Как быстро выучить текст на английском языке?
Многим людям приходится запоминать небольшие отрывки, а некоторым целые статьи. Это и на родном языке бывает трудно сделать. Много ли вы помните русских стихов и песен наизусть? Еще больше проблем возникает, когда нужно переходить на английский язык. Для начала, необходимо вообще знать запоминаемые слова. Однако, будь то отдельные фразы или многочисленные страницы, существуют эффективные приемы, как быстро выучить текст на английском языке.
Чтобы использовать правильную стратегию и тактику, прежде всего, надо выяснить следующее:
- какой объем предстоит заучивать;
- сколько времени дано на запоминание;
- возможны ошибки или требуется учить текст дословно;
- отвечать придется устно или в письменном виде;
- какие награды и наказания вам светят.
От перечисленных факторов и зависят рекомендации, как выучить текст на английском быстро.
Как выучить английский текст для школы (или детского сада)?
Тут обычно ситуация складывается благоприятно. Лексикон достаточно простой, используется английский для начинающих. Объемы небольшие, как правило, требуют выучить всего десяток предложений. К ошибкам сильно не придираются. В крайнем случае, грозит снижение оценки в дневнике или смех родителей на детском утреннике. По сути, идет игра, так что особенно стараться незачем. Но времени зачастую отводят мало. Скажем, подготовить выступление на следующий день, ответить завтра на уроке.
В таких условиях лучше просто вызубрить
этот примитивный английский для детей. Иногда помогает зрительная память:
если хотя бы по-русски удается хорошо представить происходящее в рассказе, запомнить
будет намного проще. Если вам предлагают различные варианты на выбор, выбирайте самые яркие и наглядные,
избегайте слишком заумных и абстрактных. Пусть абстракциями занимаются
отличники, а вы поберегите свои силы. Учителя любят так нагружать учеников, что
все равно никаких сил не остается.
Если вам предлагают различные варианты на выбор, выбирайте самые яркие и наглядные,
избегайте слишком заумных и абстрактных. Пусть абстракциями занимаются
отличники, а вы поберегите свои силы. Учителя любят так нагружать учеников, что
все равно никаких сил не остается.
Определенный труд все же необходим: для того, чтобы воспроизвести даже короткий отрывок, надо внимательно прочитать его минимум 5 раз. Не бегло просмотреть по диагонали, а с толком, чувством и расстановкой. Причем с перерывами – прочитывание 5 раз подряд мало что дает для запоминания по сравнению с однократным или двухкратным чтением. В перерывах можно заняться другими делами, развлечься, а лучше всего сходить на прогулку или поужинать.
Желательно читать утром или вечером? Вечерние
упражнения больше задержатся в вашей памяти. Точнее, завершенные
незадолго перед сном. Если вы предпочитаете спать днем, наподобие сиесты
в странах южной Европы, то и учеба будет наиболее продуктивной к полудню,
помимо вечерней.
Если основные усилия по запоминанию совершаются вечером, утром желательно устроить краткое повторение пройденного материала в удобной для вас форме. Но важно не перестараться: при постоянном повторении про себя куплетов или рассказа, память даже может ухудшиться из-за «выгорания» питательных веществ в одних и тех же клетках мозга.
Школьники, особенно старшеклассники, в
состоянии самостоятельно прочитать, понять и применить на практике написанное
выше. Что касается воспитанников детского сада, основную работу берут на себя родители. Вместо чтения часто
происходит запоминание на слух, и взрослые контролируют, что запомнил ребенок
из родительского рассказа. В дошкольном возрасте еще нельзя полагаться на
самодисциплину и самоконтроль малышей.
В дошкольном возрасте еще нельзя полагаться на
самодисциплину и самоконтроль малышей.
Как быстро выучить текст по английскому для ВУЗа?
Если вы учитесь в университете или колледже, по сравнению со школой требования возрастают. Студенты изучают углубленный курс английского языка, иногда со сложной профессиональной лексикой. Иностранный имеет гораздо большую практическую направленность, и может реально пригодиться в жизни.
От результатов учебы нередко зависят такие поощрения, как:
- получение красного диплома;
- обычная или повышенная стипендия;
- стажировка за границей;
- трудоустройство в престижной фирме.
Поэтому студенты намного серьезнее школьников относятся к делу. Их куда больше интересует, как выучить английский текст быстро и хорошо. Хотя некоторые ошибки обычно допускаются. Конечно, не грубые грамматические. Возможна замена слов синонимами, перестановка соседних фраз. Впрочем, к экзаменам не принято заучивать что-либо наизусть.
Практически невозможно давать советы, как выучить текст на английском языке быстро, когда студенту позволяют просмотреть или прослушать его один раз. Чтобы потом сразу воспроизвести устно или письменно. Тут приходится рассчитывать только на свою память. Желательно знать лексикон, и по крайней мере с первого раза понимать все услышанное или прочитанное.
Если же времени на подготовку достаточно, попробуйте использовать характерные приемы, которые реально помогают запоминать.
Как быстро выучить текст на английском: основные приемы
Рассмотрим несколько способов, которые помогут вам запоминать:
- разделение и структурирование информации;
- создание ассоциаций;
- использование зрения и слуха;
- знание грамматики.


Однообразные отрывки «в одну линию» запоминаются плохо. Чем больше разных абзацев и параграфов, тем лучше внимание человека цепляется за эти структурные особенности. Если исходный материал изначально слабо структурирован автором, самостоятельно поделите текст на несколько частей.
Желательно выделять не только грамматические единицы (например, предложения), но и похожие по смыслу участки, замечая, о чем идет речь. Скажем, в описании футбольного матча сделать для себя заметки: этот пункт посвящен правилам футбола, тот игрокам лидирующей команды. В следующей части речь идет о забитых голах или о том, как проходила игра.
Можете даже дать отдельные короткие
названия каждому пункту. Проявите фантазию, и  Структурируйте до тех пор, пока это имеет
смысл с точки зрения логики, или в каждой части останется совсем немного – 2-3
предложения.
Структурируйте до тех пор, пока это имеет
смысл с точки зрения логики, или в каждой части останется совсем немного – 2-3
предложения.
Хорошо, когда вы можете привязать заучиваемые фразы к каким-то прежним знаниям, ощущениям и переживаниям. Это мало помогает в том, как быстро выучить английский текст дословно, но, по крайней мере, вы не пропустите одну из фраз. При этом важно логически и эмоционально «цеплять» предложения или параграфы за соседние – предыдущее и следующее.
Подобная практика в высшей степени индивидуальная, а из более общих ассоциативных приемов достойно упоминания «сокращение». При сокращенной записи весь текст разбивают на участки, кодируемые ключевыми словами, хорошо бы еще с использованием рифмы и стихотворного размера. Например, фраза «по правилам игроки голы забивали» напоминает, что первый абзац посвящен футбольным правилам, второй – игрокам команды, третий – забитым голам.
Подключение различных органов чувствЛюбая информация запоминается лучше,
когда одновременно работает зрение и слух.
Читать самостоятельно или кого-то
попросить, зависит от обстановки и индивидуальных особенностей мышления. Одним
людям хорошо помогает самостоятельное чтение, другие наоборот, слишком отвлекаются,
и уделяют много внимания выговариванию слов, память же в это время ослабевает. Кроме
того, рядом с вами может просто не оказаться терпеливого помощника, и
придется самому говорить
Предложения английского текста строятся по строгим правилам.
Это известно каждому, кто хоть немного изучал иностранный в школе, или посещал
любые курсы английского. Поэтому и запоминать фразы проще, чем русские.
Не нужно помнить точно, в каком порядке идут слова, которые русскоязычные могут
переставить почти как угодно, за некоторыми исключениями. В большинстве случаев
достаточно знать сами слова, а порядок их расположения следует очевидным
образом из правил грамматики. Даже разговорный английский в самом грубом
исполнении на окраинах Лондона обычно лишен ошибок такого рода. Скорее британцы
будут неправильно писать буквы или произносить звуки.
В большинстве случаев
достаточно знать сами слова, а порядок их расположения следует очевидным
образом из правил грамматики. Даже разговорный английский в самом грубом
исполнении на окраинах Лондона обычно лишен ошибок такого рода. Скорее британцы
будут неправильно писать буквы или произносить звуки.
Естественно, нужно знать все
употребляемые в отрывке слова иностранного языка. Ведь как можно
быстро выучить что-либо, если вы элементарно не знаете лексикон? Для начала
внимательно прочитайте текст, и убедитесь, что полностью его понимаете.
При возникновении проблем с пониманием, тщательно проработайте незнакомые
слова. Только когда добьетесь успеха, пора думать о том, как выучить быстро английский текст. Крайне нежелательно заучивать новые
слова в виде бессмысленного набора букв и звуков. Не вникая в их значение,
вы запросто забудете то, что вроде бы запомнили. И попадете в неловкое
положение, если слушатель или экзаменатор станет задавать вопросы, а вы не
ответите. Или ответите неправильно, и уже не сможете «отменить ответ»,
как операцию в текстовом редакторе на компьютере.
Или ответите неправильно, и уже не сможете «отменить ответ»,
как операцию в текстовом редакторе на компьютере.
Как выучить текст на английском профессионалам?
Предположим, вы уже закончили обучение английскому и прочую скучную учебу. Отлично знаете лексику и грамматику, проблема лишь в том, чтобы выучить большой текст на английском. Особенно, если на это отведено мало времени. Такие ситуации случаются у актеров, работающих с клиентами сотрудников компаний, и других профессионалов.
Затруднения вызывает не только то, как быстро выучить по английскому текст. Зачастую его еще надо произнести очень точно и красиво, с выражением в голосе. Персонажи пьес должны говорить внятно и вдохновенно. Стюарды обязаны четко рассказывать пассажирам инструкции, как вести себя на борту. Банковские работники – без запинки объяснять клиентам условия сделок.
Понятно, что тут придется по максимуму
подключать память, внимание и мышление. Бывают случаи, когда никакие шпаргалки
не помогут. Более того, репетируя свою «роль», необходимо многократно говорить
вслух, что причиняет определенные неудобства. Надо найти место для репетиций,
где вам никто не будет мешать, и вы тоже не будете напрягать или смешить людей.
Более того, репетируя свою «роль», необходимо многократно говорить
вслух, что причиняет определенные неудобства. Надо найти место для репетиций,
где вам никто не будет мешать, и вы тоже не будете напрягать или смешить людей.
У опытных профессиональных актеров бывают собственные наработки, как выучить текст по английскому быстро. Если таковых нет, стоит воспользоваться универсальными рекомендациями, которые помогут справиться с задачей. В первую очередь, можно и нужно разделять все на части. Запоминайте каждое предложение, затем составляйте из них абзацы, и наконец, переходите к целому монологу. Так как можно выучить, скажем, за один вечер, лишь ограниченный отрывок, не берите на себя чрезмерных обязанностей. Руководителю, который требует слишком много, стоит напомнить, что вы всего лишь слабый человек.
Делайте паузу после каждого абзаца, чтобы материал успевал отложиться в памяти. Через пару минут после того, как освоили некоторую часть, например, сходите на кухню перекусить. Заодно повторите про себя текст несколько раз, чтобы закрепить эффект того, что произносили недавно вслух. Но бесконечное повторение часто дает отрицательный эффект. Не переусердствуйте в том, как выучить быстро текст на английском языке.
Заодно повторите про себя текст несколько раз, чтобы закрепить эффект того, что произносили недавно вслух. Но бесконечное повторение часто дает отрицательный эффект. Не переусердствуйте в том, как выучить быстро текст на английском языке.
Хорошо, что во многих ролях приходится заучивать рифмы, или они полностью состоят из стихов. Стихотворные цитаты гораздо лучше запоминаются. Конечно, при абсолютном понимании смысла. Отложить в своем мозге реалистичную ситуацию намного проще, чем бессмысленную последовательность. Вряд ли вы сможете воспроизвести напамять телефонный номер, состоящий из десятков цифр. А стихи можно декламировать целыми куплетами, и даже с удовольствием. Вообще, очень важно правильно себя мотивировать.
Положительная мотивация играет огромную роль в успешной работе. Только не заменяйте позитив негативом. Отрицательные эмоции, например, мысли о провале перед публикой или о наказании со стороны шефа, вырабатывают неприязнь к профессии, и вообще разрушают здоровье. Недовольный человек подсознательно думает, как бы уволиться или уйти на пенсию, а не о том, как быстро выучить текст по английскому языку.
Недовольный человек подсознательно думает, как бы уволиться или уйти на пенсию, а не о том, как быстро выучить текст по английскому языку.
Гораздо труднее, чем стихи или интересные роли, запоминаются скучные инструкции. Но и в таком случае можно «оживить» для себя сухие строки текста, это поможет запоминать. Постарайтесь создать волнующий эмоциональный настрой, принять близко к сердцу произносимые слова. И убедитесь, как выучить быстро текст по английскому языку становится намного легче. В конце концов, инструкции тоже бывают действительно важными. От них зависит спасение, например, пассажиров авиалайнера в критической ситуации. Кстати, и ваша зарплата (иногда неплохая).
Зачастую профессионалам недостаточно
просто заучить текст или произносить его как-нибудь. Надо говорить таким
образом, чтобы зрителям или слушателям нравилось. Помимо советов, как
быстро запомнить текст, надо учитывать и рекомендации ваших наставников,
как следует себя вести перед людьми. Полагается вам улыбка на лице, или
наоборот, строгое выражение. Нужны определенные жесты, или их надо тщательно
избегать, оставаясь наподобие каменной статуи. Произносите во время репетиций текст
так, как это требуется от вас. Декламируйте перед зеркалом, смотря в
отражении на свою мимику и жестикуляцию. Это несколько отвлекает от того, как выучить текст по английскому языку
быстро, но является обязательной составляющей подготовки.
Полагается вам улыбка на лице, или
наоборот, строгое выражение. Нужны определенные жесты, или их надо тщательно
избегать, оставаясь наподобие каменной статуи. Произносите во время репетиций текст
так, как это требуется от вас. Декламируйте перед зеркалом, смотря в
отражении на свою мимику и жестикуляцию. Это несколько отвлекает от того, как выучить текст по английскому языку
быстро, но является обязательной составляющей подготовки.
Как выучить быстро текст на английском: шпаргалки
Вряд ли у вас будет возможность
подсматривать целую речь, которую предстоит изучить. Иначе не было бы и
обсуждения, как легко выучить английский текст. Но незаметно записать, и
держать перед глазами хотя бы несколько слов или букв возможно практически
всегда. Студенты и профессионалы порой проявляют завидную изобретательность. Главное
– смотреться естественно, не вызывать подозрений слушателей и неудовольствия
работодателей. От этого и зависит, выбрать тот или иной способ.
Для шпаргалок подходит все, что облегчает всплывание в памяти запомненных фраз. Слова, обозначающие темы параграфов. Начальные буквы каждого предложения, чтобы не пропустить одно из них. Несколько букв можно записать даже на руке, или на носовом платке, выглядывающем из кармана. При некоторых навыках каллиграфии нетрудно сделать смываемыми красками подобие красивой, но непонятной татуировки. Если зрители (слушатели) находятся достаточно далеко, можно подготовить весьма обширную подсказку. Только бы она не была явно похожей на вашу речь, так, чтобы случайно заглянувший в нее человек ничего не понял.
Скажем, положить на стол листочек, где
написаны будто бы ваши задачи на завтра: взять интервью у вратаря, посетить
игроков на тренировке, обсудить состав команды с тренером. В реальности это
значит, что первое предложение вашего выступления посвящено вратарю, второе –
игрокам, третье – тренеру. Но содержание настоящих фраз совершенно другое,
нежели написанное на бумаге.
Резюме
Мы рассмотрели, как легко выучить текст, и связанные с этим нюансы. Будем надеяться, вам пригодятся в жизни наши советы. Если они кажутся неполными, можете добавить комментарий и подсказать еще один рецепт, как быстро и легко выучить англоязычное выступление.
Необходимо еще раз подчеркнуть, что текст с легкостью запоминается, когда он полностью понятен. Изучайте лексику, заодно и грамматику, которая при заучивании текста будет тоже не лишней. В этом помогут другие статьи, опубликованные в нашем блоге. Их очень много, но разобраться в тематике статей поможет карта сайта и система поиска. Если не можете понять, как найти необходимую информацию, задавайте вопросы.
Как учить английский по песням
Наверное, изучать английский по песням — это самый удобный и приятный способ его выучить. Почему? Просто открываете список песен на английском, включаете и наслаждаетесь.
Конечно, они не смогут заменить вам репетитора, учебники или полноценный курс по английскому, но не использовать их в качестве дополнительных занятий — просто грех! У вас остались сомнения? Сейчас мы их развеем.
Содержание статьи:
С чего начать
Сразу отметим, что предварительно найти и изучить текст понравившейся песни на английском пару раз значительно увеличит ваши шансы на понимание смысла песни и запоминание интересных слов и оборотов из нее.
Вы даже представить себе не можете, о чем иногда поют те или иные исполнители, и что кроется в запутанных лабиринтах лирики некоторых песен, а когда начнете «копаться» в этом всем, то уже не сможете остановиться до тех пор пока не выясните смысл песни. А там рядом уже и всякие интересные факты, история создания и т.д.
И так как это будет не просто какая-то песня, а одна из лучших для вас, то возвращаться к тексту и словарю скорее всего вам не придется: вы запомните строчки и слова, а может быть и весь текст, и сможете гордо подпевать исполнителю, прогуливаясь где-нибудь в парке, например, и поражая всех своими вокальными данными.
Прослушивание песен точно сможет помочь вам понимать английский лучше. So turn it up!
Читай также
Гай Фокс и его праздник
Почему стоит изучать английский по песням
Пополнение словарного запаса. В некоторых песнях есть просто уйма сленга в сочетании с глубоким смыслом, а также описание столь близких многим жизненных ситуаций и деталей в сложных взаимоотношениях между парнем и девушкой.
Из таких песен вы можете почерпнуть немало полезных слов и фраз и красивого английского, который вы параллельно учитесь воспринимать на слух.
Часто, слушая ту или иную песню впервые, у вас может возникнуть ложное впечатление о ней, а может быть вы и вовсе услышали не то, о чем там поется.
Но при следующих прослушиваниях, картина становится яснее, а вы начинаете слышать верный текст и понимать его.
Кроме того, песни на английском пробуждают в нас чувства, и нам хочется слушать их снова и снова, повоторяя за носителем вслух, мы пытаемся имитировать звуки и интонацию речи, одновременно работая над скоростью, и пытаясь не сбиваться с темпа.
А это оттачивает ваше произношение. Если не можете сразу держаться на равне с поющим, откройте текст и просто прочтите текст вслух, будто читаете книгу.
Обращайте внимание на свои губы и язык, старайтесь издавать такие же звуки как и исполнитель, произносите сложные строчки по нескольку раз. И все будет круто!
Если вы не рьяный фанат музыки из прошлого и можете с удовольствием послушать свежачки, то имейте в виду, что в новых песнях довольно много добра и позитива, которого так не хватает в сегодняшнем мире.
Кроме того, там предостаточно модных выражений, сленга и актуального разговорного английского, идущего в ногу со временем.
Взять хотя бы Drake‘s «God’s Plan». Тут есть слово «finesse» – точность, изящность, утонченность, искусность. В песне он использует его как глагол, говоря: «I finessed down Weston Road.» – Я изящно двигался вниз по Вестон Роуд. И теперь вы можете использовать его так же! Круто, правда?
А достаточно ли в вас мотивации к действию последнее время? Когда вы последний раз совершили поступок, которым гордитесь до сих пор?
Возможно, следующий свежачок стимулирует вас покорить новые вершины, а, возможно, и достичь своего апогея! Вдохновение и бодрость духа дают нам Carrie Underwood и Ludacris со своей новой песней «The Champion». Feel it!
Feel it!
Не всегда мы готовы просто слушать. Иногда можно позволить себе отвлечься от текста песни и просто насладиться картинкой клипа и звучанием музыки.
Ведь с нынешними технологиями и креативом людей музыкальные клипы становятся просто безумно красивыми, яркими и запоминающимися, наполненные чувствами и эмоциями.
В добавок к тому, все это еще сочитается с завораживающим вокалом и приятными нежными нотами песни на английском для изучения языка.
А дальше, после того как вы добавите песню себе в плэйлист, чтобы учить английский всегда и везде, перед глазами у вас будут всплывать приятные цвета и моменты из клипа … или из фильма «Black Panther», например. Kendrick Lamar с красавицей SZA и песней «All The Stars» следует далее.
На что нужно обращать внимание в песнях
Грамматика и произношение. Получать удовольствие от прослушивания и запоминать тексты песен — это превосходно. Но, как известно, в песнях допустимы ошибки, ради рифмы или удобного построения предложения, например, а иногда и просто ради стиля.
Но, как известно, в песнях допустимы ошибки, ради рифмы или удобного построения предложения, например, а иногда и просто ради стиля.
Исполнители всегда нарушали и будут нарушать правила, коверкать слова и фразы, и наверняка будут получать от этого огромное удовлетворение, не задумываясь о правильности английского и всей этой скучной грамматической тягомотине. И это норма!
Но мы то с вами хотим говорить правильно, верно? Так что не стоит изучать английский только по песням, иначе, возможно, вам придется общаться лишь среди фанатов того или иного исполнителя/группы, так как остальные люди вас просто поймут.
Вот как здесь, к примеру… Разве ты не знаешь, что нет никакой «E» в слове «Nasty», Will.i.am? C’mon…
@ 3:12.
Как правильно учить английский с помощью песен
Предлагаем следующую последовательность действий:
1. Выбрать песню.
2. Прослушать ее пару раз.
3. Найти текст к песне и, глядя в него, прослушать ее снова.
4. Разобрать текст обучающие песни на английском языке (выписать незнакомые слова и запомнить их).
5. Попробовать спеть песню с текстом.
6. Попробовать спеть песню без текста.
7. Выпить чего-нибудь и пойти спеть песню в караоке.
8. Позвонить исполнителю и спеть песню ему.
Разумеется, выполнять все шаги сразу можно не торопиться. А то вы еще устанете и распсихуетесь и вообще закинете это дело подальше, так и не ощутив весь кайф и прилив гордости от проделанного.
Вы же помните, что самое главное в изучении английского — регулярность и настойчивость? Почему бы не попробовать прямо сейчас? Вдохновение у вас есть, песен мы вам подкинули, теперь дело за малым!
Подборка песен для изучения английского
Как вы уже поняли, набраться уверенности в английском, слушая популярные легкие песни на английском довольно просто. Может быть следующие вам придутся по вкусу не особо, но знайте, что изучать язык по ним довольно удобно и эффективно.
Такие коллективы как «The Beatles» (песня «Yesterday», к примеру) и «One Direction», например, для этого дела являются довольно подходящими (если вы, конечно, не презираете бой-бенды).
А если презираете, то прежде чем вы дойдете до списков песен ниже, предлагаем запомнить следующих исполнителей и попробовать их песни: Rag’Bone Man, Dua Lipa, Eminem, Lana Del Rey, Katy Perry, Elvis Presley, Selena Gomez, P!nk.
Просто зайдите на YouTube, вбейте в поиск «lyric video» и найдите своих любимых исполнителей. Есть много хороших песен с текстом и красивой картинкой. Удобно и эффективно!
Общие выражения, повседневный язык, дескриптивные слова, метафоры и даже идиомы являются неотьемлемой частью английского языка и представлены во многих текстах из песен ниже.
Кроме того, сама песня может обеспечить эмоциональную связь между музыкой и слушателем, предоставляя вам свежие способы выразить свои чувства и эмоции.
Музыка и ритм несомненно приносят нам пользу, улучшают нашу память и запоминание слов, которое является ключевым компонентом в изучении английского языка.
Легкие песни и песни для детей на английском языке:
- The Chainsmokers & Coldplay – «Something Just Like This» — здесь есть отсылки к супергероям из комиксов, а также к греческой мифологии. Хорошая песня для того, чтобы развить у ребенка верное произношение слов вроде «myths» & «eclipse».
- Cookie Monster – «Share It Maybe». Best lyrics ever! Для любителей печенья и припевов.
- Parekh & Singh – «Ghost». Немного дрим-попа (dream pop) не помешает. Песня о том, когда человек чувствует себя призраком, будучи влюбленным в кого-то силшком сильно и не получая ответной любви взамен. Некоторые дети влюбляются так рано! Обратить внимание можно на слова «partially» (частично) & «whim» (причуда, каприз).
ТОП 10 английских песен для детей
Лучшие песни для изучения английского :
- Ed Sheeran – Shape of You. У нас уже была статейка с переводом этой песни, и если вы еще не добавили ее себе в плейлист, то уж позаботьтесь об этом. Интересные слова (вроде «jukebox» или «shots») и отличное настроение ждут вас!
- Jonny Cash – «Hurt». Хорошо бы почитать текст песни отдельно — много мудрого и интересного сказано. Подойдет для практики advanced reading.
- Ядерная «старая школа» в песне Suzanne Vega – «Tom’s Diner» порадует любителей старых хитов конца 80-х. С этой песне можно поучить Present Continuous.
 У нас уже была статейка с переводом этой песни, и если вы еще не добавили ее себе в плейлист, то уж позаботьтесь об этом. Интересные слова (вроде «jukebox» или «shots») и отличное настроение ждут вас!
У нас уже была статейка с переводом этой песни, и если вы еще не добавили ее себе в плейлист, то уж позаботьтесь об этом. Интересные слова (вроде «jukebox» или «shots») и отличное настроение ждут вас!Специальные обучающие песни:
- Nick Cave и Kylie Minogue с песней «Where The Wild Roses Grow» подойдут тем, у кого проблемы с прошлым, точнее с Past Tenses.
- «Policy of Truth» от обожаемых многими «Depeche Mode» подойдет для изучения условных предложений 3 типа (the thrid conditional). Уровень Intermediate.
- А «Boys Don’t Cry» от динозавров британского рока «The Cure» подойдет для условных предложений 2 типа (the second conditional).
 Уровень Intermediate.
Уровень Intermediate.Песня для запоминания алфавита. Она одна, единственная и неповторимая, с глубоким смыслом и сложнейшей лирикой. Постарайтесь не сломать себе голову, пока будете подпевать. Этот голос будет вам сниться, а текст и мелодия — поселяться в вашей голове навеки и будут напоминать о себе по утрам. Но зато эта песня заставит вас запомнить английский алфавит раз и навсегда.
Читай также
Разбираем американские остро-социальные песни
Заключение
В мире столько прекрасных песен под любое настроение, только представьте сколько удовольствия можно получить, обогатив свой английский и сделав свой день ярче благодаря какой-нибудь сочной песенке!
Подумайте какую хотят услышать ваши уши сегодня и попробуйте ее спеть! Think you can do that?
Выбирайте качественнные песни и приступайте к усовершенствованию своих навыков в английском прямо сегодня! Не ждите сигнала, а просто попытайтесь насладиться процессом. And we are always here to inspire you! Have a nice one and …
And we are always here to inspire you! Have a nice one and …
Stay classy!
Большая и дружная семья EnglishDom
заявка отправляется
Пожалуйста, подожди…
Занимайся английским бесплатно
в онлайн-тренажере
Перевод текста с английского на русский
Ежедневно в мире множество компаний, физических лиц и организаций вступают в диалог или делятся информацией с коллегами-иностранцами.
Оставить заявку на обучение, вы можете здесь
Большинство из них обращаются за помощью к профессиональным агентствам по переводам текстов с английского на русский, которые представлены во всех значимых городах мира. Если же вы решили самостоятельно освоить навыки переводчика английского языка, то данная статья вам будет особенно интересна!
Что такое перевод?
Перевод является важным фактором в сближении людей и организаций друг к другу по всему миру. Этимологически смысл слова «перевод» означает «перенос через» или «перемещение через».
Таким образом, с помощью перевода текста с английского на русский, можно преодолеть языковые барьеры, которые часто препятствуют эффективной коммуникации.
Языковой перевод является сложным процессом со множеством деталей, в котором переводчик старается выразить смысл текста на одном языке средствами второго языка.
В процессе преобразования текста с английского на русский смысл должен оставаться неизменным. Как правило, язык оригинала упоминается как «исходный язык», а язык перевода как «целевой язык».
Как правило, язык оригинала упоминается как «исходный язык», а язык перевода как «целевой язык».
Как работают переводчики?
Обычно, для получения профессионального и качественного перевода текстов по английскому люди пользуются услугами переводческих агентств в крупном городе.
Однако, иметь дело с иностранными языками не так просто, как может показаться. Было бы заблуждением считать, что перевод означает простую замену слов одного языка аналогичными словами на другом языке.
Бывали случаи, когда человек, несведущий в переводе, пытался оценить его качество, сравнивая количество слов в исходном тексте и в тексте переведенном. Поскольку эти цифры не совпадали (а такое совпадение, мягко говоря, маловероятно), перевод оценивался как неадекватный.
Качественный перевод требует интенсивного исследования в предмете исходного текста. Кроме того, переводчик, как правило, должен иметь глубокие знания как исходного, так и целевого языков.
В идеале, переводчиком должен выступать носитель целевого языка. Немаловажно, чтобы переводчик хорошо понимал обычаи и образ жизни людей, для которых предназначен данный перевод. Это позволит более точно донести смысл текста до адресата.
Очень важно, чтобы переводчик текстов с английского на русский в области юридических, медицинских, технических, научных или коммерческих переводов был специалистом в соответствующем вопросе.
Что нужно для качественного перевода?
Необходимо помнить, что перевод текста с английского на русский не является просто механическим процессом перевода слов с одного языка на другой.
Существует множество факторов, которые необходимо учитывать для получения точного и тематически адаптированного перевода с английского языка.
Вот наиболее важные аспекты, на которые должен обращать свое внимание переводчик:
- Фактический контекст в исходном и целевом языках. Смысл и подтекст одного и того же понятия могут быть очень разными.
- Грамматические особенности двух языков. Помните, что грамматика, являясь важнейшей составляющей любого языка, имеет свои специфические правила в каждом из них.
- Правописание на целевом языке является наиважнейшим фактором качественного перевода. Как вы знаете, между английским и американским вариантами английского языка существует немало различий в написании. Например, английское слово colour в американском варианте выглядит как color.
- Письменные нормы, принятые для целевого языка. Речь идет об орфографии, пунктуации, грамматике, а также правилах капитализации (выделения слов заглавными буквами) и деления текста на абзацы.
- Перевод идиом и устойчивых выражений с одного языка на другой часто вызывает сложности. Например, дословный перевод английской фразы Wear your heart on your sleeve на любой другой язык вряд ли будет иметь понятный смысл.

