Установка Node.JS на Linux-сервере | firstvds.ru
Node.JS — это среда исполнения JavaScript-кода. Она основана на движке V8, использующемся в браузере Google Chrome. С помощью Node.JS на JavaScript можно писать серверные приложения или бэкенд для сайтов.
Установка Node.JS на сервер может понадобиться по разным причинам. От них зависит выбор способа установки:
Для установки подключитесь к серверу по SSH.
Узнать последнюю актуальную версию Node.JS можно на официальном сайте:
Установка Node.JS из репозиториев операционной системы
При установке из стандартного репозитория вы получите неактуальную версию — ту, которая была доступна на момент выпуска вашей операционной системы. Для разработки или подготовки сервера под боевой проект этот способ установки не подойдёт. Но для обучения или экспериментов с кодом использовать можно.
Чтобы проверить доступную для установки версию, используйте команду:
Ubuntu и Debian:
apt show nodejs
Centos:
yum info nodejs
Установка выполняется за один шаг:
Чтобы убедиться, что установка прошла корректно, проверьте версию Node. JS и пакетного менеджера
JS и пакетного менеджера npm:
Ubuntu и Debian:
nodejs -v npm -v
Centos:
node -v npm -v
Установка Node.JS из репозиториев NodeSource
При этом способе установки можно установить актуальную версию Node.JS. Список поддерживаемых операционных систем можно увидеть здесь.
Для установки потребуется curl. Во многих современных дистрибутивах Linux-систем он установлен по умолчанию. При необходимости можно выполнить ручную установку:
Ubuntu и Debian:
apt install -y curl
Centos:
yum install -y curl
Для примера выполним установку последней стабильной версии Node.JS. Для этого нужно выполнить команды:
Чтобы убедиться, что установка прошла корректно, проверим версию Node.JS и пакетного менеджера npm:
Ubuntu и Debian:
nodejs -v npm -v
Centos:
node -v npm -v
Установка Node.
 JS с помощью менеджера версий nvm
JS с помощью менеджера версий nvmNode Version Manager, или nvm, позволяет устанавливать любые версии Node.JS и при необходимости переключаться между ними. Инструкция по установке последней версии nvm доступна в описании официального Github-репозитория.
Для примера установим текущую актуальную версию nvm. Для этого, как в предыдущем случае, нам понадобится curl. С его помощью мы скачаем и запустим скрипт установки:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.36.0/install.sh | bash
Скрипт установит nvm
root и его папка /root) и добавит алиас для вызова менеджера в конфигурационный файл пользователя. Чтобы обновить терминал с учётом этих изменений, введите команду:source ~/.bashrc
После этого проверим версию nvm, чтобы убедиться, что установка выполнена корректно:
nvm -v
Теперь мы можем использовать весь функционал nvm.
Просмотреть полный список доступных к установке версий Node.JS можно с помощью команды:
nvm ls-remote
Установить самую последнюю версию Node.JS можно следующим образом:
nvm install node
node в примере — это алиас к последней актуальной версии.
Установить конкретную версию из списка доступных можно так:
nvm install v12.19.0
где v12.19.0 — номер необходимой версии Node.JS, который можно скопировать в выводе команды nvm ls-remote.
После установки проверьте, что Node.JS установлен корректно, с помощью команды:
node -v
Для проверки списка уже установленных версий Node.JS введите в терминале:
nvm ls
Между установленными версиями можно переключаться. Например, в примере с помощью v12.19.0. Помимо неё мы можем переключиться на ранее установленную системную версию (которую можно установить одним из предыдущих способов установки Node. JS) или любую другую:
JS) или любую другую:
nvm use system
Удалить установленную с помощью nvm версию Node.JS можно в два шага:
Проверяем, какая версия Node.JS сейчас используется:
nvm current
Если используется та версия, которую нужно удалить, сначала необходимо деактивировать её, после чего уже выполнить удаление:
Если используется другая версия, удаление можно запустить сразу:
nvm uninstall v12.19.0
Express/Node introduction — Изучение веб-разработки
В этой первой статье по Express мы ответим на вопросы «Что такое Node?» и «Что такое Express?», и сделаем обзор того, что делает веб-фреймворк Express таким особенным. Мы расскажем об основных функциях и покажем вам некоторые из основных строительных блоков приложения Express (хотя на данный момент у вас еще нет среды разработки, в которой можно ее протестировать).
Node (или более формально Node. js
js
С точки зрения веб-серверной разработки Node имеет ряд преимуществ:
- Отличная производительность! Node был разработан для оптимизации пропускной способности и масштабируемости в веб-приложениях и очень хорошо справляется со многими распространенными проблемами веб-разработки (например, веб-приложения реального времени).
- Код написан на «обычном старом JavaScript», а это означает, что затрачивается меньше времени при написании кода для браузера и веб-сервера связанное с «переключением технологий» между языками.

- JavaScript является относительно новым языком программирования и имеет преимущества от улучшения дизайна языка по сравнению с другими традиционными языками для веб-серверов (например, Python, PHP, и т.д.). Многие другие новые и популярные языки компилируются/конвертируются в JavaScript, поэтому вы можете также использовать CoffeeScript, ClosureScript, Scala, LiveScript, etc.
