030 | |||||||
| 1997 | 1,117,255 | 334% | 120,758,310 | 108 | Яндекс, Netflix | |||
| 1996 | 257,601 | 996% 90,4507 | 50 9050 90,5 | 758% | 44,838,900 | 1,908 | Altavista, Amazon, AuctionWeb | |
| 1994 | 2,738 | 2006% | 25,454,590 | 9050 9050 9050 9050 9050 9050 9050 9050 9050 Yahoo!14,161,570 90 507 | 108,935 | |||
| 1992 | 10 | 900% | ||||||
Авг.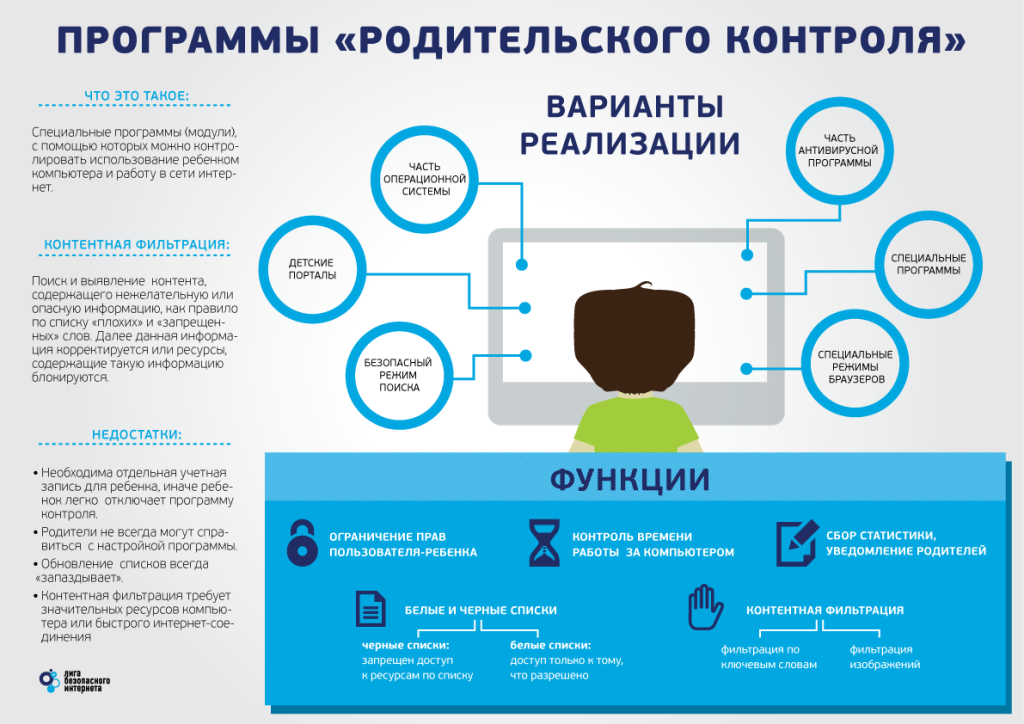 1991 1991 | 1 | World Wide Web Project | ||||||
Источник: Статистика NetCraft и Интернет в реальном времени (данные разработаны Мэтью Греем из MIT и Hobbes ‘Internet Timeline6 Pingdom и ) | ||||||||
Периодическое снижение общего числа может зависеть от различных факторов, включая улучшение обработки NetCraft имен хостов с подстановочными знаками. Например, в августе 2012 года из обзора было удалено более 40 миллионов имен хостов только на 242 IP-адресах.
Любопытные факты
- Первый веб-сайт (info.cern.ch) был опубликован 6 августа 1991 года британским физиком Тимом Бернерсом-Ли в ЦЕРНе в Швейцарии. [2] 30 апреля 1993 г. ЦЕРН сделал технологию World Wide Web (сокращенно W3) доступной на безвозмездной основе в общественное достояние, что позволило сети процветать. [3]
- Всемирная паутина была изобретена в марте 1989 года Тимом Бернерсом-Ли (см. Исходное предложение). Он также представил первый веб-сервер, первый браузер и редактор («WorldWideWeb.app »), протокол передачи гипертекста (HTTP), а в октябре 1990 г. — первая версия« языка разметки гипертекста »(HTML). [4]
- Только за 2013 год Интернет вырос более чем на треть: с примерно 630 миллионов веб-сайтов в начале года до более 850 миллионов к декабрю 2013 года (из которых 180 миллионов были активными).
- В 2016 году количество сайтов увеличилось почти вдвое: с 900 миллионов до 1,7 миллиарда. Тем не менее, более надежный показатель активных веб-сайтов, , стабильно составлял около 170 миллионов в течение года.
- Сегодня более 50% веб-сайтов размещены на Apache или nginx, обоих веб-серверах с открытым исходным кодом. [5] По состоянию на июнь 2014 года Microsoft очень близко подошла к Apache с точки зрения доли рынка (разница между ними составляет всего 0,15%). Если эта тенденция сохранится, Microsoft вскоре может впервые в истории стать ведущим разработчиком веб-серверов.
 Исходное предложение). Он также представил первый веб-сервер, первый браузер и редактор («WorldWideWeb.app »), протокол передачи гипертекста (HTTP), а в октябре 1990 г. — первая версия« языка разметки гипертекста »(HTML). [4]
Исходное предложение). Он также представил первый веб-сервер, первый браузер и редактор («WorldWideWeb.app »), протокол передачи гипертекста (HTTP), а в октябре 1990 г. — первая версия« языка разметки гипертекста »(HTML). [4] 
Популярные сайты (год запуска и внешний вид)
Pinterest (2010)
Dropbox (2008)
Tumblr (2007)
Twttr (2006)
YouTube (2005)
Reddit (2005)
Thefacebook (2004)
Flickr (2004)
Linkedin (2003)
PayPal (1999)
Google (1998)
Яндекс (1997)
AuctionWeb (Ebay, 1995) )
Amazon (1995)
Altavista (1995)
Yahoo (1994)
WWW Project (1991)
Источники
Текущее оценочное общее количество веб-сайтов доставляется алгоритмом Worldometer, который обрабатывает данные, полученные с помощью статистического анализа после сбора из следующие источники:Ссылки
- «Сколько сейчас активных сайтов?» Netcraft Ltd
- Нойес, Дэн «Первый URL-адрес снова активен.»ЦЕРН. 29 апреля 2013 г.
- ЦЕРН.