- Использование точек и запятых в написании числительных имеет свои правила в разных языках. Это важно, поскольку в английском языке десятичные числительные записываются как 1,000.01. То же самое в испанском языке правильно писать как 1.000,01.
 Это важно, поскольку в английском языке десятичные числительные записываются как 1,000.01. То же самое в испанском языке правильно писать как 1.000,01.
Это важно, поскольку в английском языке десятичные числительные записываются как 1,000.01. То же самое в испанском языке правильно писать как 1.000,01.Такие детали важны с точки зрения высококачественного выполнения переводов текстов с английского на русский.
В дополнение хочется напомнить, что в процессе перевода важно тщательно сверять переведенный текст с исходным. Редактирование на разных стадиях работы позволит вам избежать ошибок.
Читайте также:
The House of the Rising Sun: история, текст, перевод
Песня «Demons» группы Imagine Dragons
Перевод песни «Chandelier» (Sia)
100 популярных разговорных фраз на английском
Как быстро выучить английский текст?
Как бы тяжело это не казалось, но быстро выучить английский текст под силу, как начинающему, так и продвинутому advanced-полиглоту. Конечно, если вам не с первого раза удается не просто запомнить, но и понять заданное упражнение, не стоит отчаиваться ведь порой нелегко выучить текст даже на родном языке.
Как быстро и легко выучить текст по английскому?
- Упростить усвоение незнакомого текста поможет самый, что ни есть обычный перевод. А как же иначе понять, о чем идет речь? В данном случае или переводим сами, или пользуемся Google-переводчиком, не забыв в переведенном тексте, в случае чего, исправить окончания слов, а в некоторых местах заменить слова на подходящие по смыслу.
- Далее длинные предложения разбиваем на ряд простых. Не нужно детально вникать в то, как можно быстро выучить текст на английском языке. Главное сейчас уделить особое внимание незнакомым словам: или их заменяем уже знакомыми вам синонимами, или, если того желает душа, выучиваем их наизусть.
- Этот пункт не является обязательным к выполнению. Некоторым еще со школьной скамьи составление плана будущего рассказа во многом помогало, а кому-то нет. К примеру, если в тексте речь идет о музеях Лондона, то в первом пункте указываем основную информацию (наименования музеев, год их строительства, архитектурные стили, в которых они выполнены и т. д.). Второй пункт – это упоминание деталей (представленные картины, имена художников, скульптуры, их создатели и пр.). Наконец, последний пункт плана – почему стоит посетить тот или иной музей, что интересного откроет здесь для себя каждый турист и т.п.
- Если же имеем дело с небольшим текстом, то попробуйте переписать его раз этак 10. Мало того, что подтяните свою грамматику, отшлифуете орфографию, так еще и текст запомните. К тому же в данном случае начинает работать зрительная память. Нелишне, записывая текст, произносить его вслух. Если не поленитесь, запишите его на диктофон. На следующий день вместо любимого плейлиста включите английский текст.
- Иной вариант быстрого запоминания английского текста и новых слов заключается в методе ассоциаций. Сюжет, описываемый в тексте, представляйте в виде картинки. Пусть каждое предложение или абзац будут привязаны, будь то к вашей жизненной истории, так и к песне, фильму.
- Главное не старайтесь зазубрить текст. Таким образом, вы, конечно, сдадите материал, справитесь с заданием, но английский свой не улучшите.
 д.). Второй пункт – это упоминание деталей (представленные картины, имена художников, скульптуры, их создатели и пр.). Наконец, последний пункт плана – почему стоит посетить тот или иной музей, что интересного откроет здесь для себя каждый турист и т.п.
д.). Второй пункт – это упоминание деталей (представленные картины, имена художников, скульптуры, их создатели и пр.). Наконец, последний пункт плана – почему стоит посетить тот или иной музей, что интересного откроет здесь для себя каждый турист и т.п.
Как выучить английский с помощью текста и аудио
Добрый день уважаемые читатели.
Этот способ подойдет для тех, кому интересна работа с текстом, есть любимая книга англоязычного автора, которую перечитывал когда-то несколько раз (конечно на русском).
Рассмотрим все на примере романа известного писателя Джека Финнея «Меж двух времен».
Прошу учесть, что описание приведено для использования на телефоне (так же, как и приложения, помогающие изучать английский с помощью текста и аудио, указаны для смартфонов), именно применение мобильной техники помогает достичь возможности тренироваться где угодно и когда угодно. Приступим.
Подготовка
Наши действия будут следующими:
- Скачаем (купим) книгу в электронном виде на двух языках. Как вариант — сделаем закладки этого романа с известных онлайн библиотек в браузере. Лучше, что бы любимое произведение было не двух-, трехтомником, ну вы поняли.
- Найдем (купим) роман в виде аудиокниги на английском.
- Установим в телефон нужные читалки и проигрыватели. Например, бесплатные приложения: браузер Opera, всеядную читалку Cool Reader, проигрыватель аудиокниг MortPlayer.

Алгоритм освоения книги
- Открываем книгу на английском языке, читая и пытаясь вникнуть. Там где непонятные слова, копируем, используя Google переводчик (быстрый способ использования тут) и переводим.
Чтение текста на английском
- Поняв смысл, проверяем себя на русском варианте, уточняя смысл.
Читаем на русском языке
Тут главное использовать переводы либо времен СССР, либо современные. Варианты, имеющие переводы 90-х годов не стоит использовать.
- Слушаем этот абзац на английском с профессиональным чтецом с параллельным чтением текста на этом же языке (интонации двух разных стран сильно отличаются, такое слушание-чтение помогает вычленить на слух слова).
Слушаем аудио
- Слушаем только аудио версию до тех пор, пока начинаем воспринимать слова и предложения на слух.

Надо ли объяснять, что к концу книги вы ее будете знать почти наизусть?))
Использование читалки FBReader для усиления эффекта работы с текстом.
Что бы при очередном повторе чтения романа не возвращаться к переводчику за забытыми переводами слов, можно использовать вместо приложения Cool Reader программу FBReader.
Делается это следующим образом (на всякий случай процедуру с самого начала показываю):
Идем в Google Play и устанавливаем:
Открываем роман и выделяем (долгим нажатием на нем) слово, которое нужно запомнить
Из открывшегося меню выбираем значок «закладки»
Вводим перевод рядом с английским вариантом (русский вариант не будет виден в обычном состоянии в тексте, пока мы не стукнем по выделенному слову).
Вводим переводТеперь у нас есть английский текст с выделенными словами, которые имеют скрытый перевод. Если мы забыли значение – тапаем (коротко нажимаем на выделенное слово) и получаем перевод.
Преимущества совместного изучения текста и аудио:
- Бесплатность
- Активное расширение словарного запаса. Так, роман «Меж двух времен» имеет порядка 8000 словоформ.
- Помогает изучить английский с помощью текста и аудио быстрее.
Недостатки:
- Невозможно тренировать разговорный язык.
- Не вся любимая беллетристика может быть в аудио и текстовом вариантах.
- Если взять не любимое произведение, а первое попавшееся – может не хватить настойчивости.
Как научиться понимать английский язык на слух? Это вообще возможно? — Хабр Q&A
Эта проблема «не слышать» не только у вас. Все этим страдают. Переехав в США многие так и не могут выучить английский, в штатах даже целый район Бруклина русскоязычный есть, Брайтон тому пример.Реально действенный метод, смотреть один и тот же фильм, много раз подряд. Пока вы не заучите наизусть фильм.
До тех пор, пока вы не сможете просмотреть весь фильм от начала до конца, полностью без перевода, зная что говорится в каждом его предложении на слух. Первый раз смотрите с двойными субтитрами, сверху русский, снизу английский, или наоборот. Читайте, как хотите. Чтобы на 20 или 100 раз вы могли смотреть без субтитров, надо в начале посмотреть хотябы раз с ними, прежде чем смотреть без них. Такого плана надо смотреть, https://www.youtube.com/watch?v=Mab65wWVc4o но это бритиш, это не американский. Американских фильмов в сети миллионы. С бритиш стартовать проще, у них произношения педантичные, выговаривают каждую букву.
Первый раз смотрите с двойными субтитрами, сверху русский, снизу английский, или наоборот. Читайте, как хотите. Чтобы на 20 или 100 раз вы могли смотреть без субтитров, надо в начале посмотреть хотябы раз с ними, прежде чем смотреть без них. Такого плана надо смотреть, https://www.youtube.com/watch?v=Mab65wWVc4o но это бритиш, это не американский. Американских фильмов в сети миллионы. С бритиш стартовать проще, у них произношения педантичные, выговаривают каждую букву.
Второй действенный метод учить правила. По правилам могу сказать следующее, в нужном порядке:
- Алфавит — надо знать идеально, понимать, что нету буквы дубль’вэ а есть дабл’ю
- Артикли — зарубить себе на носу, что без трёх артиклей никуда
- Перед городами и странами артикли не ставятся. Есть 3 исключения, в мире: The U.S., The Netherlands и The U.K.
- Вспомогательные глаголы — все наизусть т.к. без глагола любое предложение в англ. неправильное и абсурдное
do, did, was, were, am, is, are, had и т. д. все на зубок - Маркеры — yet, now, soon и т.д… выучить все обязательно, и в каком времени они употребляются
- Неправильные глаголы — выучить 100 штук, минимум
- Множественное число — plural
- Цифры — one two three, 110, 18 890, 100 000 и т.д. — сколько осилите, минимум до миллиарда
- Порядковые числа — first, second, third, fourth, fifth — и т.п. от зубов должно отскакивать
- Единицы измерения: miles, foot unit, gallons, hours — надо понимать что час это не хоур а «уанауа»
- Дни недели — не путать вторник и четверг, Tuesday и Thursday часто «мешают», и приезжают через день, когда всё
- 2 новых звука основанные на «прикусывании» языка θ и ð — звука th вообще нету в русском, в английском он везде
- To be going to — Намерения
- Сокращения — gonna, wanna, gotta, outta, dunno и т.д. сколько найдёте, без них американец рта не открывает
- There is и There are — Почти каждое простое предложение начинается с этой популярной конструкции
- This и These — это и эти, наберите в переводчике оба этих слова, чтобы заучить на слух разницу
- Could, Would и самое важное Should — без этого устной речи не бывает
- Исключения — в английском языке исключений больше чем самих правил. Например чувства, которые не употребляются в continuous: I hate a не I’m hating, I prefer вместо I am prefering. Или слова исключения такие как одна мышь — mouse, но две мыши это — two mice, или teeth вместо toothses
- Отрицание — not a но не not the!
- Neither — используется собеседником для ответа вам, если ему не подходят оба из предложных вами варианта. Антоним — это both
Такое часто бывает, если у вас например спрашивают would you like coffee or beer? — Neither. Ни то, ни другое. - Like — это не нравится, а обычно переводится как. Например I’m like Superman or like a mentor
- Идиомы — самое важное в английском языке. Английский состоит из идиом, которые «таратолятся» без пробелов.
- Фразовые глаголы — как и идиомы, состоят из нескольких слов, зачастую полностью меняя их смысл.
- Фразы сорняки — самый «жесткач», речь кишит ими, фильмы не особо: well, basically, let’s see, you know и т. д.
- При вопросе всегда ставьте вспом. глагол в начале предложения — чтобы учиться языку дальше, спрашивая на нём:
Is there a way to? Are they teachers? и т.д.
 д. все на зубок
д. все на зубок Например чувства, которые не употребляются в continuous: I hate a не I’m hating, I prefer вместо I am prefering. Или слова исключения такие как одна мышь — mouse, но две мыши это — two mice, или teeth вместо toothses
Например чувства, которые не употребляются в continuous: I hate a не I’m hating, I prefer вместо I am prefering. Или слова исключения такие как одна мышь — mouse, но две мыши это — two mice, или teeth вместо toothses  д.
д.Произношения учите, вы должны знать элементарное: archive — это аркайв, а *.ini это не ини а айнай и т.п.
Забудьте про Петрова. Ему программу делал сын индиец, который вырос если я не ошибаюсь в Индии.
И обязательное, наоборот смотрите фильмы с субтитрами. Читайте их внимательно. Чтобы смотреть кино без субтитров на слух, надо в начале посмотреть его с субтитрами много раз. С чегото же надо начинать!!!
Если вам скажут что английский язык лёгкий, не верьте. Потому что это враньё. Русский язык учат до 3 класса, а английский язык учат всю жизнь. Сделайте для начала английский язык по дефолту в ОС на компьютерах и телефонах, даже не обсуждается, настройки должны быть переключены ещё вчера. Весь UI только на английском.
Лучше курсов всё равно ничего нет. Там ты пойдёшь, и тебе учитель всё расскажет, и покажет, на доске, и в книгах. На моих курсах включали магнитофон в сложных моментах. Нас учили по сканам из разных книг, но были две книги основные это Round Up3 и Голицинский 5-e издание. Также нас заставляли учить английские тексты наизусть, большие тексты, по одной странице раз в неделю говорить наизусть. Это самое лучшее средство. Поэтому я советую смотреть один и тот же фильм 100 раз, пока не выучите все его тексты наизусть, если вы не хотите идти на курсы. Вы потом эти тексты будете везде слышать которые выучили в фильме, и ими говорить, меняя существительные на свои, под вашу ситуацию. Вы научитесь так не только слышать, но и говорить.
Там ты пойдёшь, и тебе учитель всё расскажет, и покажет, на доске, и в книгах. На моих курсах включали магнитофон в сложных моментах. Нас учили по сканам из разных книг, но были две книги основные это Round Up3 и Голицинский 5-e издание. Также нас заставляли учить английские тексты наизусть, большие тексты, по одной странице раз в неделю говорить наизусть. Это самое лучшее средство. Поэтому я советую смотреть один и тот же фильм 100 раз, пока не выучите все его тексты наизусть, если вы не хотите идти на курсы. Вы потом эти тексты будете везде слышать которые выучили в фильме, и ими говорить, меняя существительные на свои, под вашу ситуацию. Вы научитесь так не только слышать, но и говорить.
Слова учить бесполезно, вот пример, самое простое доказательство что это правда: check this out!
И что? Сheck — проверять, this — это, out — снаружи! Проверь снаружи это? Нет, это переводится как зацените:
Слова ничего не значат, если вы знаете слова, то вы не поймёте смысл, даже и не надейтесь, даром потратите время.
 Тогда как в русском языке вы можете понять смысл, зная слова, в английском языке без зубрёжки на курсах, у вас это так просто не получится.
Тогда как в русском языке вы можете понять смысл, зная слова, в английском языке без зубрёжки на курсах, у вас это так просто не получится.Как быстро выучить текст наизусть. Приемы и методики заучивания текстов, в т.ч. на иностранном языке — Методика преподавания — Преподавание
Что нужно знать об устройстве памяти
Память – сложная психическая функция, с помощью которой мы усваиваем новые знания и приобретаем практический опыт. Наш мир никогда бы не стал таким, каким мы его видим, без невероятных возможностей нашей памяти.
Ученые подсчитали, что объем человеческой памяти равен порядка тысячи терабайт. При этом на обработку всей информации мозгу требуется всего 20 Ватт энергии. Это делает его самым энергоэффективным местом для хранения информации.
Память включает в себя несколько взаимосвязанных процессов, в которых участвуют разные зоны мозга:
- Запоминание новой информации и интеграция ее в общую систему ассоциативных связей.
- Хранение в долговременной памяти.
- Воспроизведение материала в неизменном виде по мере необходимости.
- Забывание ненужной и неактуальной, по мнению мозга, информации.