- Менеджер пакетов Node (NPM) обеспечивает доступ к сотням тысяч многоразовых пакетов. Он также имеет лучшее в своем классе разрешение зависимостей и может также использоваться для автоматизации большинства инструментов построения.
- Он портативен, имеет версии для Microsoft Windows, OS X, Linux, Solaris, FreeBSD, OpenBSD, WebOS, и NonStop OS. Кроме того, он имеет хорошую поддержку среди многих хостинг-провайдеров, которые часто предоставляют конкретную инфраструктуру и документацию для размещения сайтов, работающих на Node.
- Он имеет очень активную стороннюю экосистему и сообщество разработчиков, которые всегда готовы помочь.

Вы можете изпользовать Node.js для создания простого веб сервера используя пакет Node HTTP.
Hello Node.js
Следующий пример создаёт веб сервер который прослушивает любой HTTP запрос на URL http://127.0.0.1:8000/ — когда запрос будет получен, скрипт ответит строкой «Hello World». Если Вы уже установили node, можете, следуя шагам инструкции попробовать пример:
- Откройте терминал (в Windows окно командной строки)
- Создайте папку, куда вы хотите сохранить программу, к примеру
test-node
cd test-node- Используя любимый текстовый редактор, создайте файл
hello.jsи вставьте в него код:
const http = require("http");
const hostname = "127.0.0.1";
const port = 8000;
const server = http.createServer((req, res) => {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
});
server. listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
})
 listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
})
listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
})
- Сохраните файл в папку, созданную выше.
- Вернитесь в терминал и выполните следующую команду:
node hello.jsВ итоге, перейдите по ссылке http://localhost:8000 в вашем браузере; вы должны увидеть текст «Hello World» в верху слева на чистой странице.
Другие общие для веб-программирования задачи не поддерживаются на прямую Node. Если вы хотите добавить специфичную поддержку различных HTTP методов (например GET, POST, DELETE, и т.д.) по разному для разных URL путей («routes»), отдачу статических файлов, или использовать шаблоны для создания динамических ответов, вам нужно написать код самим, или можете отказаться от изобретения колеса и использовать фреймворк!
Express — самый популярный веб-фреймворк для Node. Он является базовой библиотекой для ряда других популярных веб-фреймворков Node. Он предоставляет следующие механизмы:
Он предоставляет следующие механизмы:
- Написание обработчиков для запросов с различными HTTP-методами в разных URL-адресах (маршрутах).
- Интеграцию с механизмами рендеринга «view», для генерации ответов, вставляя данные в шаблоны.
- Установка общих параметров веб-приложения, такие как порт для подключения, и расположение шаблонов, которые используются для отображения ответа.
- «промежуточное ПО» для дополнительной обработки запроса в любой момент в конвейере обработки запросов.
В то время как сам express довольно минималистичный, разработчики создали совместимые пакеты промежуточного программного обеспечения для решения практически любой проблемы с веб-разработкой. Существуют библиотеки для работы с куки-файлами, сеансами, входами пользователей, параметрами URL, данными POST, заголовками безопасности и многими другими. Вы можете найти список пакетов промежуточного программного обеспечения, поддерживаемых командой Express в Express Middleware (наряду со списком некоторых популярных пакетов сторонних производителей) .
Примечание: Гибкость это палка о двух концах. Существуют пакеты промежуточного программного обеспечения (middleware) для решения практически любых проблем или для удовлетворения любых ваших требований, но правильный выбор подходящих пакетов иногда может быть проблемой. Также нет «правильного пути» для структурирования приложения, и многие примеры, которые вы можете найти в Интернете, не являются оптимальными или лишь показывают небольшую часть того, что вам нужно сделать для разработки веб-приложения.
Node первоначально был выпущен только под Linux в 2009. Менеджер пакетов NPM был выпущен в 2010, а поддержка Windows была добавлена в 2012. Текущая LTS-версия Node v12.16.1 , в то время как последний выпуск Node версии 13.11.0. Это короткий экскурс в историю; обратитесь к Википедии, если вы хотите узнать больше).
Express первоначально был выпущен в ноябре 2010 и текущая версия API 4.17.1 Вы можете отследить изменения и текущий релиз, и GitHub для более детальной информации о релизах.
Популярность веб-фрэймворка важна, поскольку она является индикатором того, будет ли она продолжаться, и какие ресурсы, вероятно, будут доступны с точки зрения документации, дополнительных библиотек и технической поддержки.
Не существует какого-либо доступного и точного измерения популярности серверных фреймворков (хотя сайты, такие как Hot Frameworks, пытаются оценить популярность, используя такие механизмы, как подсчет количества проектов на GitHub и вопросов на StackOverflow для каждой платформы). Лучший вопрос заключается в том, достаточно ли популярны Node и Express, чтобы избежать проблем с непопулярными платформами. Они продолжают развиваться? Можете ли вы получить помощь, если вам это нужно? Есть ли у вас возможность получить оплачиваемую работу, если вы изучаете Express?