Подробно все эти процессы мы рассмотрим в статье “Как развивать память”, а сейчас сосредоточимся на запоминании.
Запоминание – первое звено этой длинной цепочки. Любые ошибки и помехи на этом этапе сводят на нет всю последующую работу мозга. Как выглядит этот процесс изнутри?
Любая информация, воспринимаемая мозгом, вызывает отклик в нервной системе. Нейроны (специфические клетки мозга) возбуждаются и начинают обмениваться электронными импульсами. Проходя по нервным волокнам, эти импульсы оставляют следы и формируют нейронные пути. Большинство из них впоследствии разрушаются, остаются лишь те, что успели закрепиться.
Закрепление происходит в двух случаях: если стимул был очень сильный и если сигналы проходили по этому пути много раз подряд. В первом случае активизируется так называемое стрессовое запоминание, а во втором – запоминание посредством многократных повторов.
Наша задача – сделать так, чтобы нейронные пути закреплялись как можно быстрее и с наименьшими энергозатратами. Для этого необходимо знать некоторые особенности работы памяти и использовать их себе во благо.
Подготовка к экзаменам: как с лёгкостью запомнить больше
Определите свой стиль изучения
Все мы разные, поэтому и стратегии подготовки к экзамену у нас будут отличаться. Отталкивайтесь от своих индивидуальных особенностей. Если вы аудиал, читайте учебники и конспекты вслух, если кинестетик — пишите по своим конспектам шпаргалки и составляйте план ответа.
Если вы аудиал, читайте учебники и конспекты вслух, если кинестетик — пишите по своим конспектам шпаргалки и составляйте план ответа.
Ещё один эффективный метод — карта мыслей. Это отличный способ структурировать информацию, освежить знания и быстро вникнуть в суть предмета даже спустя продолжительное время. Подробнее о том, как составлять ментальные карты и как работать с ними, мы рассказывали тут.
Какие вопросы учить первыми? Если в течение семестра вы неплохо разобрались в предмете, приступайте к вопросам, о которых имеете хоть какое-то представление.
Если каждый новый блок нельзя понять без предыдущего, то вариант один: учите всё строго по порядку.
Также имеет смысл начинать со сложных вопросов, выделяя достаточно времени на их изучение. Лучше разобраться с ними, пока вы не устали и не потеряли концентрацию. Лёгкие вопросы оставляйте на потом.
И будьте последовательны. Придерживайтесь выбранной стратегии, даже если начинаете паниковать с приближением экзамена.
Стремитесь к пониманию, а не запоминанию
Вникайте в билет, а не старайтесь его вызубрить. Заучивание — заведомо проигрышная стратегия, которая к тому же отнимает больше времени. Находите логические связи в вопросах, придумывайте ассоциации.
Конечно, в каждом предмете есть информация, которую нужно знать наизусть: даты, формулы, определения. Но даже их запоминать легче, если вы понимаете логику.
На экзамене рассказывайте материал своими словами, домысливайте, чтобы ответ был более развёрнутым.
Методика «3–4–5»
giphy.com
Хороший метод, когда к экзамену нужно подготовиться за короткий промежуток времени. Потребуется всего три дня, но работы предстоит много. Каждый день нужно прорабатывать весь материал, но на разном уровне, постоянно углубляясь.
В первый день вы прочитываете весь свой конспект или методичку, чтобы освежить знания по предмету, грубо говоря — втянуться. Условно считаем, что вы уже можете сдать экзамен на тройку.
Во второй день разбираетесь с теми же вопросами, но уже по учебнику, чтобы узнать больше деталей и тонкостей. Если вы готовитесь старательно, можете уже рассчитывать на четвёрку.
В последний день вы доводите свои ответы до идеала: повторяете, заполняете пробелы, запоминаете. После третьего дня вы готовы сдать экзамен на отлично.
Два дня на изучение, один на повторение
Система очень простая: весь материал нужно разбить на две одинаковые части и выучить его за два дня. Третий день целиком уделяется повторению.
Ставьте ограничение по времени
Вникать в каждую тему можно бесконечно долго, поэтому не старайтесь запомнить все тонкости. Из большой главы в учебнике выделяйте главные мысли: структурированный материал небольшого объёма воспринимать легче.
В университетские годы мы делили все билеты между одногруппниками и каждый готовил краткий конспект по своей части. Если в вашей группе взаимопомощь не развита, можно попросить материалы и шпаргалки у студентов старших курсов.
Не застревайте
Если чувствуете, что слишком долго сидите над одним вопросом, пропускайте его. Лучший мотиватор при подготовке — таймер. Решите, сколько времени вы можете уделить одному билету, например 30 минут, и по истечении срока переходите к следующему. Выделите несколько часов перед экзаменом, чтобы разобраться с пропущенными вопросами.
Лучший мотиватор при подготовке — таймер. Решите, сколько времени вы можете уделить одному билету, например 30 минут, и по истечении срока переходите к следующему. Выделите несколько часов перед экзаменом, чтобы разобраться с пропущенными вопросами.
Составьте план ответа на билет
Любой, даже самый обширный вопрос можно описать в нескольких словах. При этом каждый тезис должен вызывать ассоциации.
Такой план можно быстро просмотреть перед экзаменом, чтобы настроиться на рабочий лад. Известен метод трёх предложений: выписывайте по каждому вопросу проблему, главную мысль и вывод.
Изучение зависит от предмета
Индивидуальные особенности есть не только у вас, но и у изучаемого предмета. Например, точные науки — математика, физика — требуют практики. Для гуманитарных наук важно умение перерабатывать большие объёмы информации, запоминать даты, имена, определения.
Но, повторюсь, к изучению любого предмета нужно подходить активно: вникать в вопрос и стремиться к пониманию.

Важен и формат экзамена. Если вы готовитесь к устному экзамену, проговаривайте свои будущие ответы вслух. Моя любимая тактика — пересказывать материал кому-нибудь из домашних или, когда они не проявляют энтузиазма, самой себе перед зеркалом. Ещё лучше, если кто-то будет не просто вас слушать, но и задавать вопросы, когда что-то непонятно.
Если готовитесь к тестированию, стоит прорешать десяток типовых тестов, выписать свои ошибки, повторить проблемные темы и прорешать всё снова.
Если экзамен письменный, нужно заранее продумать структуру ответа.
Готовьтесь вдвоём или втроём
Выпишите самые сложные, на ваш взгляд, темы — коллективный разум поможет разобраться с ними быстрее. Лучше кооперироваться с одногруппниками, которые настроены на учёбу, иначе подготовка к экзамену может перейти в обычную приятную встречу с дружескими разговорами.
Нет, это не значит, что шутить и отдыхать возбраняется. Просто не забывайте о главной цели собрания.
Viktor Kiryanov/Unsplash. com
com
Ещё несколько рекомендаций по подготовке к экзаменам
- Делайте перерывы. Это поможет вам расслабиться и разложить новую информацию по полочкам.
- Выключите телефон, не заходите в социальные сети, не приближайтесь к телевизору. Если не можете справиться с искушением, почитайте о том, как бороться с отвлекающими факторами.
- Высыпайтесь.
- Не забывайте о еде: это даст дополнительные силы вашему организму. Однако переедать не стоит. Обычно после излишне плотного обеда начинает клонить в сон, и учиться совсем не хочется.
- Избегайте стрессовых ситуаций и негатива от других людей. Атмосфера во время занятий должна быть максимально благоприятной.
- Не слишком полагайтесь на шпаргалки и возможность списать. А если вы не умеете хорошо списывать (согласитесь, это тоже нужно уметь), не стоит даже начинать.
- Обустройте место для занятий: светлое, комфортное, со всеми необходимыми материалами под рукой. Кровать не самый подходящий вариант: велика вероятность заснуть на скучной теме.
- Делайте маркированные списки: их легче запоминать.
- Отвлечься и размять затёкшие за время длительного сидения мышцы помогут занятия спортом. Кроме того, во время бега, езды на велосипеде или подобной физической активности можно не спеша поразмышлять над сложными вопросами.
- Если чувствуете, что не настроены на учёбу, начните с темы, которая кажется вам наиболее интересной. Это поможет войти в колею.
- Ходите вечером на прогулки. Во время подготовки нервы обычно на взводе, поэтому нужно немного расслабляться.
- Составьте чёткий план подготовки.

Как научиться запоминать больше и быстрее: рекомендации психологов
Каждый человек обладает индивидуальными характеристиками памяти. Кто-то, например, от природы хорошо запоминает лица, пейзажи и другие зрительные образы. Кому-то легко запоминать информацию на слух, поэтому он знает наизусть все популярные песни.
Однако существуют общие закономерности, свойственные всем людям. Их мы и рассмотрим в статье. А также способы и приемы их развития. Я расскажу, что вам нужно делать, чтобы лучше запоминать любую информацию.
А также способы и приемы их развития. Я расскажу, что вам нужно делать, чтобы лучше запоминать любую информацию.
Сначала поймите, а потом запоминайте
Больной вопрос всех студентов: “Как учить материал так, чтобы в голове хоть что-то оставалось?” Ответ психологов: “Откажитесь от механической зубрежки”. Эффекта от нее очень мало, а ресурсов она съедает много. Даже если вам удастся в нужный момент воспроизвести выученный материал, надолго он в голове не задержится. Зачем же тратить время впустую?
Мозг хорошо запоминает ту информацию, что вызывает у него знакомые ассоциации или образы. Незнакомые слова для него – бессмысленный набор букв, от которого он сразу же попытается избавиться. Поэтому прежде чем пытаться запомнить что-то, убедитесь в том, что понимаете все до единого слова.
Если учите текст на иностранном языке, сначала полностью его переведите и выпишите незнакомые слова. Если имеете дело с узкоспециальной информацией, изобилующей терминами, потрудитесь в первую очередь узнать значение каждого из них.
Сокращайте, не теряя сути
Для того чтобы эффективнее использовать память, нужно научиться отсекать лишнюю информацию. Ресурсы мозга ограничены, поэтому глупо тратить их на второстепенную ерунду. Сокращайте информацию, прежде чем запоминать ее.
Поначалу вам может показаться, что отсекать нечего. Но это лишь первое впечатление. Очистите информацию от субъективных оценок и эмоций, уберите отвлеченные рассуждения, и останется самая суть.
Для тренировки советую завести аккаунт в Twitter и регулярно выкладывать туда свои мысли. Ограничение в 140 символов поможет вам развить краткость и лаконичность.
Проговаривайте вслух то, что пытаетесь запомнить
Этот метод в первую очередь подойдет тем, кто плохо запоминает наглядный материал. Читая вслух, мы получаем информацию сразу из двух анализаторов: визуального и аудиального. Соответственно, в ее обработке участвуют несколько отделов головного мозга и такая информация распознается как более важная.
Кроме того, чтение вслух требует дополнительной концентрации – у вас не получится читать и думать о чем-то отвлеченном. Значит, вы не упустите существенных деталей, и не придется перечитывать по десять раз. Также можно записать на диктофон ключевые слова и фразы и чередовать чтение с прослушиванием.
Значит, вы не упустите существенных деталей, и не придется перечитывать по десять раз. Также можно записать на диктофон ключевые слова и фразы и чередовать чтение с прослушиванием.
Мыслите позитивно
Если пытаться запомнить что-то с мыслью “У меня не получится”, тогда действительно ничего не получится. Вы должны верить в успех того, что делаете, иначе вся работа превратится в сизифов труд.
Даже если до экзамена осталась одна ночь, а вы только открыли билеты, настройтесь использовать возможности вашей памяти по максимуму. Все негативные мысли отсекайте и подбадривайте свою память приятными словами.
А ты помнишь, как мы в том году с тобой 30 английских слов выучили за день? То ли еще будет! Вот сейчас соберемся и расправимся с этими билетами!
Повторяйте правильно
Мало один раз запомнить что-то, нужно еще эту информацию закрепить. Для этого нужны повторения. Психологи советуют повторять материал таким образом: сразу после заучивания, потом через 15–20 минут, затем через сутки и еще раз через 2–3 недели. Такой способ называется методом интервального повторения. На сегодняшний день он считается лучшим.
Такой способ называется методом интервального повторения. На сегодняшний день он считается лучшим.
Также повторения требует любая нужная информация, которой вы долго не пользовались, но хотели бы сохранить. Например, английский язык, выученный в школе, математические формулы, столицы государств. Находите время, чтобы иногда “прогонять” себя по этим дисциплинам.
Делайте перерывы
Запоминание новой информации – напряженная умственная работа. Если не давать мозгу отдыхать, он очень быстро исчерпает все резервы. Поэтому не забывайте делать перерывы.
Качественный перерыв – это не переключение с чтения учебника на чтение новостной ленты в соцсети. Важно освободить тот анализатор, которым вы воспринимали информацию. Если читали, то освободить глаза, если слушали – уши. Лучше всего переключиться на двигательную активность – пройтись, сделать зарядку.
Делать перерывы нужно каждый час хотя бы по 10 минут. Поставьте таймер, чтобы случайно не пропустить это время.
Мыслите практически
Очень часто нам приходится запоминать абстрактную информацию, которая никак не связана с окружающей нас действительностью. Например, математические формулы, термины из гуманитарных наук.
Например, математические формулы, термины из гуманитарных наук.
Человеческий мозг – очень практичный орган. Несмотря на то что он может оперировать абстрактными категориями, запоминает он легче информацию, имеющую конкретное материальное выражение. Поэтому старайтесь связать с реальностью все, что вы пытаетесь запомнить.
Визуализируйте информацию
Графики, диаграммы, схемы, презентации отлично помогают в запоминании материала. Недаром в школе учителя часто прибегают к ним. Возьмите и вы на вооружение этих помощников.
Только не нужно слишком возиться с ними – выключите на время перфекциониста. Достаточно, если визуальные материалы будут понятны только вам.
Выбирайте правильное время для запоминания
Мозг наиболее продуктивен в ранние утренние часы – с 7 до 10. Затем внимание притупляется, сознание заполняют посторонние мысли, и мы начинаем отвлекаться. Успейте использовать это время с пользой. Лучше проснуться пораньше и позаниматься 3 часа, чем проспать до обеда, а потом мучить себя весь оставшийся день.
Второй по продуктивности пик приходится на вечер – с 8 до 11 часов. В это время хорошо повторять уже изученный материал. Пусть до отхода ко сну мозг будет занят обработкой поступившей информации. Когда вы уснете, этот процесс плавно перейдет на бессознательный уровень.
Как быстро выучить текст: эффективные приемы запоминания
Умение держать в памяти ключевые детали будущего выступления — полезный навык для любого человека. Чтобы заучивать материал быстро, нужно исключить все внешние раздражители и создать рабочую обстановку. Для эффективного заучивания лучше пользоваться несколськими каналами восприятия и придерживаться такого алгоритма:
- Прочитайте весь текст несколько раз, вникните в его смысл.
- Используйте ассоциации (запоминайте картинку, нарисованную воображением во время чтения или прослушивания).
- Разделите материал на логические части и составьте план.
- Выпишите к пунктам опорные слова или цитаты.
- Перескажите каждую часть отдельно, затем соедините рассказ.
Если нужно выучить текст дословно:
- По возможности прослушайте аудио-версию с опорой на печатный вариант.
- Перепишите каждый абзац текста несколько раз.
- Закрасьте корректором окончания предложений и по памяти впишите недостающие слова. Воспроизведите материал устно или письменно.
Если текст запоминает ребенок, нужно сделать процесс максимально увлекательным, используя игровые приемы:
- Замените часть слов картинками и воссоздайте рассказ. Постепенно закрашивайте все новые слова и рисуйте на их месте картинки, каждый раз заново пересказывая материал.
- Сделайте копию текста и разрежьте на небольшие части. Теперь можно собирать его как паззл, параллельно читая получившиеся предложения. Чем ярче и смешнее шрифт — тем лучше.
- Усложните задачу: пропустите существенный момент или добавьте лишние факты.
Чтобы быстро выучить большой текст, желательно:
- Делить его на части и работать с каждой из них отдельно.
- Составить план рассказа или занести основные данные в таблицу.
- Повторять материал регулярно с небольшими перерывами.
- Использовать несколько каналов восприятия (например, зрительный и аудиальный).
Интересная читателю информация откладывается в памяти автоматически. Текст, написанный понятным языком, — лучше поддается заучиванию. Сложный материал нужно максимально упростить и прояснить все непонятные моменты.
Техники эффективного запоминания
Теперь давайте рассмотрим несколько эффективных мнемотехник.
Ключевые слова
Вам будет проще запомнить большой объем информации, если делать краткие пометки для себя. Разделите информацию на равные блоки, в каждом из них выделите ключевые слова и запишите их. Они будут триггерами, которые запускают ассоциативный ряд и помогают воссоздать данные из памяти.
По такому же принципу удобно конспектировать лекции. Не пытайтесь ухватить все сразу и записать слово в слово – у вас все равно не получится. Слушайте, вдумывайтесь, а самое важное записывайте.
Слушайте, вдумывайтесь, а самое важное записывайте.
Логические цепочки
Знаменитый американский психолог Джон Миллер изучал закономерности работы кратковременной памяти. Он выяснил, что в конкретный момент времени мы можем удерживать в уме 7 объектов (+/- 2). Но как выяснилось, это правило можно легко обойти.
Для этого нужно объединить все объекты какой-то общей концепцией. Мозгу гораздо проще запоминать осмысленную связанную информацию, чем набор разрозненных элементов. Проще всего придумать логичный осмысленный рассказ с ключевыми словами и запомнить его.
Рифмы
Вы, наверное, замечали, что стихи запоминать намного проще, чем прозу. В самой структуре стихотворения есть подсказки (ритм и рифма), которые помогают нам подбирать нужные слова в процессе воспроизведения.
Я до сих пор помню наизусть все глаголы-исключения второго спряжения в русском языке, которые мы учили в третьем классе. А все потому, что наша учительница догадалась их зарифмовать. Получился забавный стишок.
Смотреть, обидеть, видеть.
Держать и ненавидеть.
Зависеть, слышать, гнать.
Вертеть, терпеть, дышать.
Так что если есть такая возможность, рифмуйте то, что вам нужно запомнить. Например, новые иностранные слова, список покупок в магазине.
Аббревиатуры
Этим методом активно пользуется мой папа. Каждый раз перед походом в магазин он пишет список покупок, но не берет его с собой, а составляет из первых букв аббревиатуру. Например, было: масло, сыр, яблоки, конфеты, апельсины, рыба, орехи, молоко. А получилось: МСЯКАРОМ. Благодаря этой системе он всегда знает точное количество продуктов, которые нужно купить, и легко воссоздает их по первым буквам. Метод подойдет для запоминания любых видов списков, а также имен людей в больших компаниях.
Мнемонические фразы
Мнемонические фразы придумывают для запоминания сложно запоминающейся информации. И они отлично работают! Все мы учили цвета радуги по фразе “Каждый охотник желает знать, где сидит фазан”. Вот еще несколько довольно популярных мнемонических предложений:
Вот еще несколько довольно популярных мнемонических предложений:
- “Решил Коля кафтан сшить, будет авось без изъян” – для запоминания самых крупных государств (Россия, Канада, Китай, США, Бразилия, Австралия, Индия).
- “Морозным вечером залез на мачту юнга, стремясь увидеть незнакомый порт” – для запоминания порядка планет Солнечной системы (Меркурий, Венера, Земля, Марс, Юпитер, Сатурн, Уран, Нептун, Плутон).
- “Каждому старшекласснику, владеющему фантазией, география и так ясна” – для запоминания стран большой семерки (Канада, США, Великобритания, Франция, Германия, Италия, Япония).
Кстати, ничто не мешает вам самим придумывать такие фразы. Давайте вместе сочиним фразу для запоминания российских городов, в которых есть метро. Это Москва, Санкт-Петербург, Екатеринбург, Самара, Казань, Нижний Новгород, Новосибирск. У меня получилось вот что: “Мальчик Саша ел суп и кормил несчастного носорога”. Теперь и вы попробуйте. Можете менять слова местами – порядок не важен. Жду ваши варианты в комментариях!
Жду ваши варианты в комментариях!
Эффект края
Этот эффект был открыт немецким психологом Германом Эббингаузом. Проводя эксперименты по изучению памяти, он вывел интересную закономерность. Человек лучше всего запоминает начало и конец любой информации.
Хотите проверим? Прочитайте один раз последовательность слов.
Табуретка, крапива, потолок, рыба, дерево, куртка, пчела, зеркало, командировка, шоколад, вдохновение, королева.
А теперь попытайтесь воспроизвести этот список. Держу пари, вы хорошо запомнили слова “табуретка” и “королева”, а что насчет остальных? Наверняка многие слова из середины списка ускользнули от вашей памяти.
Как пользоваться этим эффектом при осознанном запоминании? Разделите информацию на блоки, самые важные и сложные учите в начале и в конце. Остальные распределите в середине. При запоминании больших объемов информации можно чередовать – сегодня учим блоки в одном порядке, завтра меняем их местами.
Ошибайтесь
Очень интересную особенность памяти открыли исследователи из Университетского колледжа в Лондоне. Мы лучше запоминаем то, в чем успели совершить ошибки. Констатация собственного невежества стимулирует память и дает дополнительный заряд мотивации.
Мы лучше запоминаем то, в чем успели совершить ошибки. Констатация собственного невежества стимулирует память и дает дополнительный заряд мотивации.
В следующий раз, прежде чем начать учить новый материал, устройте себе небольшой тест. Например, выпишите незнакомые иностранные слова и попытайтесь их перевести интуитивно. Естественно, у вас ничего не получится. Зато “негативный” опыт поможет вам впоследствии выучить эти слова в два раза быстрей.
Методики запоминания
Умение держать в памяти ключевые детали будущего выступления — полезный навык для любого человека. Чтобы заучивать материал быстро, нужно исключить все внешние раздражители и создать рабочую обстановку. Для эффективного заучивания лучше пользоваться несколськими каналами восприятия и придерживаться такого алгоритма:
- Прочитайте весь текст несколько раз, вникните в его смысл.
- Используйте ассоциации (запоминайте картинку, нарисованную воображением во время чтения или прослушивания).
- Разделите материал на логические части и составьте план.
- Выпишите к пунктам опорные слова или цитаты.
- Перескажите каждую часть отдельно, затем соедините рассказ.

Если нужно выучить текст дословно:
- По возможности прослушайте аудио-версию с опорой на печатный вариант.
- Перепишите каждый абзац текста несколько раз.
- Закрасьте корректором окончания предложений и по памяти впишите недостающие слова. Воспроизведите материал устно или письменно.
Если текст запоминает ребенок, нужно сделать процесс максимально увлекательным, используя игровые приемы:
- Замените часть слов картинками и воссоздайте рассказ. Постепенно закрашивайте все новые слова и рисуйте на их месте картинки, каждый раз заново пересказывая материал.
- Сделайте копию текста и разрежьте на небольшие части. Теперь можно собирать его как паззл, параллельно читая получившиеся предложения. Чем ярче и смешнее шрифт — тем лучше.
- Усложните задачу: пропустите существенный момент или добавьте лишние факты.
Чтобы быстро выучить большой текст, желательно:
- Делить его на части и работать с каждой из них отдельно.
- Составить план рассказа или занести основные данные в таблицу.
- Повторять материал регулярно с небольшими перерывами.
- Использовать несколько каналов восприятия (например, зрительный и аудиальный).
Интересная читателю информация откладывается в памяти автоматически. Текст, написанный понятным языком, — лучше поддается заучиванию. Сложный материал нужно максимально упростить и прояснить все непонятные моменты.
Метод пиктограмм
Пиктограммы — способ замены слов и предложений картинками. Для этого не обязательно быть художником. Чем проще и смешнее картинки, тем лучше. Детям важна визуализация и заинтересованность, вовлеченность в процесс. В данном случае эти аспекты наилучшим образом сочетаются.
Методика:
- Разделите большой текст на части. С маленьким рассказом работайте целиком.
- Разделите доску или листок на две части. Слева запишите пронумерованные предложения, каждое с новой строчки.
- Прочитайте предложения, разберите новые слова.
- Читайте каждое предложение отдельно, изображая его картинкой справа. Можно начать с замены отдельных слов, постепенно усложняя работу.
- Закройте левую часть. Пересказывайте текст по картинкам неограниченное количество раз.
- Попробуйте пересказ без опоры на картинки.

Во время знакомства с игрой — рисуйте картинки сами. Затем, постепенно, можно привлекать детей.
Взрослым также подойдет этот метод, если материал изложен более или менее простым языком.
Этот способ особенно подойдет визуалам (тем, кто лучше воспринимает информацию через зрение), но пользоваться им может любой желающий. Результат будет в любом случае, просто кому-то понадобится больше времени на его достижение.
Методика:
- Разделите текст на несколько частей. Работайте с каждой частью отдельно.
- Прочитайте первую часть, разберите незнакомые слова и выражения.
- Перепишите часть текста 1-2 раза.
- Канцелярским корректором закрасьте отдельные фразы. Допишите их по памяти. Проверьте себя.
- Перепишите текст еще раз. Закрасьте вдвое больше фрагментов. Заполните пробелы.
- Повторяйте до тех пор, пока не сможете полностью воспроизвести абзац.
- Соедините все части воедино, перескажите текст устно.

Эту работу можно сочетать с прослушиванием (метод, описанный выше), тогда результат будет качественным и долгим.
Метод повторений
Если времени на изучение совсем мало, а нужно быстро выучить текст на английском, можно использовать прием постоянных повторений.
Методика:
- Написать на листах небольшие отрывки рассказа. Лучше пользоваться яркими маркерами кричащих цветов.
- Развесить их по дому: над кухонным столом, в ванной, на зеркале в прихожей, на балконе.
- Бывая в этих местах или просто проходя мимо, вы увидите: взгляд «зацепится» за предложения, а прочитанное отложится в памяти.

Конечно, сам по себе прием работать не будет, но как дополнение к другим способам — даст неплохой результат и ускорит запоминание.
Составление плана
Если нет задачи выучить английский текст наизусть, а можно все передать своими словами, хорошо поможет подробный план будущего рассказа. Важно понимать смысл текста и разбираться в том, о чем собираешься говорить, а задание обязательно должно соответствовать уровню владения языком.
Методика:
- Вдумчиво прочитайте текст, выпишите незнакомые слова.
- Разбейте материал на логические части (вступление, ключевые мысли и факты, окончание).
- Выделите опорные пункты. Составьте развернутый план каждой части. Изложите его в форме коротких тезисов, цитат или вопросов.
- Перескажите текст по плану несколько раз, заглядывая при необходимости в оригинал.
- Перескажите текст, не заглядывая в оригинал, а затем — и не пользуясь планом.
Опорные пункты в виде цитат можно выделять прямо в оригинале текста, подчеркивая их карандашом.
А на полях делать свои заметки.
Это карта мыслей, которая позволяет структурировать даже очень сложный для восприятия материал. В произвольном стиле изображается карта прочитанного, на основе которой пересказывается материал. Такой прием будет полезен тем, кому необходимо быстро выучить текст, но не обязательно воспроизводить его дословно. Яркий план, где все разложено по полочкам, хорошо отпечатается в памяти.
Методика:
- Выделите ключевую проблему. Напишите или нарисуйте ее, обведите в круг.
- Второстепенные мысли изображайте в виде ответвлений в любую сторону. Кто-то рисует вправо и влево, кто-то сверху вниз. Ограничений нет.
Получится развернутый план в удобном формате, опираясь на который легко пересказать материал своими словами. Тем, кто любит рисовать, можно заменять предложения картинками.
Это сделает процесс интереснее и даже поможет лучше заучить информацию.
Изучение родного языка происходит естественным способом.
 Мы запоминаем то, что слышим в детстве, постепенно накапливая знания и расширяя словарный запас. При изучении иностранного языка подход меняется и приходится осознанно запоминать слова, словосочетания и тексты. Рассмотрим несколько методов, которые можно дорабатывать и комбинировать между собой.
Мы запоминаем то, что слышим в детстве, постепенно накапливая знания и расширяя словарный запас. При изучении иностранного языка подход меняется и приходится осознанно запоминать слова, словосочетания и тексты. Рассмотрим несколько методов, которые можно дорабатывать и комбинировать между собой.Прием заключается в одновременном прослушивании и чтении текста и очень эффективен. Дело в том, что задействуются сразу два канала восприятия: зрительный и слуховой, а значит информация усваивается лучше. В современных учебниках английского практически каждый текст можно прослушать. Если задан отрывок из произведения, поможет аудиокнига.
Методика:
- Прочитайте текст и выпишите все незнакомые слова и фразы.
- Прослушайте рассказ частями и одновременно следите глазами по тексту.
- Делайте паузу после каждого предложения и повторяйте за диктором. Это поможет не только хорошо запомнить каждое из них, но и отработать произношение.
- Слушайте аудио-версию в любое свободное время: в транспорте, во время прогулок, перед сном. Вы и не заметите, как все отложится в памяти.
- Повторяйте прослушивание столько раз, сколько вам необходимо для запоминания.
 Вы и не заметите, как все отложится в памяти.
Вы и не заметите, как все отложится в памяти.Чем чаще слушать аудио — тем лучше. Тут все зависит от длины текста, его сложности и имеющегося времени. Метод полезен и для коррекции произношения.
Если вы не уверены, как произносится то или иное слово, прослушивание качественно начитанных предложений будет очень полезно.
Кстати, регулярное чтение произведений в оригинале с параллельным прослушиванием аудио к ним поможет запомнить большое количество слов. Изучение языка с практикой в чтении закладывает прочную и долговременную базу знаний. Важно выбирать интересную именно вам литературу, тогда процесс обучения превращается в увлекательное времяпрепровождение.
Какой бы способ вы ни выбрали, важно запоминать материал осознанно. Заучивание текста наизусть при изучении иностранного языка — это не сама цель, а всего лишь этап для ее достижения. Главное — начать использовать полученные знания в устной и письменной речи, а не оставлять их в голове мертвым грузом. То, что не используется, — быстро забывается.
То, что не используется, — быстро забывается.
Спасибо за Вашу оценку. Если хотите, чтобы Ваше имя стало известно автору, войдите на сайт как пользователь
и нажмите Спасибо еще раз. Ваше имя появится на этой стрнице.
Для быстрого усвоения текста используют разные методики запоминания. Один из самых эффективных метод вдумчивого чтения. Он хорошо подойдет для заучивания больших и маленьких объемов. Таким способом пользуются актеры, которым как никому другому важно знать как быстро выучить наизусть текст.
- Сначала медленно и внимательно читаем текст, который необходимо запомнить. Лучше прочитать его вслух. При чтении необходимо понять главную идею текста, его основной сюжет, чтобы можно было быстрее запомнить.
- Если объем материала большой разбиваем его на смысловые части. Каждую часть нужно выучить по отдельности, находя в них главные по смыслу слова или фразы. Это поможет в дальнейшем, восстановить весь текст по порядку.
- После этого нужно переписать весь текст, вручную. Делать это надо не спеша, вникая в суть написанного.
- После того как все будет переписано пересказываем что помним. Вспомнить надо мельчайшие детали, опираясь на ключевые слова. Если не удается вспомнить какой-то момент, лучше не подглядывать в записи, а постараться сделать это самостоятельно. Подсмотреть можно только в крайнем случае.
- Далее, переписываем второй раз только то, что вспомнили без подсказок.
- На последнем этапе еще раз внимательно перечитываем текст и пересказываем. Лучше сделать это перед сном.
 Делать это надо не спеша, вникая в суть написанного.
Делать это надо не спеша, вникая в суть написанного.Этот метод запоминания подходит для того, чтобы выучить текст дословно. Он поможет студентам, ученикам школы и всем кому нужно в короткое время знать как выучить большой объем информации. Таким способом пользуются актеры театра и кино, чтобы запомнить свои роли.
Для начала разберем какие типы восприятия информации могут быть.
По способу восприятия информации выделяют следующие типы:
- визуальный;
- звуковой;
- тактильный;
- вкусовой;
- обонятельный.

Полезная литература
Конечно, мы рассмотрели далеко не все способы и секреты быстрого и эффективного запоминания информации. При всем желании я бы их не уместила в одной статье. Так что если у вас еще остались вопросы, то ищите ответы на них в книгах:
- “Как читать, запоминать и никогда не забывать” Марк Тигелаар
- “Как запоминать (почти) все и всегда” Роб Иставэй
- “Где находится память? Искусство запоминать” Алан Льери
- “Тренируй свою память” Рюта Кавашима
- “100% память. 25 полезных методов запоминания за 10 тренировок” Екатерина Додонова
- “Вопросы памяти” Мишель Пон
Полный и подробный список литературы ищите в нашей статье “Книги по улучшению памяти”.
Не начинайте с зубрёжки!
У вас есть время изучить материал, выделить идеи и ключевые моменты текста. Составьте краткий конспект. Через пару дней попробуйте пересказать текст по своему конспекту.
- Если же у вас есть экзаменационные вопросы, то готовьте ответы по билетам. Напишите себе вопросы на отдельных листочках, тяните и отвечайте.
- Если вы располагаете достаточным количеством времени, то будет достаточно уделять подготовке 2 часа в день, при условии, что это время будет максимально эффективно использовано.
- Если же нет, то рекомендуется заниматься в школьном режиме: 40-45 минут подготовки и 10-15 минут перерыв. Во время перерыва постарайтесь отдохнуть, сменить вид деятельности: прогуляться, сделать разминку. Не грузите глаза и уши какой-то ненужной информацией.
 Напишите себе вопросы на отдельных листочках, тяните и отвечайте.
Напишите себе вопросы на отдельных листочках, тяните и отвечайте.Стоит учесть, что:
- продуктивнее запомнить информацию можно с 8 до 12 часов, а затем в 18-20 часов;
- проще запоминается информация, в которой вы заинтересованы: найдите для себя что-то интересное в тексте, который нужно выучить, и отталкивайтесь от этой темы;
- полезно тренироваться перед зеркалом: рассказывайте своему отражению в зеркале выученный материал, старайтесь выглядеть уверено.
Определите, какой тип памяти у вас больше развит: зрительный, аудиальный (слуховой) или моторный.
- Если лучше всего вы запоминаете то, что видите своими глазами, больше читайте, выделяйте цветным маркером или подчёркивайте для себя важные моменты в тексте.
- Аудиалам нужно читать и проговаривать информацию вслух или смотреть видео по данной теме.
- Обладатели моторной памяти должны запастись ручками и листочками, ведь они лучше запоминают ту информацию, которую записывают.
Для запоминания полезно готовить шпаргалки людям с любым типом памяти, даже если нельзя воспользоваться заготовками.
В последний день перескажите материал по опорному конспекту.
Онлайн-тренажеры для развития навыков запоминания
Напоследок я решила поделиться с вами сервисами для тренировки памяти. Их великое множество на просторах сети, новичок может запросто растеряться.
Викиум
Викиум – интернет-площадка, где собрано более 100 тренажеров для развития мозга, более 10 курсов разной направленности и несколько интересных тестов. Развивать можно память, внимание, мышление, логику, эмоциональный интеллект и многое другое.
Нам с вами в рамках работы над улучшением памяти будет интересен курс Мнемотехники. За 15 уроков вы освоите несколько эффективных методик запоминания, потренируетесь на специальных тренажерах и закрепите изученный материал на тестировании. Навыки, полученные на курсе, помогут вам запоминать до 100 объектов за час, держать в уме все пароли, легко учить иностранные языки и многое другое.
Битрейника
Битрейника – сервис с увлекательными играми для развития функций мозга. Если упражнения и тренажеры кажутся вам слишком скучными, то игры – это то, что надо. Они подойдут как детям, так и взрослым.
Расскажу про мои любимые:
- Нумизмат – игра для развития быстроты и точности памяти. Вам нужно будет запоминать и сравнивать монеты разного номинала из разных стран.
- Звукварь – задание аналогичное предыдущему, только сравнивать вам придется не монеты, а различные звуки. Слуховую память тоже нужно тренировать.
- Фразоскоп – помимо быстроты памяти, данная игра также поможет вам развить скорость чтения. На экране вы увидите строку, в которой некоторые слова откроются лишь на время. Ваша задача – заметить их и записать.
BrainApps
Сервис BrainApps – просто кладезь материалов по развитию мозга. Здесь есть тренажеры (аж целых 52 штуки!), развивающие курсы, интересные тесты, задачки, а также блог с научно-популярными статьями.
Потренируйтесь на тренажерах, пройдите Курс для развития памяти. На нем вы научитесь не только эффективно запоминать информацию, но и сохранять ее в памяти надолго.
4Brain
На платформе 4Brain, в отличие от трех предыдущих, нет никаких тренажеров. Зато там есть огромный выбор курсов – как платных, так и бесплатных. И целая куча умных статей и полезных книг.
Начните с курса Развитие памяти: уроки запоминания – он бесплатный и доступен даже без регистрации. На нем вы узнаете об устройстве памяти, освоите несколько техник и научитесь применять их на практике.
Если понравится, можете пройти продвинутый платный курс Мнемотехники. На нем много практики и хорошо структурированная нескучная теория.
На нем много практики и хорошо структурированная нескучная теория.
Если вам нравится формат онлайн-курсов, можете заглянуть в нашу подборку курсов по улучшению памяти. Там вы точно найдете подходящий вариант.
Алгоритм запоминания
В том, как можно быстро выучить большой объем информации, помогает следующий алгоритм действий:
- Необходимо разбить абзацы на предложения и отдельные части, а затем предложения на словосочетания. Количество блоков зависит от общего объема запоминаемого текста.
- Далее выделяется смысл каждого блока и характеризуется одним словом или предложением.
- К слову придумывается образ, запоминается последовательность образов.
- Можно взять маркер или карандаш и в тексте выделять информацию, которую, прежде всего, необходимо запомнить. Такие иллюстрации в тексте помогают запоминать, особенно визуалам.
- При использовании метода скобок следует распределять слова так, чтобы за каждым словом шел его синоним или антоним, то есть выстраивать синонимичные ряды и антонимичные ряды.
- Развитое периферийное зрение обеспечит возможность одновременно видеть больше слов. При этом чтение осуществляется не построчно, а сверху вниз. Психологи убеждены, что чем быстрее скорость чтения (на этом строятся методики скорочтения), тем лучшими окажутся результаты запоминания.

5 забавных способов быстрее читать на английском
Чтение на английском может быть трудным, особенно если это не ваш родной язык. Легко застрять на словах, которых вы не знаете, что может сильно вас замедлить.
Чтобы быстро и эффективно читать на английском языке, важно развивать навыки беглого просмотра и сканирования. Скимминг — это когда вы очень быстро читаете текст, чтобы получить общее представление о том, о чем он, а сканирование — это когда вы просматриваете текст, чтобы найти конкретную информацию.
Воспользуйтесь этими пятью советами, чтобы быстрее читать на английском языке, развивая навыки беглого просмотра и сканирования:
Установите лимит времени
У вас есть смартфон? Используйте таймер обратного отсчета, чтобы установить ограничение по времени, когда вы читаете что-то в первый раз. Начните с 30 секунд на 100 слов. Это отличный способ заставить себя не зацикливаться на поиске незнакомых слов. Когда вы знаете, что есть ограничение по времени, вам придется сосредоточиться на ключевых словах и фразах, которые вы делаете понимаете, чтобы получить общее значение текста.
Начните с 30 секунд на 100 слов. Это отличный способ заставить себя не зацикливаться на поиске незнакомых слов. Когда вы знаете, что есть ограничение по времени, вам придется сосредоточиться на ключевых словах и фразах, которые вы делаете понимаете, чтобы получить общее значение текста.
Важно установить ограничение по времени как для беглого просмотра, так и для сканирования, чтобы вы не застряли, пытаясь прочитать все детали в тексте. Установите еще более короткий лимит времени для сканирования (всего пару секунд на абзац), потому что при сканировании вам нужно быть более дисциплинированным, чтобы искать только ключевую информацию, которую вы хотите получить из текста.
Попробуйте придумать альтернативное название
Название обычно дает ключ к основной мысли, содержащейся в тексте.Если вы практикуете технику беглого просмотра, как описано выше, попробуйте скрыть заголовок, прочитать текст с ограничением по времени, а затем угадать, каким был бы заголовок. Если ваш придуманный заголовок похож на настоящий, значит, вы правильно поняли основную мысль текста.
Решите, какую информацию вы ищете, прежде чем читать
Это подсказка для сканирования. Если вы ищете информацию в тексте, например, ответ на конкретный вопрос или что-то, что вам нужно выяснить для собственного исследования, сначала убедитесь, что вы знаете, что ищете.Это число? Свидание? Имя? Или, может быть, что-то еще более конкретное, чем это? Когда вы знаете, какое слово или выражение вы ищете, вы сможете игнорировать информацию, которая вам не нужна.
Выделите фрагменты, чтобы вернуться к ним позже
Когда вы читаете бегло с ограничением по времени, могут быть интересные слова, значение которых вы просто не успеваете угадать из контекста. Важно не позволять этим словам замедлять вас, но если вы действительно хотите добавить их в свой словарный запас, просто выделяйте или подчеркивайте их во время чтения, тогда вы сможете вернуться к ним позже и либо угадать их значение, либо найти их. Подчеркивание или выделение этих слов означает, что вы можете забыть о них во время чтения, зная, что вы сможете уделить им больше внимания позже, когда будете читать текст снова.
Подчеркивание или выделение этих слов означает, что вы можете забыть о них во время чтения, зная, что вы сможете уделить им больше внимания позже, когда будете читать текст снова.
Читать в обратном направлении
Начните искать ключевые слова с нижней части текста, а затем продвигайтесь вверх. Это работает только для сканирования, но это отличный способ читать быстрее, потому что он заставляет вас не сосредотачиваться на каждом отдельном слове, а просто искать слова, которые дадут вам нужную информацию.
Перевернуть страницу вверх ногами
Опять же совет по сканированию (всю книгу вверх ногами не прочитаешь!). Это еще один способ сосредоточиться на поиске только нужной информации, не зацикливаясь на чтении всего текста. Это выглядит немного странно, делать это на публике, поэтому, вероятно, лучше всего практиковать это дома!
Итак, вот мои 5 советов, которые помогут вам быстрее читать по-английски. Используете ли вы какие-то из них или у вас есть какие-то свои? Дайте нам знать в комментариях ниже.
Как читать быстрее и понимать больше
Каждый день мы несколько раз читаем на родном языке, обычно очень быстро, чтобы понять знак или текстовое сообщение. Есть также несколько приемов, которые вы, естественно, используете в своем родном языке и которые позволяют вам быстро понимать письменный текст. Что это за приемы и как их применить к английскому языку?
Виды чтения
Существуют разные способы чтения, которыми мы все пользуемся на родном языке, обычно не замечая этого.
- Беглый просмотр – когда вы хотите быстро понять, о чем текст, вы быстро читаете несколько частей, не уделяя особого внимания каждой детали. Это тип чтения, который вы можете использовать, когда читаете новости в Интернете и хотите получить общее представление об истории.
- Сканирование — когда вы ищете определенную деталь (например, слово, имя или место), вы сканируете. Вы делаете это, когда ищете определенный продукт в прайс-листе или когда ищете имя или местоположение.
- Чтение для подробностей – когда вы читаете книгу на досуге, вы читаете каждое слово текста. Вы, вероятно, также делаете это, когда читаете инструкции о том, как что-то собрать или в рецепте.