Как только мы посмотрим на список широкоизвестных компаний пользующихся Express, количество разработчиков участвующих в разработке Express, и громадному числу людей, которые занимаются поддержкой Express, то мы с уверенностью скажем — Express поистине популярный фреймворк!
Web-фрэймворки часто принято делить на «ограничивающие» и «неограничивающие».
Ограничивающими фрэймворки считаются фрэймворки, которые следуют «должным» ограничениям при выполнении отдельных задач. Довольно часто они ориентированы на ускоренную разработку в конкретной области (решение задач определенного типа), поскольку должный подход к произвольно выбранной задаче бывает не прост для понимания и плохо документирован. При этом они лишаются гибкости при решении задач выходящих за сферу их обычного применения, а так же проявляют тенденцию к ограничению выбора компонентов и подходов своего применения.
Напротив, неограничивающие фреймворки имеют гораздо меньше ограничений для связи компонентов, что бы достичь цели или ограничений в выборе используемых компонентов. Они облегчают разработчикам использование наиболее подходящих инструментов для выполнения конкретной задачи, но платой за это будет то, что вы самостоятельно должны найти такие компоненты.
Express не ограничивающий. Вы можете вставить в цепочку обработки (middleware) запросов практически любое совместимые промежуточные компоненты, которые вам нравятся. Вы можете структурировать приложение в одном файле или в нескольких, использую любую структуру каталогов. Иногда вы можете чувствовать, что у вас слишком много вариантов!
Вы можете структурировать приложение в одном файле или в нескольких, использую любую структуру каталогов. Иногда вы можете чувствовать, что у вас слишком много вариантов!
В традиционных динамических веб-сайтах, веб-приложение ожидает HTTP-запроса от веб-браузера (или другого клиента). Когда запрос получен, приложение определяет, какое действие необходимо выполнить на основе URL шаблна и, возможно, связанной информации, содержащейся в данных POST или GET. В зависимости от того, что требуется, Express может затем читать или записывать данные из/в базы данных или выполнять другие задачи, в соответствии с полученным запросом. Затем приложение возвращает ответ в веб-браузер, зачастую динамически создавая HTML страницу для отображения браузером, вставляя извлеченные данные в заполнители HTML шаблона.
Express предоставляет методы позволяющие указать, какая функция вызывается для конкретного HTTP запроса (GET, POST, SET, etc.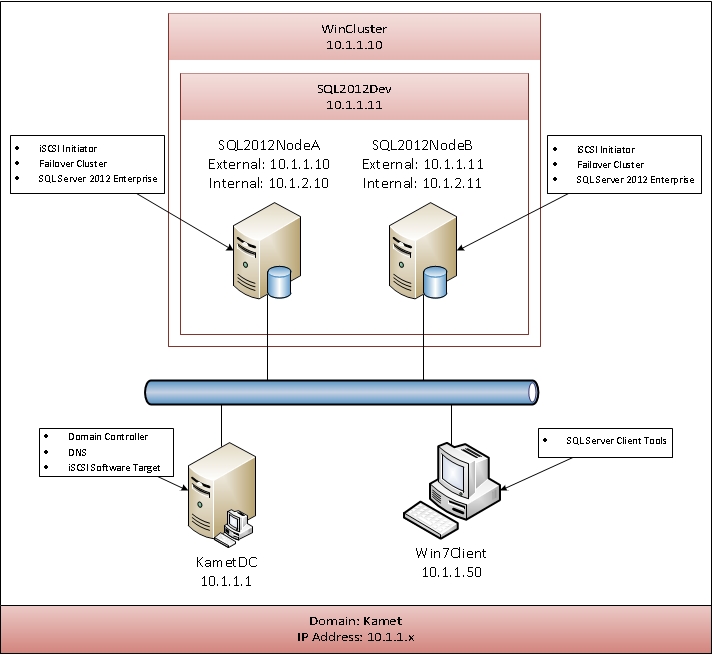 ), и URL шаблон («Route»), а также методы позволяющие указать, какой механизм шаблона («view») используется, где находятся шаблоныы файлов и какой шаблон использовать для вывода ответа. Вы можете использовать Express middleware для добавления поддержки файлов cookies, сеансов, и пользователей, получения
), и URL шаблон («Route»), а также методы позволяющие указать, какой механизм шаблона («view») используется, где находятся шаблоныы файлов и какой шаблон использовать для вывода ответа. Вы можете использовать Express middleware для добавления поддержки файлов cookies, сеансов, и пользователей, получения POST/GET параметров, и т.д. Вы можете использовать любой механизм базы данных, поддерживаемый Node (Express не определяет поведение, связанное с базой данных).
В следующих разделах объясняются некоторые общие моменты, которые вы увидите при работе с кодом Express and Node.
Helloworld Express
Сначала давайте рассмотрим стандартный пример Express Hello World (мы обсудим каждую часть этого ниже и в следующих разделах).