Так что в следующий раз, когда вы будете читать на английском языке, подумайте, какой тип чтения вам нужен, потому что это поможет вам сэкономить время и даже поможет вам лучше понимать.
Заголовки и подзаголовки
Прежде чем читать любую статью, обязательно прочтите заголовок и все подзаголовки (дополнительные заголовки).Заголовки подобны указателям на дороге — они сообщают вам, где находятся важные вещи и куда вам нужно идти. Просто прочитав заголовок, вы можете составить представление о том, о чем статья, и предсказать, что вы найдете.
Первые строки абзацев
Если вам нужно прочитать довольно длинную статью, может очень помочь чтение первой строки каждого абзаца. Первая строка абзаца всегда представляет основную идею следующих нескольких строк (абзаца) и, таким образом, может помочь вам понять, что автор хочет сообщить. Это особенно полезный навык, когда вы сдаете экзамен и у вас не так много времени, чтобы подробно прочитать всю статью.
Это особенно полезный навык, когда вы сдаете экзамен и у вас не так много времени, чтобы подробно прочитать всю статью.
Ограничьте количество слов, которые вы ищете в словаре
Может возникнуть соблазн искать в словаре каждое новое слово, которое вы не понимаете. Но это занимает очень много времени и часто не помогает понять текст. Постарайтесь смириться с тем, что будет несколько слов, которых вы не знаете, но сможете понять их общее значение. Вы можете найти два или три слова, которые постоянно появляются и полностью блокируют ваше понимание.И когда вы будете искать эти слова, попробуйте сделать это, используя только английский словарь. Изучение слов на английском языке поможет вам запомнить их намного лучше.
Обращайте внимание на важные слова
В каждой фразе есть два-три слова, которые имеют решающее значение, а остальные менее важны. Научившись определять эти ключевые слова, вы сможете читать и понимать намного быстрее. Это потребует некоторой практики, но это хорошая привычка, чтобы попытаться научиться. Ключевыми словами обычно являются существительные, глаголы, прилагательные и наречия.Артикли и предлоги обычно являются менее важными словами с точки зрения общего значения. Вы заметите это намного быстрее, когда будете слушать, потому что говорящий ставит ударение (ударение) на самые важные слова в предложении. Например, в следующем предложении подчеркнуты ударные слова:
Ключевыми словами обычно являются существительные, глаголы, прилагательные и наречия.Артикли и предлоги обычно являются менее важными словами с точки зрения общего значения. Вы заметите это намного быстрее, когда будете слушать, потому что говорящий ставит ударение (ударение) на самые важные слова в предложении. Например, в следующем предложении подчеркнуты ударные слова:
Говорящий поставит ударение на самые важные слов.
Практика
Очевидно, что лучший способ научиться читать быстрее — это практиковаться.Но еще лучше практиковаться на подходящем для вас уровне. На Wall Street English у вас есть преимущество в том, что вы можете читать тексты, написанные для вашего точного уровня, так что это может быть немного сложно, но вы сможете понять. Тексты для чтения, которые мы используем, всегда включают в себя те же грамматические структуры и словарь, которые вы в настоящее время изучаете в своем подразделении, а также вводят некоторые новые термины и повторяют ранее изученные. Наш метод позволяет вам не находить слишком много слов, которые вы не понимаете, что делает чтение довольно неприятным.
Наш метод позволяет вам не находить слишком много слов, которые вы не понимаете, что делает чтение довольно неприятным.
Wall Street English Студенты, изучающие английский язык, также могут попробовать прочитать статьи, доступные в разделе «Практика» на панели инструментов. Они достаточно короткие и включают в себя быстрый тест на понимание в конце.
С помощью этих простых приемов каждый может научиться читать быстрее и больше понимать. Попробуйте применить их на практике прямо сейчас, прочитав некоторые из наших других статей в блоге .
Изучайте английский и говорите по-английски в App Store
Получите 7-дневную бесплатную пробную версию для новых пользователей с доступом к более чем 3000 онлайн-урокам.ELSA предлагает вам тренера по изучению языка с искусственным интеллектом, который поможет вам овладеть искусством разговорной речи на английском языке.
Говорите по-английски уверенно и четко!
—
ELSA (English Language Speech Assistant) — это приложение для изучения английского языка, которое поможет вам с произношением и словарным запасом, чтобы говорить по-английски уверенно и четко.
Более 10 МИЛЛИОНОВ студентов и работающих специалистов из более чем 130 стран использовали удостоенную наград технологию искусственного интеллекта распознавания речи ELSA для изучения английского языка.
> ELSA может помочь вам:
— Изучение английского языка для экзаменов IELTS, TOEFL, TOEIC и даже для ваших курсов ESL.
— Выучите основные разговоры и фразы на английском языке, прежде чем планировать поездку или отправиться в путешествие.
— Практикуйте английский язык, связанный с вашей профессиональной сферой, чтобы продвинуться по карьерной лестнице и свободно говорить по-английски.
> Откройте для себя свои разговорные навыки и оцените их!
— Пройдите речевой тест, написанный экспертами мирового уровня, и получите подробный отчет о сильных и слабых сторонах вашего произношения.Выучить новый язык легко, если вы знаете, на чем сосредоточиться.
— Научитесь эффективно произносить все английские звуки.
> Быстро станьте двуязычным
— Быстро выучите английский язык с помощью речевого тренера с искусственным интеллектом. Наш искусственный интеллект выберет лучшие небольшие уроки, чтобы помочь вам говорить как носитель языка и помочь вам с вашим английским акцентом.
Наш искусственный интеллект выберет лучшие небольшие уроки, чтобы помочь вам говорить как носитель языка и помочь вам с вашим английским акцентом.
— Практика из более чем 1600 уроков, охватывающих все звуки английского языка и более 40 тем, начиная от советов путешественникам и заканчивая собеседованиями, которые вы можете изучить.
— Используйте словарь английского языка ELSA, чтобы искать слова и практиковаться в их произношении.Вы сможете увидеть, как вы сравниваете себя с носителем языка, и получить обратную связь, чтобы стать лучше.
> Игры и устные вызовы!
— Практикуйте разговорный английский с помощью веселых языковых игр, которые охватывают основные навыки английского языка, такие как произношение, грамматика, словесное ударение, ритм, интонация, аудирование и разговор.
— После того, как вы произнесете фразу, в течение нескольких секунд вы сможете:
1) Сравнить свой голос с носителем языка и его английским акцентом
2) Получить инструкции, как исправить себя
3) Отзыв о других звуках через IPA с помощью расширенной функции обратной связи
4) Посмотрите видео, в котором показано, как создавать сложные звуки.
— Секрет двуязычия заключается в том, чтобы практиковаться небольшими порциями и получать по ходу содержательную обратную связь.
—
> Нам доверяют изучающие английский язык и отраслевые эксперты
— Почетное упоминание в категории «Искусственный интеллект и данные» конкурса Fast Company 2020 World Changing Ideas Awards
— Топ-100 влиятельных лиц в отчете о состоянии образовательных технологий по версии EdTech Digest 2020
— Великий Победитель SXSWEdu Launch 2016
— Золотой победитель в номинации «Лучшее цифровое обучающее приложение» по версии Reimagine Education 2016
— Образовательное приложение №1 на ProductHunt 2016
— Упоминается TechCrunch, Forbes, Mashable, VentureBeat, Yahoo, Сальмой Хайек и другими
—
> Подписка на ELSA Pro
Подпишитесь на ELSA Pro, чтобы получать уроки и функции премиум-класса! ELSA Pro обладает большими преимуществами, такими как:
— доступ к более чем 1600 урокам и более 40 основным темам, таким как: американская культура, путешествия 101, собеседования, ежедневные разговоры на английском языке, базовые фразы английского языка и многое другое!
— Индивидуальное обучение для улучшения вашего произношения.
— Инструменты отслеживания, которые помогут вам увидеть ваш прогресс во всех основных разговорных навыках.
Оплата будет снята с вашей учетной записи iTunes после подтверждения покупки. Подписки будут автоматически продлеваться, если они не будут отменены за 24 часа до окончания вашей текущей подписки. Чтобы отменить подписку, измените настройки автоматического продления в своей учетной записи iTunes.
—
Свяжитесь с нами
Электронная почта: [email protected]
Веб-сайт: https://www.elsaspeak.com/
Блог: https://medium.com/@elsaspeak
Условия предоставления услуг: http://elsaspeak.com/terms
Политика конфиденциальности: http://www.elsanow.io/privacy
Классификация текста FastText и представление слов
Введение
Если вы разместите обновление статуса на Facebook о покупке автомобиля, не удивляйтесь, если Facebook покажет вам рекламу автомобиля на вашем экране. Это не черная магия! Это Facebook использует текстовые данные, чтобы показывать вам более качественную рекламу.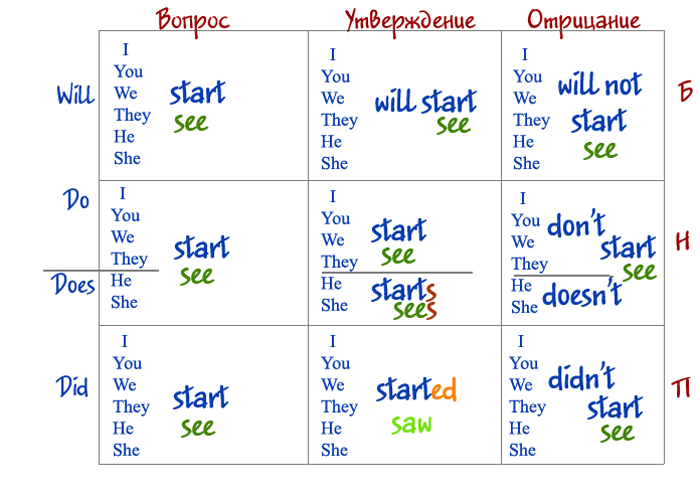
На картинке ниже изображен вызов, связанный с работой с текстовыми данными.
Что ж, вышеописанная попытка показать правильное объявление явно не удалась. Тем более важно уловить контекст, в котором это слово было использовано. Это распространенная проблема в задачах естественного языка обработки (NLP).
Одно слово с одинаковым написанием и произношением (омонимы) может использоваться в нескольких контекстах, и потенциальным решением вышеуказанной проблемы является вычисление представлений слов.
Теперь представьте задачу для Facebook.Facebook ежедневно обрабатывает огромное количество текстовых данных в виде обновлений статуса, комментариев и т. д. И для Facebook тем более важно использовать эти текстовые данные, чтобы лучше обслуживать своих пользователей. И использование этих текстовых данных, сгенерированных миллиардами пользователей, для вычисления представлений слов было очень трудоемкой задачей, пока Facebook не разработал свою собственную библиотеку FastText для представлений слов и классификации текста.
В этой статье мы увидим, как мы можем вычислять представления слов и выполнять классификацию текста, и все это за считанные секунды по сравнению с существующими методами, которым потребовались дни для достижения той же производительности.
Содержание
- Что такое FastText?
- Установка
- Реализация
- Изучение представлений слов
- Текстовая классификация
- Плюсы и минусы
- КОНЕЦ Примечания
Что такое FastText?
FastText — это библиотека, созданная исследовательской группой Facebook для эффективного изучения представлений слов и классификации предложений .
Эта библиотека завоевала большую популярность в сообществе NLP и является возможной заменой пакета gensim, который обеспечивает функциональность векторов Word и т. д. Если вы плохо знакомы с векторами Word и представлениями слов в целом, я предлагаю вам прочитать эта статья первая.
Но вопрос, который мы действительно должны задать: Чем FastText отличается от gensim Word Vectors?
FastText отличается тем, что векторы слов a.ka word2vec рассматривает каждое отдельное слово как наименьшую единицу, чье векторное представление должно быть найдено, но FastText предполагает, что слово состоит из n-грамм символов, например, солнечное состоит из [sun, sunn,sunny],[sunny ,unny,nny] и т. д., где n может принимать значения от 1 до длины слова. Это новое представление слова с помощью fastText обеспечивает следующие преимущества по сравнению с word2vec или перчаткой.
- Полезно найти векторное представление для редких слов. Поскольку редкие слова по-прежнему можно было разбить на n-граммы символов, они могли разделить эти n-граммы с обычными словами.Например, для модели, обученной на наборе новостных данных, медицинские термины, например: болезни, могут быть редкими словами.
- Он может дать векторное представление слов, отсутствующих в словаре (слова OOV), поскольку их также можно разбить на символьные n-граммы. И word2vec, и glove не могут предоставить никаких векторных представлений для слов, которых нет в словаре.
Например, для такого слова, как stupedofantabulouslyfantastic, , которого никогда не было ни в одном корпусе, gensim может вернуть любые два из следующих решений: а) нулевой вектор или б) случайный вектор с малой величиной.Но FastText может создавать векторы лучше, чем случайные, разбивая вышеуказанное слово на куски и используя векторы для этих кусков, чтобы создать окончательный вектор для слова. В данном конкретном случае конечный вектор может быть ближе к векторам фантастического и фантастического. Вложения n-грамм из - символов, как правило, работают лучше, чем word2vec и перчатка на небольших наборах данных.
 И word2vec, и glove не могут предоставить никаких векторных представлений для слов, которых нет в словаре.
И word2vec, и glove не могут предоставить никаких векторных представлений для слов, которых нет в словаре. Теперь мы рассмотрим шаги по установке библиотеки fastText ниже.
Установка
Чтобы в полной мере использовать библиотеку FastText, убедитесь, что выполнены следующие требования:
- ОС — MacOS или Linux Компилятор C++
- — gcc или clang
- Питон 2. 6+, numpy и scipy.
Если у вас нет вышеуказанных предварительных условий, я настоятельно рекомендую вам сначала установить вышеуказанные зависимости.
Чтобы установить FastText, введите код ниже:
-
клон git https://github.com/facebookresearch/fastText.git -
CD FastText -
сделать
Вы можете проверить правильность установки FastText, введя приведенную ниже команду в папке FastText.
./фасттекст
Если все было установлено правильно, вы должны увидеть список доступных команд для FastText в качестве вывода.
Реализация
Как указывалось ранее, FastText был разработан для двух конкретных целей: Изучение представления слов и Классификация текста . Мы подробно рассмотрим каждый из этих шагов. Давайте начнем с изучения словесных представлений.
Изучение представлений слов
Слова в их естественной форме вообще нельзя использовать ни для одной задачи машинного обучения.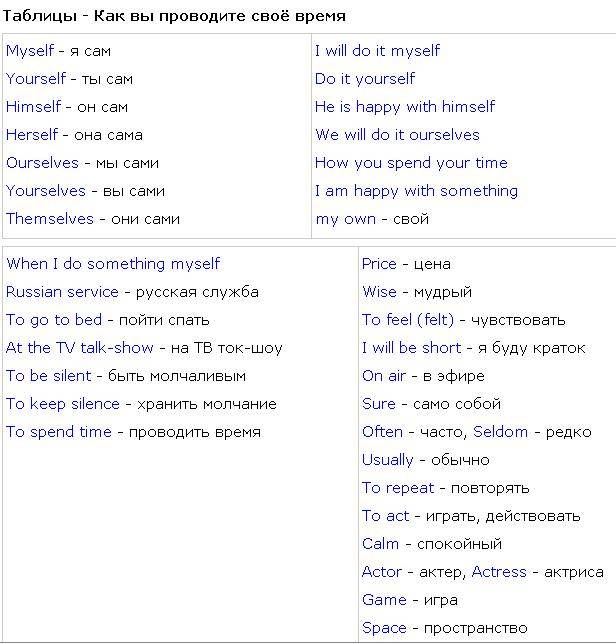 Один из способов использования слов состоит в том, чтобы преобразовать эти слова в некоторые представления, которые охватывают некоторые атрибуты слова. Это аналогично описанию человека как — [‘рост’: 5,10, «вес»: 75, «цвет»: «темный» и т. д.], где рост, вес и т. д. являются атрибутами человека. Точно так же словесные представления охватывают некоторые абстрактные атрибуты слов таким же образом, как похожие слова имеют тенденцию иметь схожие словесные представления. В основном для разработки векторов слов используются два метода — Skipgram и CBOW.
Один из способов использования слов состоит в том, чтобы преобразовать эти слова в некоторые представления, которые охватывают некоторые атрибуты слова. Это аналогично описанию человека как — [‘рост’: 5,10, «вес»: 75, «цвет»: «темный» и т. д.], где рост, вес и т. д. являются атрибутами человека. Точно так же словесные представления охватывают некоторые абстрактные атрибуты слов таким же образом, как похожие слова имеют тенденцию иметь схожие словесные представления. В основном для разработки векторов слов используются два метода — Skipgram и CBOW.
Мы увидим, как мы можем реализовать оба этих метода для изучения векторных представлений для примера текстового файла с помощью fasttext.
Изучение представлений слов с использованием моделей Skipgram и CBOW
- Скипграм
. /fasttext skipgram -входной файл.txt -выходная модель - CBOW
./fasttext cbow -входной файл.txt -выходная модель
Давайте рассмотрим параметры, определенные выше, пошагово для облегчения понимания.
./fasttext — используется для вызова библиотеки FastText.
skipgram/cbow — Здесь вы указываете, следует ли использовать skipgram или cbow для создания представлений слов.
-input — это имя параметра, который указывает следующее слово, которое будет использоваться в качестве имени файла, используемого для обучения. Этот аргумент следует использовать как есть.
data.txt — образец текстового файла, на котором мы хотим обучить модель skipgram или cbow.Измените это имя на имя имеющегося у вас текстового файла.
-output — это имя параметра, который определяет следующее слово, которое будет использоваться в качестве имени создаваемой модели. Этот аргумент следует использовать как есть.
модель — это имя созданной модели.
Выполнение приведенной выше команды создаст два файла с именами model.bin и model.vec. model. bin содержит параметры модели, словарь и гиперпараметры и может использоваться для вычисления векторов слов. model.vec — это текстовый файл, содержащий векторы слов для одного слова в строке.
Теперь, когда мы создали наши собственные векторы слов, давайте посмотрим, сможем ли мы выполнять некоторые общие задачи, такие как печать векторов слов для слова, поиск похожих слов, аналогий и т. д., используя эти векторы слов.
Печать словесных векторов слова
Чтобы получить векторы слов для слова или набора слов, сохраните их в текстовом файле. Например, вот пример текстового файла с именем query.txt, который содержит несколько случайных слов. Мы получим векторное представление этих слов, используя модель, которую мы обучили выше.
./fasttext print-word-vectors model.bin < query.txt
Чтобы проверить векторы слов на наличие одного слова без сохранения в файл, вы можете сделать
эхо "слово" | . /fasttext print-word-vectors model.bin
/fasttext print-word-vectors model.bin
Поиск похожих слов
Вы также можете найти слова, наиболее похожие на заданное слово.Эта функциональность обеспечивается параметром nn . Давайте посмотрим, как мы можем найти слова, наиболее похожие на «счастливый».
./fasttext nn модель.bin
После ввода вышеуказанной команды терминал попросит вас ввести слово запроса.
счастливый
по 0,183204
быть 0,0822266
обучение 0,0522333
0,0404951
подобное 0,036328
и 0,0248938
0,0229364 109
слово 7200138793
синтаксический -0,00251774
Приведенный выше результат возвращен для слов, наиболее похожих на happy. Интересно, что эту функцию можно использовать и для исправления правописания. Например, когда вы вводите неправильное написание, оно показывает правильное написание слова, если оно встречается в обучающем файле.
слово
слова 0,481091
слов. 0,389373
слов 0,370469
word2vec 0,354458
еще 0,345805
и 0,333076
с 0.325603
в 0,268813
Word2vec 0,26591
или 0,263104
Аналоги
вектора слов FastText также можно использовать в задаче аналогии типа, что такое C, что B означает A. Здесь A, B и C - слова.
Функциональность аналогов обеспечивается параметрами аналогий. Давайте посмотрим на это с помощью примера.
./fasttext аналогии model.bin
Приведенная выше команда попросит ввести слова в форме A-B+C, но нам просто нужно ввести три слова, разделенные пробелом.
счастливый грустный сердитый
от 0.199229
0.187058
контекст 0.158968
A 0.151884
AS 0.142561
AS 0.142561
0.136407
или 0.119725
и 0.117082
и 0.113304
- 0,0996916
Обучение на очень большом корпусе даст лучшие результаты.
Текстовая классификация
Как следует из названия, классификация текстов помечает каждый документ в тексте определенным классом. Анализ тональности и классификация электронной почты — классические примеры классификации текста.В эту эпоху технологий каждый день генерируются миллионы цифровых документов. Это стоило бы огромного количества времени, а также человеческих усилий, чтобы классифицировать их по разумным категориям, таким как спам и не спам, важные и неважные и так далее. Здесь нам на помощь приходят методы классификации текстов НЛП. Давайте посмотрим, как это сделать, выполняя практическую работу на основе задачи анализа настроений. Я взял данные для этого анализа с kaggle.
Прежде чем мы приступим к выполнению, хочу предупредить нас об тренировочном файле.Формат текстового файла по умолчанию, на котором мы хотим обучить нашу модель, должен быть _ _ label _ _
Где _ _label_ _ — префикс класса, а  Также вокруг документа не должно быть кавычек и все в одном документе должно быть на одной строке.
Также вокруг документа не должно быть кавычек и все в одном документе должно быть на одной строке.
На самом деле причина, по которой я выбрал эти данные для этой статьи, заключается в том, что данные уже доступны именно в требуемом формате по умолчанию.Если вы новичок в FastText и впервые реализуете классификацию текста в FastText, я настоятельно рекомендую использовать данные, упомянутые выше.
Если ваши данные имеют другие форматы метки, не беспокойтесь. FastText позаботится об этом, как только вы передадите подходящий аргумент. Мы увидим, как это сделать через мгновение. Просто придерживайтесь статьи.
После этого брифинга о классификации текста давайте перейдем к части реализации. Мы будем использовать поезд.ft для обучения модели и файл test.ft для прогнозирования.
#обучение классификатора
./fasttext supervisord -input train.ft.txt -output model_kaggle -label __label__
Здесь параметры те же, что и при создании словесных представлений.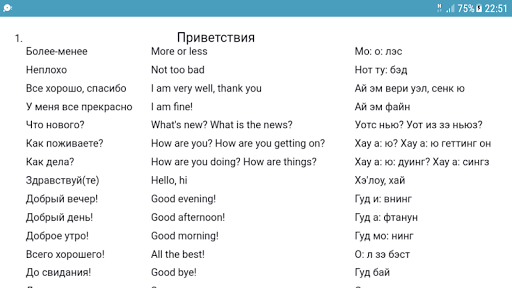 Единственным дополнительным параметром является -метка. Этот аргумент определяет формат указанной метки. Загруженный файл содержит метки с префиксом __label__.
Единственным дополнительным параметром является -метка. Этот аргумент определяет формат указанной метки. Загруженный файл содержит метки с префиксом __label__.
Если вы не хотите использовать параметры по умолчанию для обучения модели, их можно указать во время обучения. Например, если вы хотите явно указать скорость обучения процесса обучения, вы можете использовать аргумент -lr , чтобы указать скорость обучения.
./fasttext под наблюдением -input train.ft.txt -output model_kaggle -label __label__ -lr 0,5
Другие доступные параметры, которые можно настроить: –
- -lr : скорость обучения [0.1]
- -lrUpdateRate : изменить скорость обновления для скорости обучения [100]
- -dim : размер векторов слов [100]
- -ws : размер контекстного окна [5]
- -эпоха : количество эпох [5]
- -neg : количество отобранных негативов [5]
- -loss : функция потерь {ns, hs, softmax} [ns]
- -поток : количество потоков [12]
- -pretrainedVectors : предварительно обученные векторы слов для контролируемого обучения []
- -saveOutput : следует ли сохранять параметры вывода [0]
Значения в квадратных скобках [] представляют собой значения переданных параметров по умолчанию.
# Проверка результата
./fasttext test model_kaggle.bin test.ft.txt
N 400000
[электронная почта защищена] 0,916
[электронная почта защищена] 0,916
Количество примеров: 400000
[email protected] – точность
[email protected] – отзыв
# Предсказание на тестовом наборе данных
./fasttext Predict model_kaggle.bin test.ft.txt
# Предсказание первых 3 меток
./fasttext прогнозировать model_kaggle.bin test.ft.txt 3
Вычисление векторов предложений (под наблюдением)
Эту модель также можно использовать для вычисления векторов предложений. Давайте посмотрим, как мы можем вычислить векторы предложений, используя следующие команды.
echo "это пример предложения" | ./fasttext print-sentence-vectors model_kaggle.bin
0,008204 0,016523 -0,028591 -0,0019852 -0,0043028 0,044917 -0,055856 -0,057333 0,16713 0,079895 0. 0034849 0.052638 0,10069 0,0098551 -0,073566 -0,016581 -0,023504 -0,027494 -0,070747 -0,028199 0,068043 0,082783 0,051088 -0,033781 -0,024244 -0,031605 0,091783 -0,029228 -0,017851 0,047316 0,013819 0,072576 -0,004047 -0,10553 -0,12998 0,021245 0,021346 0,0019761 -0,0068286 0,012595 0,0016618 0,0088362 0,02793 0,031308 0,035874 -0.0078695 0.019297 0.032703 0.015868 0.025272 -0.035632 0,031488 -0,027837 0.020735 -094 0.020735 -094 0.020739 -094 0.0055139 0.009132 -0.0042779 0,008727 -0,034485 0,027236 0,0 0.018552 -0,019416 0,0094632 0,0039224 0,012285 -0,0040765 -0,0024119 -0,0023406 0,0025112 0,0010826 0,0006142 -0,0022772 0,0009227 0,016582 0,011488 0,019017 0,00014679 -0,0043627 -0,003167 0,0016855 0,0050221 -0,002838 -0,00078066 0,0015846 0,0016942 -0,0018429 -0,04923 0,056873 0,019886 0,043118 -0,002863 -0,033149 -0,0087295 -0,0030569 0,0063657 0,0016887 -0,0022234
0034849 0.052638 0,10069 0,0098551 -0,073566 -0,016581 -0,023504 -0,027494 -0,070747 -0,028199 0,068043 0,082783 0,051088 -0,033781 -0,024244 -0,031605 0,091783 -0,029228 -0,017851 0,047316 0,013819 0,072576 -0,004047 -0,10553 -0,12998 0,021245 0,021346 0,0019761 -0,0068286 0,012595 0,0016618 0,0088362 0,02793 0,031308 0,035874 -0.0078695 0.019297 0.032703 0.015868 0.025272 -0.035632 0,031488 -0,027837 0.020735 -094 0.020735 -094 0.020739 -094 0.0055139 0.009132 -0.0042779 0,008727 -0,034485 0,027236 0,0 0.018552 -0,019416 0,0094632 0,0039224 0,012285 -0,0040765 -0,0024119 -0,0023406 0,0025112 0,0010826 0,0006142 -0,0022772 0,0009227 0,016582 0,011488 0,019017 0,00014679 -0,0043627 -0,003167 0,0016855 0,0050221 -0,002838 -0,00078066 0,0015846 0,0016942 -0,0018429 -0,04923 0,056873 0,019886 0,043118 -0,002863 -0,033149 -0,0087295 -0,0030569 0,0063657 0,0016887 -0,0022234
Плюсы и минусы FastText
Как и у любой разрабатываемой библиотеки, у нее есть свои плюсы и минусы. Сформулируем их явно.
Сформулируем их явно.
Плюсы
- Библиотека работает на удивление очень быстро по сравнению с другими методами достижения той же точности. Вот результат, опубликованный исследовательской группой Facebook в поддержку аргумента.
- векторов предложений (контролируемых) можно легко вычислить.
- fastText лучше работает с небольшими наборами данных по сравнению с gensim.
- fastText превосходит gensim с точки зрения синтаксической производительности и одинаково хорош в случае семантической производительности.
Минусы
- Это не отдельная библиотека для НЛП, поскольку для этапов предварительной обработки потребуется другая библиотека.
- Хотя эта библиотека имеет реализацию на Python. Официально не поддерживается.
Проекты
Теперь пришло время сделать решительный шаг и поиграть с некоторыми другими реальными наборами данных. Итак, вы готовы принять вызов? Ускорьте свой путь в НЛП, выполнив следующие практические задачи:
.
Конечные примечания
Целью этой статьи было ознакомить вас с библиотекой FastText как альтернативой модели word2vec, а также дать вам возможность создать свое первое векторное представление и модель классификации текста.
Для тех, кто хочет более подробно изучить разницу в производительности fastText и gensim, вы можете посетить эту ссылку, где исследователь провел сравнение, используя блокнот Jupyter и некоторые стандартные текстовые наборы данных.
Пожалуйста, не стесняйтесь попробовать эту библиотеку и поделиться своим опытом в комментариях ниже.
Учитесь, вовлекайтесь, соревнуйтесь и нанимайтесь на работу
РодственныеРабота с библиотекой Facebook FastText
Это 20-я статья в моей серии статей о Python для НЛП.В последних нескольких статьях мы изучали методы глубокого обучения для выполнения различных задач машинного обучения, и вы также должны быть знакомы с концепцией встраивания слов. Встраивание слов — это способ преобразования текстовой информации в числовую форму, которую, в свою очередь, можно использовать в качестве входных данных для статистических алгоритмов. В моей статье о встраивании слов я объяснил, как мы можем создавать наши собственные вложения слов и как мы можем использовать встроенные вложения слов, такие как GloVe.
Встраивание слов — это способ преобразования текстовой информации в числовую форму, которую, в свою очередь, можно использовать в качестве входных данных для статистических алгоритмов. В моей статье о встраивании слов я объяснил, как мы можем создавать наши собственные вложения слов и как мы можем использовать встроенные вложения слов, такие как GloVe.
В этой статье мы собираемся изучить FastText, который является еще одним чрезвычайно полезным модулем для встраивания слов и классификации текста.FastText был разработан Facebook и показал отличные результаты во многих задачах НЛП, таких как обнаружение семантического сходства и классификация текста.