Совет: Если у вас уже установлены Node и Express (или если вы устанавливаете их, как показано в следующей статье), вы можете сохранить этот код в файле с именем app.js и запустить его в командной строке, вызвав узел app. js. отражения).
js. отражения).
var express = require('express');
var app = express();
app.get('/', function(req, res) {
res.send('Hello World!');
});
app.listen(3000, function() {
console.log('Example app listening on port 3000!');
});
Первые две строки требуют () (импорт) модуля Express и создания приложения Express. Этот объект, который традиционно называется app, имеет методы для маршрутизации HTTP-запросов, настройки промежуточного программного обеспечения, рендеринга представлений HTML, регистрации механизма шаблонов и изменения параметров приложения, которые управляют поведением приложения (например, режим среды, чувствительны ли определения маршрута к регистру). , и т.д.)
Средняя часть кода (три строки, начинающиеся с app.get) показывает определение маршрута. Метод app.get () указывает функцию обратного вызова, которая будет вызываться всякий раз, когда есть HTTP-запрос GET с путем (‘/’) относительно корня сайта. Функция обратного вызова принимает запрос и объект ответа в качестве аргументов и просто вызывает send () для ответа, чтобы вернуть строку «Hello World!»
Последний блок запускает сервер через порт «3000» и печатает комментарий журнала в консоль. Когда сервер работает, вы можете перейти к localhost: 3000 в вашем браузере, чтобы увидеть возвращенный пример ответа.
Когда сервер работает, вы можете перейти к localhost: 3000 в вашем браузере, чтобы увидеть возвращенный пример ответа.
Импорт и создание модулей
Модуль — это библиотека / файл JavaScript, который вы можете импортировать в другой код с помощью функции require () Node. Express сам по себе является модулем, как и промежуточное программное обеспечение и библиотеки баз данных, которые мы используем в наших приложениях Express.
Приведенный ниже код показывает, как мы импортируем модуль по имени, используя в качестве примера платформу Express. Сначала мы вызываем функцию require (), определяя имя модуля в виде строки («express») и вызывая возвращенный объект для создания приложения Express. Затем мы можем получить доступ к свойствам и функциям объекта приложения.
var express = require('express');
var app = express();
Вы также можете создавать свои собственные модули, которые можно импортировать таким же образом.
Совет: вы захотите создать свои собственные модули, потому что это позволяет вам организовать ваш код в управляемые части — монолитное однофайловое приложение трудно понять и поддерживать. Использование модулей также помогает вам управлять пространством имен, поскольку при использовании модуля импортируются только те переменные, которые вы явно экспортировали.
Использование модулей также помогает вам управлять пространством имен, поскольку при использовании модуля импортируются только те переменные, которые вы явно экспортировали.
Чтобы сделать объекты доступными вне модуля, вам просто нужно назначить их объекту экспорта. Например, модуль square.js ниже представляет собой файл, который экспортирует методы area () и perimeter ():
exports.area = function(width) { return width * width; };
exports.perimeter = function(width) { return 4 * width; };
Мы можем импортировать этот модуль, используя require (), а затем вызвать экспортированные методы, как показано:
var square = require('./square');
console.log('The area of a square with a width of 4 is ' + square.area(4));Примечание. Вы также можете указать абсолютный путь к модулю (или имя, как мы делали изначально).
Если вы хотите экспортировать полный объект в одном назначении, а не создавать его по одному свойству за раз, назначьте его для module. exports, как показано ниже (вы также можете сделать это, чтобы сделать корень объекта экспорта конструктором или другой функцией) :
exports, как показано ниже (вы также можете сделать это, чтобы сделать корень объекта экспорта конструктором или другой функцией) :
module.exports = {
area: function(width) {
return width * width;
},
perimeter: function(width) {
return 4 * width;
}
};
Для получения дополнительной информации о модулях см. Modules (Node API docs).
Использование асинхронных API
Код JavaScript часто использует асинхронные, а не синхронные API для операций, выполнение которых может занять некоторое время. Синхронный API — это тот, в котором каждая операция должна завершиться до начала следующей операции. Например, следующие функции журнала являются синхронными и выводят текст на консоль по порядку (первый, второй).
console.log('First');
console.log('Second');
В отличие от этого, асинхронный API — это тот, в котором API начнет операцию и сразу же вернется (до завершения операции). После завершения операции API будет использовать некоторый механизм для выполнения дополнительных операций. Например, приведенный ниже код выведет «Second, First», потому что хотя метод setTimeout () вызывается первым и возвращается немедленно, операция не завершается в течение нескольких секунд.
Например, приведенный ниже код выведет «Second, First», потому что хотя метод setTimeout () вызывается первым и возвращается немедленно, операция не завершается в течение нескольких секунд.
setTimeout(function() {
console.log('First');
}, 3000);
console.log('Second');
Использование неблокирующих асинхронных API-интерфейсов еще более важно в Node, чем в браузере, поскольку Node — это однопоточная среда выполнения, управляемая событиями. «Однопоточный» означает, что все запросы к серверу выполняются в одном потоке (а не порождаются в отдельных процессах). Эта модель чрезвычайно эффективна с точки зрения скорости и ресурсов сервера, но это означает, что если любая из ваших функций вызывает синхронные методы, выполнение которых занимает много времени, они будут блокировать не только текущий запрос, но и любой другой запрос, обрабатываемый ваше веб-приложение.
Есть несколько способов, которыми асинхронный API уведомляет ваше приложение о том, что оно завершено. Наиболее распространенный способ — зарегистрировать функцию обратного вызова при вызове асинхронного API, который будет вызываться после завершения операции. Это подход, использованный выше.
Наиболее распространенный способ — зарегистрировать функцию обратного вызова при вызове асинхронного API, который будет вызываться после завершения операции. Это подход, использованный выше.
Совет: Использование обратных вызовов может быть довольно «грязным», если у вас есть последовательность зависимых асинхронных операций, которые должны выполняться по порядку, потому что это приводит к нескольким уровням вложенных обратных вызовов. Эта проблема широко известна как «ад обратного вызова». Эту проблему можно решить с помощью хороших методов кодирования (см. Http://callbackhell.com/), использования такого модуля, как async, или даже перехода к функциям ES6, таким как Promises.
Примечание. Общим соглашением для Node и Express является использование обратных вызовов с ошибками. В этом соглашении первое значение в ваших функциях обратного вызова является значением ошибки, в то время как последующие аргументы содержат данные об успехе. В этом блоге есть хорошее объяснение того, почему этот подход полезен: путь Node. js — понимание обратных вызовов с ошибками (fredkschott.com).
js — понимание обратных вызовов с ошибками (fredkschott.com).
Создание обработчиков маршрута
В нашем примере Hello World Express (см. Выше) мы определили функцию обработчика маршрута (обратного вызова) для HTTP-запросов GET к корню сайта (‘/’).
app.get('/', function(req, res) {
res.send('Hello World!');
});
Функция обратного вызова принимает запрос и объект ответа в качестве аргументов. В этом случае метод просто вызывает send () в ответе, чтобы вернуть строку «Hello World!» Существует ряд других методов ответа для завершения цикла запрос / ответ, например, вы можете вызвать res.json () для отправки ответа JSON или res.sendFile () для отправки файла.
Совет по JavaScript: вы можете использовать любые имена аргументов, которые вам нравятся, в функциях обратного вызова; при вызове обратного вызова первый аргумент всегда будет запросом, а второй всегда будет ответом. Имеет смысл назвать их так, чтобы вы могли идентифицировать объект, с которым работаете, в теле обратного вызова.
Объект приложения Express также предоставляет методы для определения обработчиков маршрутов для всех других HTTP-глаголов, которые в основном используются одинаково: post (), put (), delete (), options (), trace (), copy ( ), lock (), mkcol (), move (), purge (), propfind (), proppatch (), unlock (), report (), mkactivity (), checkout (), merge ( ), m-search (), notify (), subscribe (), unsubscribe (), patch (), search () и connect ().
Существует специальный метод маршрутизации app.all (), который будет вызываться в ответ на любой метод HTTP. Это используется для загрузки функций промежуточного программного обеспечения по определенному пути для всех методов запроса. В следующем примере (из документации Express) показан обработчик, который будет выполняться для запросов к / secret независимо от используемого глагола HTTP (при условии, что он поддерживается модулем http).
app.all('/secret', function(req, res, next) {
console.log('Accessing the secret section . ..');
next();
}); ..');
next();
});
..');
next();
});Маршруты позволяют сопоставлять определенные шаблоны символов в URL-адресе, извлекать некоторые значения из URL-адреса и передавать их в качестве параметров обработчику маршрута (в качестве атрибутов объекта запроса, передаваемого в качестве параметра).
Часто полезно группировать обработчики маршрутов для определенной части сайта и получать к ним доступ с помощью общего префикса маршрута (например, сайт с вики может иметь все связанные с вики маршруты в одном файле и иметь к ним доступ с префиксом маршрута из / вики /). В Express это достигается с помощью объекта express.Router. Например, мы можем создать наш вики-маршрут в модуле с именем wiki.js, а затем экспортировать объект Router, как показано ниже:
var express = require('express');
var router = express.Router();
router.get('/', function(req, res) {
res.send('Wiki home page');
});
router.get('/about', function(req, res) {
res.send('About this wiki');
});
module. exports = router;
 exports = router;
exports = router;
Примечание. Добавление маршрутов к объекту Router аналогично добавлению маршрутов к объекту приложения (как показано ранее).
Чтобы использовать маршрутизатор в нашем главном файле приложения, нам потребуется () модуль route (wiki.js), а затем вызовите use () в приложении Express, чтобы добавить маршрутизатор в путь обработки промежуточного программного обеспечения. Эти два маршрута будут доступны из / wiki / и / wiki / about /.
var wiki = require('./wiki.js');
app.use('/wiki', wiki);Мы покажем вам намного больше о работе с маршрутами, и в частности об использовании маршрутизатора, позже в связанном разделе Routes and controllers .
Использование промежуточного программного обеспечения
Промежуточное программное обеспечение широко используется в приложениях Express для задач от обслуживания статических файлов до обработки ошибок и сжатия HTTP-ответов. Принимая во внимание, что функции маршрута заканчивают цикл запроса-ответа HTTP, возвращая некоторый ответ клиенту HTTP, функции промежуточного программного обеспечения обычно выполняют некоторую операцию над запросом или ответом и затем вызывают следующую функцию в «стеке», которая может быть большим количеством промежуточного программного обеспечения или маршрута обработчик. Порядок вызова промежуточного программного обеспечения зависит от разработчика приложения.