В этой статье мы кратко рассмотрим библиотеку FastText. Эта статья разделена на два раздела. В первом разделе мы увидим, как библиотека FastText создает векторные представления, которые можно использовать для поиска семантического сходства между словами. Во втором разделе мы увидим применение библиотеки FastText для классификации текста.
FastText для семантического сходства
FastText поддерживает модели Continuous Bag of Words и Skip-Gram. В этой статье мы реализуем модель skip-gram для изучения векторного представления слов из статей Википедии об искусственном интеллекте, машинном обучении, глубоком обучении и нейронных сетях. Поскольку эти темы очень похожи, мы выбрали эти темы, чтобы иметь значительный объем данных для создания корпуса. Вы можете добавить больше тем подобного характера, если хотите.
В качестве первого шага нам нужно импортировать необходимые библиотеки. Мы будем использовать библиотеку Википедии для Python, которую можно загрузить с помощью следующей команды:
. $ pip установить википедию
Импорт библиотек
Следующий скрипт импортирует необходимые библиотеки в наше приложение:
из keras.preprocessing.text import Tokenizer
из gensim.models.fasttext импортировать FastText
импортировать numpy как np
импортировать матплотлиб. pyplot как plt
импортировать нлтк
пунктуация импорта строки
из nltk.corpus импортировать стоп-слова
из nltk.tokenize импортировать word_tokenize
из nltk.stem импортировать WordNetLemmatizer
из nltk.tokenize импортировать sent_tokenize
из nltk импортировать WordPunctTokenizer
импортировать википедию
импортировать нлтк
nltk.download('пункт')
nltk.download('wordnet')
nltk.download('стоп-слова')
en_stop = set(nltk.corpus.stopwords.words('английский'))
%matplotlib встроенный
 pyplot как plt
импортировать нлтк
пунктуация импорта строки
из nltk.corpus импортировать стоп-слова
из nltk.tokenize импортировать word_tokenize
из nltk.stem импортировать WordNetLemmatizer
из nltk.tokenize импортировать sent_tokenize
из nltk импортировать WordPunctTokenizer
импортировать википедию
импортировать нлтк
nltk.download('пункт')
nltk.download('wordnet')
nltk.download('стоп-слова')
en_stop = set(nltk.corpus.stopwords.words('английский'))
%matplotlib встроенный
pyplot как plt
импортировать нлтк
пунктуация импорта строки
из nltk.corpus импортировать стоп-слова
из nltk.tokenize импортировать word_tokenize
из nltk.stem импортировать WordNetLemmatizer
из nltk.tokenize импортировать sent_tokenize
из nltk импортировать WordPunctTokenizer
импортировать википедию
импортировать нлтк
nltk.download('пункт')
nltk.download('wordnet')
nltk.download('стоп-слова')
en_stop = set(nltk.corpus.stopwords.words('английский'))
%matplotlib встроенный
Вы можете видеть, что мы используем модуль FastText от gensim .библиотека models.fasttext . Для представления слов и семантического сходства мы можем использовать модель Gensim для FastText. Эта модель может работать в Windows, однако для классификации текста нам придется использовать платформу Linux. Мы увидим это в следующем разделе.
Парсинг статей из Википедии
На этом шаге мы соберем необходимые статьи из Википедии. Посмотрите на скрипт ниже:
Artificial_intelligence = wikipedia. page("Искусственный интеллект").content
машинное_обучение = википедия.страница("Машинное обучение").content
deep_learning = wikipedia.page("Глубокое обучение").content
нейронная_сеть = wikipedia.page("Нейронная сеть").content
искусственный_интеллект = send_tokenize(искусственный_интеллект)
machine_learning = send_tokenize(machine_learning)
deep_learning = send_tokenize(глубокое_обучение)
нейронная_сеть = send_tokenize (нейронная_сеть)
искусственный_интеллект.расширить(машинное_обучение)
Artificial_intelligence.extend(глубокое_обучение)
искусственный_интеллект.расширить(нейронная_сеть)
 page("Искусственный интеллект").content
машинное_обучение = википедия.страница("Машинное обучение").content
deep_learning = wikipedia.page("Глубокое обучение").content
нейронная_сеть = wikipedia.page("Нейронная сеть").content
искусственный_интеллект = send_tokenize(искусственный_интеллект)
machine_learning = send_tokenize(machine_learning)
deep_learning = send_tokenize(глубокое_обучение)
нейронная_сеть = send_tokenize (нейронная_сеть)
искусственный_интеллект.расширить(машинное_обучение)
Artificial_intelligence.extend(глубокое_обучение)
искусственный_интеллект.расширить(нейронная_сеть)
page("Искусственный интеллект").content
машинное_обучение = википедия.страница("Машинное обучение").content
deep_learning = wikipedia.page("Глубокое обучение").content
нейронная_сеть = wikipedia.page("Нейронная сеть").content
искусственный_интеллект = send_tokenize(искусственный_интеллект)
machine_learning = send_tokenize(machine_learning)
deep_learning = send_tokenize(глубокое_обучение)
нейронная_сеть = send_tokenize (нейронная_сеть)
искусственный_интеллект.расширить(машинное_обучение)
Artificial_intelligence.extend(глубокое_обучение)
искусственный_интеллект.расширить(нейронная_сеть)
Чтобы очистить страницу Википедии, мы можем использовать метод page из модуля wikipedia .Имя страницы, которую вы хотите удалить, передается в качестве параметра методу страницы . Метод возвращает объект WikipediaPage , который затем можно использовать для извлечения содержимого страницы с помощью атрибута content , как показано в приведенном выше сценарии.
Собранный контент с четырех страниц Википедии затем разбивается на предложения с помощью метода sent_tokenize . Метод sent_tokenize возвращает список предложений. Предложения для четырех страниц размечаются отдельно.Наконец, предложения из четырех статей соединяются вместе с помощью метода extend .
Предварительная обработка данных
Следующим шагом будет очистка наших текстовых данных путем удаления пунктуации и цифр. Мы также преобразуем данные в нижний регистр. Слова в наших данных будут лемматизированы до корневой формы. При этом стоп-слова и слова длиной менее 4 будут удалены из корпуса.
Функция preprocess_text , как определено ниже, выполняет задачи предварительной обработки.б\с+', '', документ)
документ = документ.нижний()
токены = document.split()
tokens = [stemmer.lemmatize(word) для слова в токенах]
tokens = [слово в токенах, если слово не в en_stop]
токены = [слово в слово в токенах, если длина (слово) > 3] preprocessed_text = ' '. join(токены) вернуть предварительно обработанный_текст
join(токены) вернуть предварительно обработанный_текст
Давайте посмотрим, выполняет ли наша функция желаемую задачу, предварительно обработав фиктивное предложение:
send = preprocess_text("Искусственный интеллект — самая передовая технология современности")
распечатать (отправлено)
final_corpus = [preprocess_text(sentence) для предложения в искусственном_интеллекте, если предложение.полоса() !='']
word_punctuation_tokenizer = nltk.WordPunctTokenizer()
word_tokenized_corpus = [word_punctuation_tokenizer.tokenize(sent) для отправки в final_corpus]
Предварительно обработанное предложение выглядит так:
наличие передовых технологий искусственного интеллекта
Вы можете видеть, что знаки препинания и стоп-слова были удалены, а предложения лемматизированы. Кроме того, слова длиной менее 4, такие как «эра», также были удалены.Эти варианты были выбраны случайным образом для этого теста, поэтому вы можете допустить в корпус слова меньшей или большей длины.
Создание словесного представления
Мы предварительно обработали наш корпус. Теперь пришло время создать представления слов с помощью FastText. Давайте сначала определим гиперпараметры для нашей модели FastText:
embedding_size = 60
размер_окна = 40
минимальное_слово = 5
пониженная_выборка = 1e-2
Здесь embedding_size — размер вектора встраивания.Другими словами, каждое слово в нашем корпусе будет представлено в виде 60-мерного вектора. window_size — это размер количества слов, встречающихся до и после слова, на основе которого будут изучены представления слова для слова. Это может показаться сложным, однако в модели пропуска граммы мы вводим слово в алгоритм, а на выходе получаем контекстные слова. Если размер окна равен 40, для каждого входа будет 80 выходов: 40 слов, стоящих перед входным словом, и 40 слов, стоящих после входного слова.Вложения слов для входного слова изучаются с использованием этих 80 выходных слов.
Следующим гиперпараметром является min_word , который указывает минимальную частоту слова в корпусе, для которого будут генерироваться представления слов. Наконец, наиболее часто встречающееся слово будет уменьшено до числа, указанного в атрибуте down_sampling .
Давайте теперь создадим нашу модель FastText для представления слов.
%%время
ft_model = FastText (word_tokenized_corpus,
размер = размер_встраивания,
окно=размер_окна,
min_count=min_word,
образец = пониженная_выборка,
сг=1,
итэр=100)
Все параметры в приведенном выше скрипте говорят сами за себя, кроме sg .Параметр sg определяет тип модели, которую мы хотим создать. Значение 1 указывает, что мы хотим создать модель пропуска грамм. В то время как ноль указывает модель набора слов, которая также является значением по умолчанию.
Выполнить приведенный выше сценарий. Это может занять некоторое время. На моей машине статистика времени выполнения приведенного выше кода выглядит следующим образом:
Процессорное время: пользователь 1 мин 45 с, система: 434 мс, всего: 1 мин 45 с
Время стены: 57,2 с
Давайте теперь посмотрим на словесное представление слова «искусственный».Для этого вы можете использовать метод wv объекта FastText и передать ему имя слова внутри списка.
печать (ft_model.wv ['искусственный'])
Вот вывод:
[-3.7653010e-02 -4.5558015e-01 3.2035065e-01 -1.5289043e-01
4.0645871e-02 -1.8946664e-01 7.0426887e-01 2.8806925e-01
-1.8166199e-01 1.7566417e-01 1.1522485e-01 -3.6525184e-01
-6.4378887e-01 -1.6650060e-01 7.4625671e-01 -4.8166099e-01
2.0884991e-01 1.8067230e-01 -6.2647951e-01 2.7614883e-01
-3.6478557e-02 1.4782918e-02 -3.3124462e-01 1.9372456e-01
4.3028224э-02 -8. 2326338э-02 1.0356739э-01 4.0792203э-01
-2.0596240e-02 -3.5974573e-02 9.9928051e-02 1.7191900e-01
-2.1196717e-01 6.4424530e-02 -4.4705093e-02 9.73e-02
-2.8846195e-01 8.8607501e-03 1.6520244e-01 -3.6626378e-01
-6.2017748e-04 -1.5083785e-01 -1.7499258e-01 7.1994811e-02
-1.9868813e-01 -3.1733567e-01 1.9832127e-01 1.2799081e-01
-7.6522082э-01 5.2335665э-02 -4.5766738э-01 -2.7947658э-01
3.78э-03 -3.8761377э-01 -9.3001537э-02 -1.7128626э-01
-1,2923178e-01 3,9627206e-01 -3,6673656e-01 2,2755004e-01]
 2326338э-02 1.0356739э-01 4.0792203э-01
-2.0596240e-02 -3.5974573e-02 9.9928051e-02 1.7191900e-01
-2.1196717e-01 6.4424530e-02 -4.4705093e-02 9.73
2326338э-02 1.0356739э-01 4.0792203э-01
-2.0596240e-02 -3.5974573e-02 9.9928051e-02 1.7191900e-01
-2.1196717e-01 6.4424530e-02 -4.4705093e-02 9.73В выводе выше вы можете увидеть 60-мерный вектор для слова "искусственный"
Давайте теперь найдем топ-5 слов, наиболее похожих на слова «искусственный», «интеллект», «машина», «сеть», «рекуррентный», «глубокий». Вы можете выбрать любое количество слов. Следующий скрипт печатает указанные слова вместе с 5 наиболее похожими словами.
семантически_подобные_слова = {слова: [элемент[0] для элемента в ft_model.wv.most_similar([слова], topn=5)]
для слов в ['искусственный', 'интеллектуальный', 'машина', 'сеть', 'рекуррентный', 'глубокий']}
для k,v в семантически_подобных_словах. items():
печать (к+":"+стр (v))
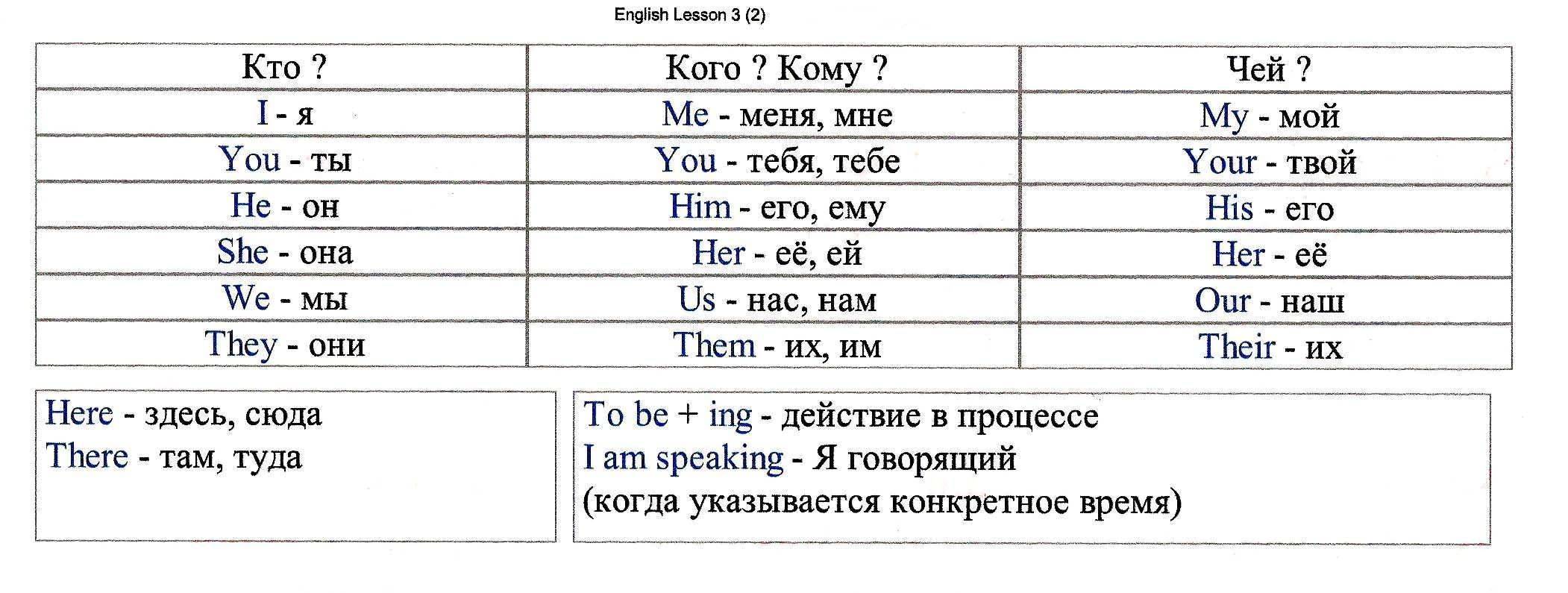 items():
печать (к+":"+стр (v))
items():
печать (к+":"+стр (v))
Вывод выглядит следующим образом:
искусственный: ['интеллект', 'вдохновленный', 'книжный', 'академический', 'биологический']
интеллект: ['искусственный', 'человеческий', 'народный', 'интеллектуальный', 'общий']
машина: ['этика', 'обучение', 'озабоченность', 'аргумент', 'интеллект']
сеть: ['нейронная', 'прямая', 'глубокая', 'обратное распространение', 'скрытая']
рекуррентный: ['rnns', 'короткий', 'шмидхубер', 'показанный', 'упреждающий']
глубокий: ['сверточный', 'речевой', 'сетевой', 'генеративный', 'нейронный']
Мы также можем найти косинусное сходство между векторами для любых двух слов, как показано ниже:
печать(ft_model.wv.similarity(w1='искусственный', w2='интеллектуальный'))
На выходе отображается значение «0,7481». Значение может быть от 0 до 1. Чем выше значение, тем выше сходство.
Визуализация сходства слов
Хотя каждое слово в нашей модели представлено в виде 60-мерного вектора, мы можем использовать метод анализа основных компонентов, чтобы найти два основных компонента. Затем два основных компонента можно использовать для построения слов в двухмерном пространстве. Однако сначала нам нужно создать список всех слов в словаре
Затем два основных компонента можно использовать для построения слов в двухмерном пространстве. Однако сначала нам нужно создать список всех слов в словаре semantically_similar_words .Это делает следующий скрипт:
из импорта sklearn.decomposition PCA
all_similar_words = sum([[k] + v для k, v в семантически_подобных_словах.items()], [])
печать (все_подобные_слова)
печать (тип (все_подобные_слова))
печать (длина (all_similar_words))
В приведенном выше сценарии мы перебираем все пары ключ-значение в словаре семантически_подобных_слов . Каждый ключ в словаре является словом. Соответствующее значение представляет собой список всех семантически похожих слов.Поскольку мы нашли 5 наиболее похожих слов для списка из 6 слов, т. е. «искусственный», «интеллект», «машина», «сеть», «повторяющийся», «глубокий», вы увидите, что в списке будет 30 элементов. список all_similar_words .
Затем мы должны найти векторы слов для всех этих 30 слов, а затем использовать PCA, чтобы уменьшить размерность векторов слов с 60 до 2. Затем мы можем использовать метод
Затем мы можем использовать метод plt , который является псевдонимом метода . matplotlib.pyplot для построения слов в двумерном векторном пространстве.
Выполните следующий сценарий, чтобы визуализировать слова:
word_vectors = ft_model.wv[all_similar_words]
PCA = PCA (n_components = 2)
p_comps = pca.fit_transform(word_vectors)
word_names = все_подобные_слова
plt.figure(figsize=(18, 10))
plt.scatter(p_comps[:, 0], p_comps[:, 1], c='красный')
для word_names, x, y в zip(word_names, p_comps[:, 0], p_comps[:, 1]):
plt.annotate(word_names, xy=(x+0,06, y+0,03), xytext=(0, 0), textcoords='точки смещения')
Вывод вышеуказанного скрипта выглядит следующим образом:
Вы можете видеть, что слова, которые часто встречаются вместе в тексте, близки друг к другу и в двухмерной плоскости.Например, слова «глубокий» и «сеть» почти совпадают. Точно так же слова «прямая связь» и «обратное распространение» также очень близки.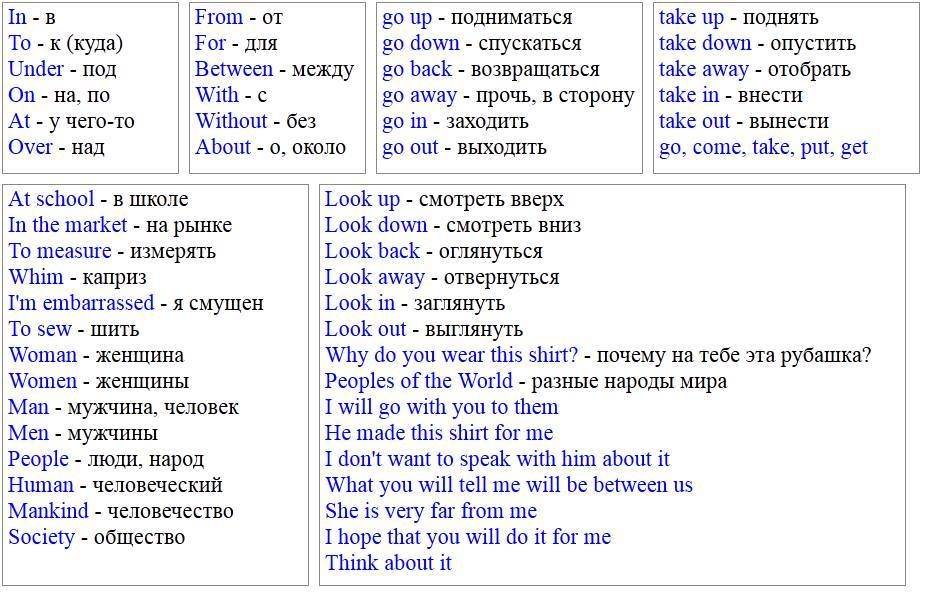
Теперь мы знаем, как создавать вставки слов с помощью FastText. В следующем разделе мы увидим, как FastText можно использовать для задач классификации текста.
FastText для классификации текста
Классификация текста относится к классификации текстовых данных по предопределенным категориям на основе содержания текста. Анализ тональности, обнаружение спама и обнаружение тегов — вот некоторые из наиболее распространенных примеров использования классификации текста.
Модуль классификации текста FastTextможет работать только в Linux или OSX. Если вы пользователь Windows, вы можете использовать Google Colaboratory для запуска модуля классификации текста FastText. Все сценарии в этом разделе были запущены с помощью Google Colaboratory.
Набор данных
Набор данных для этой статьи можно загрузить по этой ссылке Kaggle. Набор данных содержит несколько файлов, но нас интересует только файл yelp_review.csv . В файле более 5.2 миллиона отзывов о различных предприятиях, включая рестораны, бары, стоматологов, врачей, салоны красоты и т. д. Однако мы будем использовать только первые 50 000 записей для обучения нашей модели из-за ограничений памяти. Вы можете попробовать с большим количеством записей, если хотите.
д. Однако мы будем использовать только первые 50 000 записей для обучения нашей модели из-за ограничений памяти. Вы можете попробовать с большим количеством записей, если хотите.
Давайте импортируем необходимые библиотеки и загрузим набор данных:
импортировать панд как pd
импортировать numpy как np
yelp_reviews = pd.read_csv("/content/drive/My Drive/Colab Datasets/yelp_review_short.csv")
ячейки = [0,2,5]
Review_names = ['отрицательный', 'положительный']
yelp_reviews['reviews_score'] = pd.cut(yelp_reviews['stars'], bins, labels=review_names)
yelp_reviews.head()
В приведенном выше сценарии мы загружаем файл yelp_review_short.csv , содержащий 50 000 отзывов, с помощью функции pd.read_csv .
Мы упростим нашу задачу, преобразовав числовые значения отзывов в категориальные. Это будет сделано путем добавления нового столбца Reviews_score в наш набор данных. Если отзыв пользователя имеет значение от 1 до 2 в столбце Stars (который оценивает бизнес по шкале от 1 до 5), в столбце Reviews_score будет строковое значение , отрицательное . Если рейтинг находится между 3-5 в столбце
Если рейтинг находится между 3-5 в столбце Stars , столбец Reviews_score будет содержать значение положительное . Это делает нашу проблему проблемой бинарной классификации.
Наконец, заголовок фрейма данных печатается, как показано ниже:
Ознакомьтесь с нашим практическим руководством по изучению Git с рекомендациями, принятыми в отрасли стандартами и прилагаемой памяткой. Прекратите гуглить команды Git и на самом деле изучите это!
Установка FastText
Следующим шагом является импорт моделей FastText, которые можно импортировать с помощью команды wget из репозитория GitHub, как показано в следующем сценарии:
!wget https://github.com/facebookresearch/fastText/archive/v0.1.0.zip
Примечание : Если вы выполняете указанную выше команду с терминала Linux, вам не нужно ставить префикс ! перед приведенной выше командой. В блокноте Google Colaboratory любая команда после
В блокноте Google Colaboratory любая команда после ! выполняется как команда оболочки, а не в интерпретаторе Python. Следовательно, все не-Python-команды здесь имеют префикс ! .
Если вы запустите приведенный выше скрипт и увидите следующие результаты, это означает, что FastText успешно загружен:
--2019-08-16 15:05:05-- https://github.com/facebookresearch/fastText/archive/v0.1.0.zip
Разрешение github.com (github.com)... 140.82.113.4
Подключение к github.com (github.com)|140.82.113.4|:443... подключено.
HTTP-запрос отправлен, ожидается ответ... 302 Найдено
Расположение: https://codeload.github.com/facebookresearch/fastText/zip/v0.1.0 [далее]
--2019-08-16 15:05:05-- https://codeload.github.com/facebookresearch/fastText/zip/v0.1.0
Разрешение codeload.github.com (codeload.github.com)... 192.30.255.121
Подключение к codeload.github.com (codeload.github.com)|192.30.255.121|:443... подключено.
HTTP-запрос отправлен, ожидается ответ... 200 OK
Длина: не указана [application/zip]
Сохранение в: «v0. 1.0.zip»
v0.1.0.zip [ <=> ] 92,06 КБ --.-КБ/с за 0,03 с
16.08.2019, 15:05:05 (3,26 МБ/с) — «v0.1.0.zip» сохранен [94267]
 1.0.zip»
v0.1.0.zip [ <=> ] 92,06 КБ --.-КБ/с за 0,03 с
16.08.2019, 15:05:05 (3,26 МБ/с) — «v0.1.0.zip» сохранен [94267]
1.0.zip»
v0.1.0.zip [ <=> ] 92,06 КБ --.-КБ/с за 0,03 с
16.08.2019, 15:05:05 (3,26 МБ/с) — «v0.1.0.zip» сохранен [94267]
Следующим шагом является распаковка модулей FastText. Просто введите следующую команду:
!unzip v0.1.0.zip
Затем вам нужно перейти в каталог, в который вы загрузили FastText, а затем выполнить команду !make для запуска двоичных файлов C++.Выполните следующие шаги:
компакт-диск fastText-0.1.0
!сделать
Если вы видите следующий вывод, это означает, что FastText успешно установлен на вашем компьютере.
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/args.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/dictionary.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/productquantizer.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/matrix.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/qmatrix.копия
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/vector. cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/model.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/utils.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/fasttext.cc
c++ -pthread -std=c++0x -O3 -funroll-loops args.o словарь.o productquantizer.o matrix.o qmatrix.o vector.o model.o utils.o fasttext.o src/main.cc -o быстрый текст
 cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/model.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/utils.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/fasttext.cc
c++ -pthread -std=c++0x -O3 -funroll-loops args.o словарь.o productquantizer.o matrix.o qmatrix.o vector.o model.o utils.o fasttext.o src/main.cc -o быстрый текст
cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/model.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/utils.cc
c++ -pthread -std=c++0x -O3 -funroll-loops -c src/fasttext.cc
c++ -pthread -std=c++0x -O3 -funroll-loops args.o словарь.o productquantizer.o matrix.o qmatrix.o vector.o model.o utils.o fasttext.o src/main.cc -o быстрый текст
Чтобы проверить установку, выполните следующую команду:
!./быстрый текст
Вы должны увидеть, что эти команды поддерживаются FastText:
использование: fasttext <команда> <аргументы>
Команды, поддерживаемые FastText:
контролируемый поезд контролируемый классификатор
Quantize квантовать модель, чтобы уменьшить использование памяти
тест оценивает контролируемый классификатор
предсказать предсказать наиболее вероятные метки
predict-prob предсказать наиболее вероятные метки с вероятностями
skipgram обучает модель skipgram
cbow поезд модель cbow
print-word-vectors печатать векторы слов с учетом обученной модели
print-sentence-vectors печатать векторы предложений с учетом обученной модели
nn запрос ближайших соседей
аналогии запрос на аналогии
Текстовая классификация
Прежде чем мы будем обучать модели FastText выполнять классификацию текста, уместно упомянуть, что FastText принимает данные в специальном формате, который выглядит следующим образом:
_label_tag Это предложение 1
_label_tag2 Это предложение 2. 
Если мы посмотрим на наш набор данных, он не в нужном формате. Текст с позитивным настроем должен выглядеть так:
__label__positive бургеры здесь очень большие порции.
Аналогично, негативные отзывы должны выглядеть так:
__label__negative Они не используют органические ингредиенты, но я...
Следующий сценарий фильтрует столбцы Reviews_score и text из набора данных, а затем добавляет префикс __label__ перед всеми значениями в столбце Reviews_score .Точно так же \n и \t заменяются пробелом в столбце text . Наконец, обновленный кадр данных записывается на диск в виде yelp_reviews_updated.txt .
импортировать панд как pd
из io импортировать StringIO
импортировать CSV
col = ['reviews_score', 'текст']
yelp_reviews = yelp_reviews[столбец]
yelp_reviews['reviews_score']=['__label__'+ s вместо s в yelp_reviews['reviews_score']]
yelp_reviews['текст']= yelp_reviews['текст']. replace('\n',' ', regex=True).заменить('\t','', регулярное выражение=Истина)
yelp_reviews.to_csv(r'/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt', index=False, sep=' ', header=False, quoting=csv.QUOTE_NONE, quotechar="", escapechar=" " )
 replace('\n',' ', regex=True).заменить('\t','', регулярное выражение=Истина)
yelp_reviews.to_csv(r'/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt', index=False, sep=' ', header=False, quoting=csv.QUOTE_NONE, quotechar="", escapechar=" " )
replace('\n',' ', regex=True).заменить('\t','', регулярное выражение=Истина)
yelp_reviews.to_csv(r'/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt', index=False, sep=' ', header=False, quoting=csv.QUOTE_NONE, quotechar="", escapechar=" " )
Теперь напечатаем заголовок обновленного кадра данных yelp_reviews .
yelp_reviews.head()
Вы должны увидеть следующие результаты:
отзывов_score текст
0 __label__positive Супер простое место, но тем не менее потрясающее.Это...
1 __label__positive Небольшое непритязательное заведение, меняющее свое меню...
2 __label__positive Lester's расположен в красивом районе...
3 __label__positive Любовь идет сюда. Да место всегда нужно т...
4 __label__positive У них был шоколадно-миндальный круассан, и он...
Точно так же хвост кадра данных выглядит так:
отзывов_score текст
49995 __label__positive Отличный комиссионный магазин! У них есть. ..
49996 __label__positive Потрясающая непринужденная атмосфера с индивидуальным...
49997 __label__positive Сегодня была моя первая встреча, и я могу отточить...
49998 __label__positive Обожаю этот шикарный салон. Они используют лучшие продукты...
49999 __label__positive Здесь вкусно. Все их мясо и с...
 ..
49996 __label__positive Потрясающая непринужденная атмосфера с индивидуальным...
49997 __label__positive Сегодня была моя первая встреча, и я могу отточить...
49998 __label__positive Обожаю этот шикарный салон. Они используют лучшие продукты...
49999 __label__positive Здесь вкусно. Все их мясо и с...
..
49996 __label__positive Потрясающая непринужденная атмосфера с индивидуальным...
49997 __label__positive Сегодня была моя первая встреча, и я могу отточить...
49998 __label__positive Обожаю этот шикарный салон. Они используют лучшие продукты...
49999 __label__positive Здесь вкусно. Все их мясо и с...
Мы преобразовали наш набор данных в требуемую форму. Следующим шагом является разделение наших данных на обучающие и тестовые наборы. 80 % данных, то есть первые 40 000 записей из 50 000, будут использоваться для обучения данных, а 20 % данных (последние 10 000 записей) будут использоваться для оценки производительности алгоритма.
Следующий скрипт делит данные на обучающую и тестовую выборки:
!head -n 40000 "/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_train.txt"
!tail -n 10000 "/content/drive/My Drive/Colab Datasets/yelp_reviews_updated.txt" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_test. txt"
 txt"
txt"
После выполнения приведенного выше сценария будет создан файл yelp_reviews_train.txt , содержащий данные обучения.Точно так же вновь созданный файл yelp_reviews_test.txt будет содержать тестовые данные.
Теперь пришло время обучить наш алгоритм классификации текста FastText.
%%время
!./fasttext под наблюдением -input "/content/drive/My Drive/Colab Datasets/yelp_reviews_train.txt" -output model_yelp_reviews
Чтобы обучить алгоритм, мы должны использовать контролируемую команду и передать ей входной файл. Название модели указывается после ключевого слова -output .Приведенный выше сценарий приведет к созданию обученной модели классификации текста с именем model_yelp_reviews.bin . Вот вывод скрипта выше:
Чтение 4 млн слов
Количество слов: 177864
Количество этикеток: 2
Прогресс: 100.0% слов/сек/поток: 2548017 lr: 0.000000 потеря: 0. 246120 eta: 0h0m
Время процессора: пользователь 212 мс, система: 48,6 мс, всего: 261 мс
Время стены: 15,6 с
 246120 eta: 0h0m
Время процессора: пользователь 212 мс, система: 48,6 мс, всего: 261 мс
Время стены: 15,6 с
246120 eta: 0h0m
Время процессора: пользователь 212 мс, система: 48,6 мс, всего: 261 мс
Время стены: 15,6 с
Вы можете посмотреть модель с помощью команды !ls , как показано ниже:
!лс
Вот вывод:
аргументы.o Makefile Quantization-results.sh
classification-example.sh matrix.o README.md
классификация-results.sh model.o src
Учебники CONTRIBUTING.md model_yelp_reviews.bin
словарь.o model_yelp_reviews.vec utils.o
eval.py ПАТЕНТЫ vector.o
fasttext pretrained-vectors.md wikifil.pl
fasttext.o productquantizer.o word-vector-example.sh
get-wikimedia.sh qmatrix.o yelp_reviews_train.текст
ЛИЦЕНЗИЯ
Вы можете увидеть model_yelp_reviews.bin в приведенном выше списке документов.