Порядок вызова промежуточного программного обеспечения зависит от разработчика приложения.
Примечание. Промежуточное программное обеспечение может выполнять любую операцию, выполнять любой код, вносить изменения в объект запроса и ответа, а также может завершать цикл запрос-ответ. Если он не завершает цикл, он должен вызвать next (), чтобы передать управление следующей функции промежуточного программного обеспечения (или запрос останется зависшим).
Большинство приложений используют стороннее промежуточное программное обеспечение для упрощения общих задач веб-разработки, таких как работа с файлами cookie, сессиями, аутентификацией пользователя, доступом к данным запросов POST и JSON, ведение журнала и т. д. Список пакетов промежуточного программного обеспечения, поддерживаемых командой Express, можно найти. (который также включает в себя другие популярные сторонние пакеты). Другие экспресс-пакеты доступны в диспетчере пакетов NPM.
Для использования стороннего промежуточного программного обеспечения сначала необходимо установить его в свое приложение с помощью NPM. Например, чтобы установить промежуточное программное обеспечение средства регистрации HTTP-запросов morgan, вы должны сделать следующее:
Например, чтобы установить промежуточное программное обеспечение средства регистрации HTTP-запросов morgan, вы должны сделать следующее:
$ npm install morgan
Затем вы можете вызвать use () для объекта приложения Express, чтобы добавить промежуточное программное обеспечение в стек:
var express = require('express');
var logger = require('morgan');
var app = express();
app.use(logger('dev'));
...Примечание. Промежуточное программное обеспечение и функции маршрутизации вызываются в том порядке, в котором они были объявлены. Для некоторого промежуточного программного обеспечения важен порядок (например, если промежуточное программное обеспечение сеанса зависит от промежуточного программного обеспечения cookie, то сначала должен быть добавлен обработчик cookie). Почти всегда случается так, что промежуточное ПО вызывается перед настройкой маршрутов, иначе ваши обработчики маршрутов не будут иметь доступа к функциям, добавленным вашим промежуточным ПО.
Вы можете написать свои собственные функции промежуточного программного обеспечения, и вам, вероятно, придется это сделать (хотя бы для создания кода обработки ошибок). Единственное различие между функцией промежуточного программного обеспечения и обратным вызовом обработчика маршрута состоит в том, что функции промежуточного программного обеспечения имеют третий аргумент, следующий: какие функции промежуточного программного обеспечения должны вызываться, если они не завершают цикл запроса (когда вызывается функция промежуточного программного обеспечения, она содержит следующую функцию). это надо называть).
Вы можете добавить функцию промежуточного программного обеспечения в цепочку обработки с помощью app.use () или app.add (), в зависимости от того, хотите ли вы применить промежуточное программное обеспечение ко всем ответам или к ответам с определенным глаголом HTTP (GET, POST и т. д.). ). Маршруты задаются одинаково в обоих случаях, хотя маршрут необязателен при вызове app. use ().
use ().
В приведенном ниже примере показано, как можно добавить функцию промежуточного программного обеспечения, используя оба метода, а также с / без маршрута.
var express = require('express');
var app = express();
var a_middleware_function = function(req, res, next) {
next();
}
app.use(a_middleware_function);
app.use('/someroute', a_middleware_function);
app.get('/', a_middleware_function);
app.listen(3000);Совет по JavaScript: выше мы объявляем функцию промежуточного программного обеспечения отдельно, а затем устанавливаем ее в качестве обратного вызова. В нашей предыдущей функции обработчика маршрута мы объявили функцию обратного вызова, когда она использовалась. В JavaScript любой подход является допустимым.
Документация по Express содержит намного больше отличной информации по использованию и написанию промежуточного программного обеспечения Express.
Обслуживание статических файлов
Вы можете использовать промежуточное программное обеспечение express. static для обслуживания статических файлов, включая ваши изображения, CSS и JavaScript (static () — единственная функция промежуточного программного обеспечения, которая фактически является частью Express). Например, вы должны использовать строку ниже для обслуживания изображений, файлов CSS и файлов JavaScript из каталога с именем public на том же уровне, где вы вызываете узел:
static для обслуживания статических файлов, включая ваши изображения, CSS и JavaScript (static () — единственная функция промежуточного программного обеспечения, которая фактически является частью Express). Например, вы должны использовать строку ниже для обслуживания изображений, файлов CSS и файлов JavaScript из каталога с именем public на том же уровне, где вы вызываете узел:
app.use(express.static('public'));
Любые файлы в публичном каталоге обслуживаются путем добавления их имени файла (относительно базового «публичного» каталога) к базовому URL. Так, например:
http://localhost:3000/images/dog.jpg
http://localhost:3000/css/style.css
http://localhost:3000/js/app.js
http://localhost:3000/about.html
Вы можете вызывать static () несколько раз для обслуживания нескольких каталогов. Если файл не может быть найден одной функцией промежуточного программного обеспечения, он будет просто передан последующему промежуточному программному обеспечению (порядок вызова промежуточного программного обеспечения основан на вашем порядке объявления).
app.use(express.static('public'));
app.use(express.static('media'));
Вы также можете создать виртуальный префикс для ваших статических URL-адресов, вместо добавления файлов к базовому URL-адресу. Например, здесь мы указываем путь монтирования, чтобы файлы загружались с префиксом «/ media»:
app.use('/media', express.static('public'));
Теперь вы можете загружать файлы, находящиеся в публичном каталоге, из префикса / media path.
http://localhost:3000/media/images/dog.jpg
http://localhost:3000/media/cry.mp3
Для получения дополнительной информации см. Serving static files in Express.
Обработка ошибок
Ошибки обрабатываются одной или несколькими специальными функциями промежуточного программного обеспечения, которые имеют четыре аргумента вместо обычных трех: (err, req, res, next). Например:
app.use(function(err, req, res, next) {
console. error(err.stack);
res.status(500).send('Something broke!');
});
 error(err.stack);
res.status(500).send('Something broke!');
});
error(err.stack);
res.status(500).send('Something broke!');
});
Они могут возвращать любой требуемый контент, но должны вызываться после всех других app.use () и маршрутизировать вызовы, чтобы они были последним промежуточным ПО в процессе обработки запросов!
Express поставляется со встроенным обработчиком ошибок, который заботится обо всех оставшихся ошибках, которые могут возникнуть в приложении. Эта промежуточная функция обработки ошибок по умолчанию добавляется в конец стека функций промежуточного программного обеспечения. Если вы передаете ошибку в next () и не обрабатываете ее в обработчике ошибок, она будет обработана встроенным обработчиком ошибок; ошибка будет записана клиенту с трассировкой стека.
Примечание. Трассировка стека не включена в производственную среду. Чтобы запустить его в производственном режиме, необходимо установить переменную среды NODE_ENV в «производство».
Примечание. HTTP404 и другие коды состояния «ошибка» не считаются ошибками. Если вы хотите справиться с этим, вы можете добавить функцию промежуточного программного обеспечения для этого. Для получения дополнительной информации см. FAQ.
Если вы хотите справиться с этим, вы можете добавить функцию промежуточного программного обеспечения для этого. Для получения дополнительной информации см. FAQ.
Для получения дополнительной информации см. Error handling (Express docs).
Использование баз данных
Приложения Express могут использовать любой механизм базы данных, поддерживаемый Node (сам по себе Express не определяет каких-либо дополнительных действий / требований для управления базой данных). Есть много вариантов, включая PostgreSQL, MySQL, Redis, SQLite, MongoDB и т. Д.
Чтобы использовать их, вы должны сначала установить драйвер базы данных, используя NPM. Например, чтобы установить драйвер для популярной NoSQL MongoDB, вы должны использовать команду:
$ npm install mongodb
Сама база данных может быть установлена локально или на облачном сервере. В вашем экспресс-коде вам требуется драйвер, подключиться к базе данных, а затем выполнить операции создания, чтения, обновления и удаления (CRUD). Пример ниже (из документации Express) показывает, как вы можете найти записи «млекопитающих», используя MongoDB.
Пример ниже (из документации Express) показывает, как вы можете найти записи «млекопитающих», используя MongoDB.
var MongoClient = require('mongodb').MongoClient;
MongoClient.connect('mongodb://localhost:27017/animals', function(err, db) {
if (err) throw err;
db.collection('mammals').find().toArray(function (err, result) {
if (err) throw err;
console.log(result);
});
});Другим популярным подходом является косвенный доступ к вашей базе данных с помощью Object Relational Mapper («ORM»). При таком подходе вы определяете свои данные как «объекты» или «модели», и ORM отображает их в базовый формат базы данных. Этот подход имеет то преимущество, что как разработчик вы можете продолжать думать с точки зрения объектов JavaScript, а не семантики базы данных, и что есть очевидное место для выполнения проверки и проверки входящих данных. Подробнее о базах данных мы поговорим в следующей статье.
Для получения дополнительной информации см. Database integration (Express docs).
Рендеринг данных (просмотров)
Механизмы шаблонов (в Express называемые «механизмами просмотра») позволяют указывать структуру выходного документа в шаблоне, используя заполнители для данных, которые будут заполняться при создании страницы. Шаблоны часто используются для создания HTML, но могут также создавать другие типы документов. В Express есть поддержка ряда шаблонных движков, и здесь есть полезное сравнение более популярных движков: Сравнение шаблонизаторов JavaScript: Jade, Mustache, Dust и More.