Наконец, для проверки модели можно использовать команду test . Вы должны указать имя модели и тестовый файл после команды test , как показано ниже:
!. /fasttext test model_yelp_reviews.bin "/content/drive/My Drive/Colab Datasets/yelp_reviews_test.txt"
 /fasttext test model_yelp_reviews.bin "/content/drive/My Drive/Colab Datasets/yelp_reviews_test.txt"
/fasttext test model_yelp_reviews.bin "/content/drive/My Drive/Colab Datasets/yelp_reviews_test.txt"
Вывод вышеуказанного скрипта выглядит следующим образом:
Н 10000
[электронная почта защищена] 0.909
[электронная почта защищена] 0,909
Количество примеров: 10000
Здесь [email protected] относится к точности, а [email protected] относится к отзыву. Вы можете видеть, что наша модель достигает точности и полноты 0,909, что довольно хорошо.
Давайте теперь попробуем очистить наш текст от знаков препинания, спецсимволов и перевести его в нижний регистр, чтобы улучшить единообразие текста. Следующий скрипт очищает набор поездов:
!cat "/content/drive/My Drive/Colab Datasets/yelp_reviews_train.txt" | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > "/content /drive/Мой диск/Наборы данных Colab/yelp_reviews_train_clean.txt"
Следующий скрипт очищает набор тестов:
"/content/drive/My Drive/Colab Datasets/yelp_reviews_test. txt" | sed -e "s/\([.\!?,’/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_test_clean.txt"
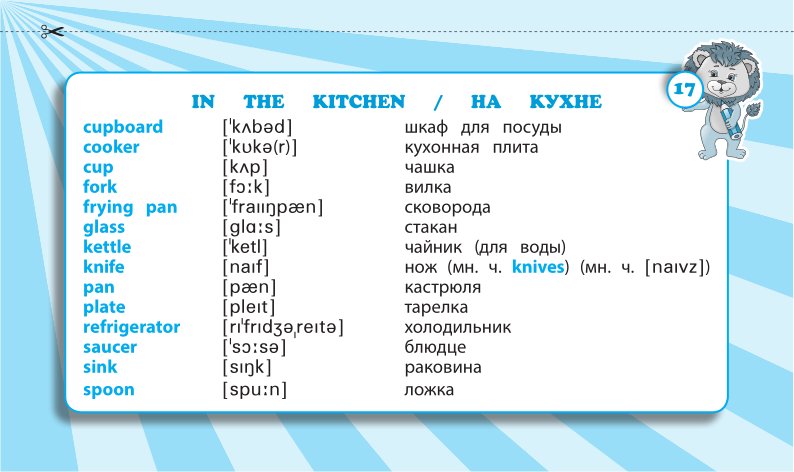 txt" | sed -e "s/\([.\!?,’/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_test_clean.txt"
txt" | sed -e "s/\([.\!?,’/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > "/content/drive/My Drive/Colab Datasets/yelp_reviews_test_clean.txt"
Теперь мы будем обучать модель на очищенном обучающем наборе:
%%время
!./fasttext под наблюдением -input "/content/drive/My Drive/Colab Datasets/yelp_reviews_train_clean.txt" -output model_yelp_reviews
И, наконец, мы будем использовать модель, обученную на очищенном обучающем наборе, чтобы делать прогнозы на очищенном тестовом наборе:
!./fasttext test model_yelp_reviews.bin "/content/drive/My Drive/Colab Datasets/yelp_reviews_test_clean.txt"
Вывод приведенного выше сценария выглядит следующим образом:
Н 10000
[электронная почта защищена] 0.915
[электронная почта защищена] 0,915
Количество примеров: 10000
Вы можете заметить небольшое увеличение как точности, так и отзыва. Чтобы еще больше улучшить модель, вы можете увеличить эпохи и скорость обучения модели. Следующий скрипт устанавливает количество эпох равным 30, а скорость обучения — 0,5.
Следующий скрипт устанавливает количество эпох равным 30, а скорость обучения — 0,5.
%%время
!./fasttext под наблюдением -input "/content/drive/My Drive/Colab Datasets/yelp_reviews_train_clean.txt" -output model_yelp_reviews -epoch 30 -lr 0.5
Вы можете попробовать разные числа и посмотреть, сможете ли вы добиться лучших результатов.Не забудьте поделиться своими результатами в комментариях!
Заключение
МодельFastText недавно доказала свою эффективность для встраивания слов и задач классификации текста во многих наборах данных. Он очень прост в использовании и молниеносно по сравнению с другими моделями встраивания слов.
В этой статье мы кратко рассмотрели, как находить семантическое сходство между разными словами, создавая вложения слов с помощью FastText. Во второй части статьи объясняется, как выполнить классификацию текста с помощью библиотеки FastText.
FAIR с открытым исходным кодом fastText - Разработка в Meta
Первоначально этот пост появился на сайте research. facebook.com.
facebook.com.
Быстрее и лучше классификация текста
Понимание значения слов, которые слетают с языка, когда вы говорите, или с кончиков пальцев, когда вы набираете посты, — одна из самых сложных технических задач, стоящих перед исследователями искусственного интеллекта. Но это насущная потребность. Автоматическая обработка текста является ключевой частью повседневного взаимодействия с вашим компьютером; это важнейший компонент всего, от веб-поиска и ранжирования контента до фильтрации спама, и когда он работает хорошо, он совершенно невидим для вас.С ростом объема онлайн-данных возникает потребность в более гибких инструментах для лучшего понимания содержания очень больших наборов данных, необходимых для получения более точных результатов классификации.
Чтобы удовлетворить эту потребность, лаборатория Facebook AI Research (FAIR) открыла исходный код fastText, библиотеки, предназначенной для помощи в создании масштабируемых решений для представления и классификации текста. Наша постоянная приверженность сотрудничеству и обмену информацией с сообществом выходит за рамки простого предоставления кода.Мы знаем, что важно делиться своими знаниями для продвижения в этой области, поэтому мы также опубликовали наше исследование, касающееся fastText.
Наша постоянная приверженность сотрудничеству и обмену информацией с сообществом выходит за рамки простого предоставления кода.Мы знаем, что важно делиться своими знаниями для продвижения в этой области, поэтому мы также опубликовали наше исследование, касающееся fastText.
FastText сочетает в себе некоторые из наиболее успешных концепций, представленных сообществами обработки естественного языка и машинного обучения за последние несколько десятилетий. К ним относятся представление предложений с помощью пакета n-грамм, а также использование информации о подсловах и обмен информацией между классами через скрытое представление. Мы также используем иерархический softmax, который использует преимущества несбалансированного распределения классов для ускорения вычислений.Эти разные концепции используются для двух разных задач: эффективной классификации текста и изучения векторных представлений слов.
Эффективное обучение классификации текстов
Глубокие нейронные сети в последнее время стали очень популярны для обработки текста. Хотя эти модели достигают очень хороших результатов в ограниченной лабораторной практике, их обучение и тестирование могут быть медленными, что ограничивает их использование на очень больших наборах данных.
Хотя эти модели достигают очень хороших результатов в ограниченной лабораторной практике, их обучение и тестирование могут быть медленными, что ограничивает их использование на очень больших наборах данных.
FastText помогает решить эту проблему. Чтобы быть эффективным для наборов данных с очень большим количеством категорий, он использует иерархический классификатор вместо плоской структуры, в которой различные категории организованы в виде дерева (например, двоичное дерево вместо списка).Это снижает временные сложности обучения и тестирования текстовых классификаторов с линейных до логарифмических по количеству классов. FastText также использует тот факт, что классы несбалансированы (некоторые классы появляются чаще, чем другие), используя алгоритм Хаффмана для построения дерева, используемого для представления категорий. Таким образом, глубина дерева очень частых категорий меньше, чем для редко встречающихся, что повышает вычислительную эффективность.
FastText также представляет текст малоразмерным вектором, который получается путем суммирования векторов, соответствующих словам, встречающимся в тексте. В fastText низкоразмерный вектор связан с каждым словом словаря. Это скрытое представление является общим для всех классификаторов для разных категорий, что позволяет использовать информацию о словах, изученных для одной категории, в других категориях. Такие представления, называемые набором слов, игнорируют порядок слов. В fastText мы также используем векторы для представления n-грамм слов, чтобы учесть локальный порядок слов, что важно для многих задач классификации текста.
В fastText низкоразмерный вектор связан с каждым словом словаря. Это скрытое представление является общим для всех классификаторов для разных категорий, что позволяет использовать информацию о словах, изученных для одной категории, в других категориях. Такие представления, называемые набором слов, игнорируют порядок слов. В fastText мы также используем векторы для представления n-грамм слов, чтобы учесть локальный порядок слов, что важно для многих задач классификации текста.
Наши эксперименты показывают, что fastText часто не уступает классификаторам глубокого обучения с точки зрения точности и на много порядков быстрее для обучения и оценки.С помощью fastText нам часто удавалось сократить время обучения с нескольких дней до нескольких секунд и добиться высочайшей производительности во многих стандартных задачах, таких как анализ настроений или предсказание тегов.
Сравнение методов fastText и глубокого обучения.Специальный инструмент
Классификация текста очень важна в коммерческом мире; фильтрация спама или кликбейта, пожалуй, самый распространенный пример. Существуют инструменты, которые создают модели для общих задач классификации (например, Vowpal Wabbit или libSVM), но fastText предназначен исключительно для классификации текста.Это позволяет быстро обучать его на чрезвычайно больших наборах данных. Мы видели результаты моделей, обученных более чем 1 миллиарду слов менее чем за 10 минут с использованием стандартного многоядерного процессора. FastText также может классифицировать полмиллиона предложений среди более чем 300 000 категорий менее чем за пять минут.
Существуют инструменты, которые создают модели для общих задач классификации (например, Vowpal Wabbit или libSVM), но fastText предназначен исключительно для классификации текста.Это позволяет быстро обучать его на чрезвычайно больших наборах данных. Мы видели результаты моделей, обученных более чем 1 миллиарду слов менее чем за 10 минут с использованием стандартного многоядерного процессора. FastText также может классифицировать полмиллиона предложений среди более чем 300 000 категорий менее чем за пять минут.
Работает на многих языках
Помимо классификации текста, fastText также можно использовать для изучения векторных представлений слов. Он был разработан для работы с различными языками, включая английский, немецкий, испанский, французский и чешский, за счет использования морфологической структуры языков.Он использует простой, но эффективный способ включения информации о подсловах, который, как оказалось, очень хорошо работает для морфологически богатых языков, таких как чешский, демонстрируя, что тщательно разработанные особенности символьных n-грамм являются сильным источником информации для обогащения представлений слов. FastText может обеспечить значительно лучшую производительность, чем популярный инструмент word2vec или другие современные морфологические представления слов.
FastText может обеспечить значительно лучшую производительность, чем популярный инструмент word2vec или другие современные морфологические представления слов.
Мы надеемся, что введение fastText поможет сообществу создавать лучшие, более масштабируемые решения для представления и классификации текста. Поставляемый как библиотека с открытым исходным кодом, мы считаем, что fastText является ценным дополнением для исследовательских и инженерных сообществ, что в конечном итоге поможет всем нам разрабатывать более качественные приложения и добиваться дальнейшего прогресса в понимании языка.
Чтение 101 для изучающих английский язык
Обучение чтению ИС ракетостроение.
~Луиза Моутс
Обучение чтению немного похоже на обучение езде на велосипеде: вы балансируете человека на руле, держите шест, вращаете пластины и одновременно сосредотачиваетесь на пункте назначения. !
!
Чтение — сложный процесс, поэтому так много детей борются за то, чтобы научиться хорошо читать. Процесс обучения чтению может быть особенно сложным для изучающих английский язык (ELL), особенно если у них мало или вообще нет формального образования, и они не научились читать на своем родном языке.
В этой статье я расскажу о стратегиях обучения ELL, основанных на пяти компонентах чтения, изложенных в документе «Обучение детей чтению» Национальной комиссии по чтению (2000). Этот отчет представляет собой исследование передового опыта обучения чтению, основанного на исследованиях, и фокусируется на следующих пяти областях обучения: фонематическая осведомленность, фонетика, словарный запас, беглость речи, понимание.
Каждая из этих тем рассматривается ниже, и каждый раздел включает:
- определение
- объяснение важности компонента при обучении чтению
- проблемы, с которыми могут столкнуться ELL
- стратегии обучения ELL Вы найдете ссылки на более подробную информацию об ELL и эффективных инструкциях по чтению в нашем разделе «Инструкции по грамотности» и «Ракеты для чтения» на протяжении всей статьи, а также в горячих ссылках ниже.
Фонематическая осведомленность и изучающие английский язык
Фонематическая осведомленность является одним из лучших показателей того, насколько хорошо дети научатся читать в течение первых двух лет обучения в школе. Однако иногда носители второго языка практически не могут «слышать» и произносить звуки на языке, который они изучают.
Возможно, у вас был ученик, который просто не мог освоить определенный звук в английском языке. Скорее всего, этот звук не был частью родного языка учащегося, и поэтому у учащегося не было возможности воспроизвести этот звук.
Я столкнулся с этим, когда изучал сингальский язык в Корпусе мира. Там был звук «й», который казался комбинацией «д» и «й», и как бы я ни старался, я не мог правильно услышать или воспроизвести звук. Я знал, к каким словам это относится, но не мог произнести. Носители сингальского языка изо всех сил пытались понять мое произношение. У ELL могут быть аналогичные трудности со звуками, которые не являются частью их родного языка.
Фонематическая осведомленность: задачи и стратегии
Что: Способность слышать различные звуки нашего языка и управлять ими.
Почему это важно: Фонематическая осведомленность является основой навыков правописания и распознавания слов. Распознавание и воспроизведение звука
Учащиеся могут быть не в состоянии «слышать» или воспроизводить новый звук на втором языке.
Ученикам, которые не слышат и не умеют работать с фонемами произносимых слов, будет трудно научиться связывать эти фонемы с буквами, когда они видят их в письменных словах.
Моделирование воспроизведения звука
Потратьте несколько минут в начале урока или в небольших группах, демонстрируя и закрепляя правильное воспроизведение звука.
Помогите начинающим читателям научиться различать звуки в коротких словах
Предложите учащимся попрактиковаться в определении звуков в начале, середине и конце этих слов. Вы можете использовать слова, которые начинаются с согласной, имеют короткую гласную и заканчиваются согласной (слова CVC), такие как mat , top и bus .
Один из очень эффективных методов состоит в том, чтобы учащиеся сопоставляли изображения слов с одинаковым началом, серединой или окончанием звука.
Будьте осторожны, используйте только те слова, которые учащиеся знают на английском языке!
Акустика и английский язык для изучающих
Обучение фонетике направлено на то, чтобы помочь новым читателям понять, что существуют систематические и предсказуемые отношения между письменными буквами и произносимыми звуками.
Учащимся будет полезно изучать и практиковать звуки и символы, включая смешанные комбинации.
Это довольно распространено в начальных классах, и ELL могут очень быстро схватывать код и казаться довольно опытными читателями. Однако важно помнить, что знание фонетики и декодирования не гарантирует хорошего понимания.Акустика: вызовы и стратегии
Что: Связь между звуком и соответствующей ему письменной буквой.
Почему это важно: Развитие чтения зависит от понимания того, что буквы и узоры букв представляют собой звуки разговорной речи.
Ограниченные навыки грамотности на родном языке
Многие педагоги считают, что учащимся нужно научиться читать только один раз. Как только концепция сопоставления символа со звуком изучена, ее можно применять к новым языкам.
Учащиеся, которые научились читать на своем родном языке, имеют явное преимущество, поскольку они смогли усвоить это понятие с помощью знакомых звуков и слов.
Учащиеся, которые не научились читать на своем родном языке, могут, однако, с трудом совмещать концепцию соответствия звука/символа, новые слова и новые звуки одновременно.
Незнакомые словарные слова
Учащимся трудно различать фонетические компоненты в новых словарных словах.
Предварительное обучение словарному запасу является важной частью хорошего обучения фонетике с ELL, чтобы учащиеся не пытались понять новые элементы словарного запаса вне контекста.
Учить телефонные линии в контексте
Использование материала содержания и содержания и содержания, вы можете представить и укрепить:
- Признание букв
- Начало и окончания звуков
- Смесится
- Слова
- Willent буквы
- омонимы
Использование практических занятий для обучения соотношению букв и звуков
Предложите учащимся написать для звука
Произнесите короткое предложение, включающее одно или несколько слов, включающих целевые фонетические признаки.
Попросите студентов внимательно слушать, а затем записать то, что они услышали.Это упражнение учит учащихся различать отдельные звуки в словах и фонетически представлять их в письме.
Помогите учащимся установить связь между своим родным языком и английским
Учащимся с сильными навыками грамотности на родном языке помогите им понять, что процесс произнесения слов одинаков для разных языков.
Объясните, что некоторые буквы могут издавать одинаковые или похожие звуки в обоих языках. Знание этого может помочь учащимся с преобладающим испанским языком, например, когда они учатся расшифровывать слова на английском языке.
Словарный запас и изучающие английский язык
Словарный запас играет важную роль в обучении чтению, а также в понимании прочитанного.
По мере того, как учащиеся учатся читать сложные тексты, они должны понимать значение новых слов, не входящих в их устный словарный запас.
Для ELL развитие словарного запаса особенно важно, поскольку учащиеся развивают академический язык.Словарь: задачи и стратегии
Что: Распознавание и понимание слов в контексте отрывка для чтения.
Почему: Понимание словарных слов является ключевым шагом в понимании прочитанного. Чем больше слов знает ребенок, тем лучше он поймет текст.
Ограниченное понимание
Начинающие читатели должны использовать слова, которые они слышат вслух, чтобы понять смысл слов, которые они произносят. Однако, если эти слова не являются частью словарного запаса учащегося, это значительно затруднит понимание текста.
Рассмотрим, например, что происходит, когда начинающий читатель приходит к слову и копает в книге. Когда он начинает различать звуки, представленные буквами d-i-g , читатель понимает, что эти звуки составляют очень знакомое слово, которое он слышал и говорил много раз.
В результате ELL труднее вычислять слова, которые еще не являются частью их разговорного (устного) словарного запаса.
Фонд ограниченного словарного запаса
Средний носитель английского языка поступает в детский сад, зная не менее 5000 слов. Средний ELL может знать 5000 слов на своем родном языке и очень мало слов на английском.
В то время как носители языка постоянно изучают новые слова, ELL все еще наверстывают упущенное в базовом словарном запасе.
Ограниченный академический словарный запас
Максимальный уровень понимания прочитанного учащимся определяется его или ее знанием слов. Знание этого слова позволяет учащимся понимать текст, в том числе текст, содержащийся в учебниках по предметным областям, в контрольных работах и в печатных материалах, таких как газеты и журналы.
Без прочной основы академической лексики ELL не смогут получить доступ к материалу, который они должны освоить.Предварительный словарный запас
Прежде чем предлагать учащимся использовать их на уроке или в задании, важно дать учащимся как можно больше информации и опыта работы с новыми словарными словами. Помните, что списки словарного запаса в учебниках часто составляются с расчетом на носителей английского языка.
Выберите слова, которые помогут читателю понять историю или текст, а также другие фразы и соединители, влияющие на понимание (хотя, кроме и т.). Вы можете предварительно изучить словарный запас, используя методы английского как второго языка (ESL), такие как:
- Ролевые игры или пантомима
- Использование жестов
- Показ реальных объектов
- Указание на картинки
- Быстрое рисование на доске
- Использование испанского эквивалента, а затем просьба к учащимся произнести слово на английском языке
- Предоставление удобного для учащихся определения
- Использование графических организаторов
Фокус на родственных словах
которые произошли от одного и того же исходного слова или корня.
Родственными словами являются родственные слова, такие как семья и familia , а также разговор и conversación . Ложные родственники существуют ( embarazada по-испански означает беременный, не смущенный), но они являются исключением из правила.Около 40% всех английских слов имеют родственные слова в испанском языке! Это очевидный мостик к английскому языку для говорящих по-испански, если учащийся знает, как пользоваться этим ресурсом. Поощряйте говорящих по-испански соединять слова на двух языках и пытаться расшифровать текст на основе имеющихся знаний.
Дайте учащимся возможность попрактиковаться в использовании новых слов
Как учитель, вы можете в явном виде учить значения слов для улучшения понимания. Однако знать слово означает знать его во всех следующих измерениях:
- Способность определять слово
- Способность распознавать, когда использовать это слово
- Знание его многочисленных значений
- Способность расшифровывать и произнести это слово по буквам
- Способность точно использовать разные определения слова в разных контекстах
Единственный способ убедиться, что учащиеся понимают новое слово, - это попросить их произнести его самостоятельно в устной или письменной форме.
Я преподавал в летней школе тему среды обитания и здоровой окружающей среды, и каждый ученик должен был выучить фразу «Сокращать, использовать повторно, перерабатывать». В течение четырех недель я давал студентам множество возможностей использовать эти слова для описания того, что мы делаем: «Мы повторно используем пакет для продуктов» или «Мы повторно использовали черновую бумагу».
Свободное владение языком и изучающие английский язык
Свободное владение языком — сложная область, когда речь идет об обучении чтению для ELL. Для носителей английского языка беглость и понимание прочитанного часто имеют сильную корреляцию, потому что беглые читатели узнают слова и понимают одновременно.
Однако это не всегда так для ELL. Многие ELL могут быть обманчиво быстрыми и точными в чтении, потому что они хорошо читают на своем родном языке и обладают сильными навыками декодирования. Тем не менее, они могут демонстрировать слабое понимание текста, а прослушивание текста вслух не обязательно делает шаг к пониманию, как это может быть для носителей языка.
Беглость: проблемы и стратегии
Что: Умение читать текст точно и быстро.
Почему это важно: Беглость важна, потому что она обеспечивает мост между распознаванием слов и их пониманием.
Неточный показатель понимания ELL
Для учащегося, изучающего английский язык, вполне обычно правильно прочитать пару вопросов, а затем не быть в состоянии правильно ответить на несколько вопросов. Навыки декодирования (озвучивание слов) и понимание текста — это два разных навыка.
Ограниченная польза от прослушивания текстов, прочитанных вслух
Носители языка, которые не являются сильными декодерами, часто могут лучше понимать текст, который им читают, чем текст, который они читают сами.
Это потому, что когда кто-то другой читает, он может сосредоточиться на значении, не пытаясь убрать слова со страницы.Однако у ELL проблемы с пониманием, как правило, связаны с ограниченным словарным запасом и ограниченными базовыми знаниями.Таким образом, прослушивание текста, прочитанного кем-то другим, не улучшит понимание.
Баланс между беглостью и пониманием
Для ELL старайтесь не давать инструкций по беглости, которые направлены в первую очередь на развитие скорости чтения учащихся за счет чтения с выражением, смыслом и пониманием.
Учащиеся могут читать быстро, но с недостаточным пониманием. Свободное владение языком без понимания потребует педагогического вмешательства в словарный запас и навыки понимания.
Дайте учащимся возможность попрактиковаться в чтении вслух
Чтобы улучшить беглость английского языка, предоставьте учащимся тексты независимого уровня, которые они могут практиковать снова и снова, или прочитайте короткий отрывок, а затем студент немедленно прочитал его обратно к вам.
Попросите учащегося попрактиковаться в чтении отрывка с определенной эмоцией или с акцентом на выражении, интонации и интонации на основе пунктуации.
Позвольте учащимся попрактиковаться в чтении вместе с записанным на пленку текстом
Это отличный способ научиться правильному произношению и фразировке.
Понимание
Понимание – это понимание и интерпретация прочитанного. Чтобы иметь возможность точно понимать письменный материал, дети должны уметь: 1) расшифровывать прочитанное; 2) устанавливать связи между прочитанным и тем, что они уже знают; 3) глубоко задуматься о прочитанном.
Однако труднее всего овладеть навыком понимания. ELL на всех уровнях владения английским языком и развития грамотности выиграют от подробного обучения навыкам понимания наряду с другими навыками, потому что улучшенное понимание не только поможет им в языковых искусствах и классах ESL, но и поможет им в предметных областях и в ежедневные занятия.
Это также повысит шансы их интереса к чтению для удовольствия.Узнайте больше из следующих статей:
Понимание: проблемы и стратегии
Что: Понимание смысла текста.
Почему это важно: Понимание является причиной для чтения. Читатели с сильным пониманием могут делать выводы о прочитанном.
Ограниченная способность читать по смыслу расстроенный.У них также могут быть проблемы с освоением новых понятий в предметных классах или с выполнением заданий и оценок, потому что они не могут понять тексты и тесты по этим предметам.
Формирование фоновых знаний
Одним из способов накопления фоновых знаний является «прохождение» книги, раздела или главы. ELL могут просмотреть информацию в тексте и начать устанавливать связи с имеющимися у них знаниями.
Если текст о ярмарке, учащийся может заметить, что картинки похожи на ярмарки, которые он посещал в прошлом, и может подумать о том, какой опыт человек испытывает в этой среде.
Если это учебник по естественным наукам, учащийся может увидеть изображения животных или процессов, которые напоминают ему о концепциях, которые он, возможно, выучил или с которыми он в некоторой степени знаком.
Часто проверяйте понимание
Когда учащиеся читают, задавайте им открытые вопросы о том, что они читают, и неформально проверяйте способность учащихся упорядочивать материал из предложений или рассказа, печатая предложения из часть рассказа на бумажных полосках, перемешивая полоски или порядок слов и предлагая учащимся расположить их по порядку.
Используйте вопросы после прочтения
После того, как ELL и/или весь класс закончат чтение, вы можете проверить их понимание с помощью тщательно составленных вопросов, стараясь использовать простые предложения и ключевую лексику из текст, который они только что прочитали.
Эти вопросы могут быть на:
- Буквальный уровень (Почему листья осенью краснеют и желтеют?)
- Интерпретативный уровень (Как вы думаете, почему ему нужна вода?)
- Прикладной уровень (Сколько воды
Эти стратегии для ELL только царапают поверхность.Если вы хотите узнать больше о пяти компонентах, обязательно ознакомьтесь с ресурсами, указанными ниже. Помните: маленькие вещи могут иметь большое значение для обеспечения эффективного обучения грамоте для ELL!
Видео: oell intrunction
Классные ролики: ull inslious
Dr.


 Это довольно распространено в начальных классах, и ELL могут очень быстро схватывать код и казаться довольно опытными читателями. Однако важно помнить, что знание фонетики и декодирования не гарантирует хорошего понимания.
Это довольно распространено в начальных классах, и ELL могут очень быстро схватывать код и казаться довольно опытными читателями. Однако важно помнить, что знание фонетики и декодирования не гарантирует хорошего понимания.
 Попросите студентов внимательно слушать, а затем записать то, что они услышали.
Попросите студентов внимательно слушать, а затем записать то, что они услышали. Для ELL развитие словарного запаса особенно важно, поскольку учащиеся развивают академический язык.
Для ELL развитие словарного запаса особенно важно, поскольку учащиеся развивают академический язык.
 Без прочной основы академической лексики ELL не смогут получить доступ к материалу, который они должны освоить.
Без прочной основы академической лексики ELL не смогут получить доступ к материалу, который они должны освоить. Родственными словами являются родственные слова, такие как семья и familia , а также разговор и conversación . Ложные родственники существуют ( embarazada по-испански означает беременный, не смущенный), но они являются исключением из правила.
Родственными словами являются родственные слова, такие как семья и familia , а также разговор и conversación . Ложные родственники существуют ( embarazada по-испански означает беременный, не смущенный), но они являются исключением из правила.

 Это потому, что когда кто-то другой читает, он может сосредоточиться на значении, не пытаясь убрать слова со страницы.
Это потому, что когда кто-то другой читает, он может сосредоточиться на значении, не пытаясь убрать слова со страницы.
 Это также повысит шансы их интереса к чтению для удовольствия.
Это также повысит шансы их интереса к чтению для удовольствия.