В своем коде настроек приложения вы задаете механизм шаблонов для использования и место, где Express должен искать шаблоны, используя настройки «views» и «engine», как показано ниже (вам также нужно будет установить пакет, содержащий вашу библиотеку шаблонов). !)
var express = require('express');
var app = express();
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'some_template_engine_name');
Внешний вид шаблона будет зависеть от того, какой движок вы используете. Предполагая, что у вас есть файл шаблона с именем «index. <Template_extension>», который содержит заполнители для переменных данных с именами «title» и «message», вы должны вызвать Response.render () в функции обработчика маршрута для создания и отправки ответа HTML. :
Предполагая, что у вас есть файл шаблона с именем «index. <Template_extension>», который содержит заполнители для переменных данных с именами «title» и «message», вы должны вызвать Response.render () в функции обработчика маршрута для создания и отправки ответа HTML. :
app.get('/', function(req, res) {
res.render('index', { title: 'About dogs', message: 'Dogs rock!' });
});Для получения дополнительной информации см. Using template engines with Express (Express docs).
Файловая структура
Express не делает никаких предположений относительно структуры или компонентов, которые вы используете. Маршруты, представления, статические файлы и другая логика конкретного приложения могут находиться в любом количестве файлов с любой структурой каталогов. Хотя вполне возможно иметь все приложения Express в одном файле, обычно имеет смысл разделить ваше приложение на файлы на основе функций (например, управление учетными записями, блоги, доски обсуждений) и проблемной области архитектуры (например, модель, представление или контроллер, если вы случайно используете MVC architecture).
В более поздней теме мы будем использовать Express Application Generator, который создает модульный каркас приложения, который мы можем легко расширить для создания веб-приложений.
Поздравляем, вы завершили первый шаг в своем путешествии Express / Node! Теперь вы должны понимать основные преимущества Express и Node, а также примерно то, как могут выглядеть основные части приложения Express (маршруты, промежуточное ПО, обработка ошибок и код шаблона). Вы также должны понимать, что с Express, который является непонятным фреймворком, то, как вы собираете эти части вместе, и библиотеки, которые вы используете, в значительной степени зависит от вас!
Конечно, Express — это очень легкая платформа для веб-приложений, поэтому большая часть ее преимуществ и возможностей обеспечивается сторонними библиотеками и функциями. Мы рассмотрим это более подробно в следующих статьях. В нашей следующей статье мы рассмотрим настройку среды разработки Node, чтобы вы могли увидеть некоторый код Express в действии.
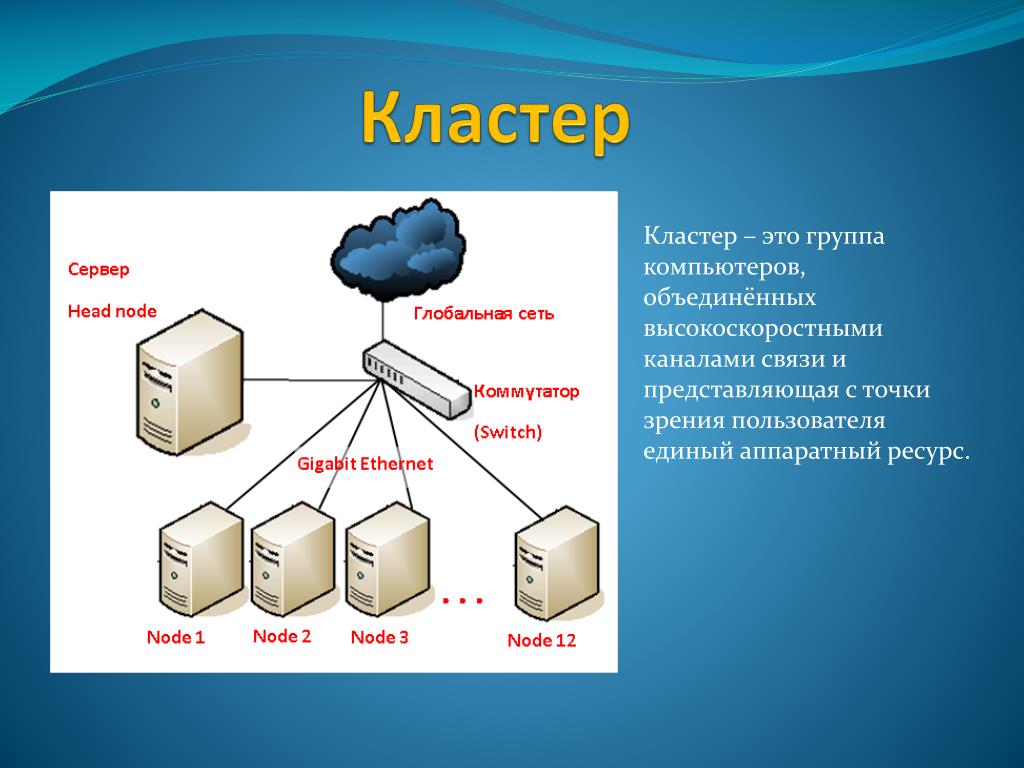
Развертывание кластеризованного файлового сервера с двумя узлами
- Чтение занимает 18 мин
В этой статье
Применяется к: Windows Server 2019, Windows Server 2016Applies to: Windows Server 2019, Windows Server 2016
Отказоустойчивый кластер — это группа независимых компьютеров, совместная работа которых позволяет повысить доступность приложений и служб.A failover cluster is a group of independent computers that work together to increase the availability of applications and services. Кластерные серверы (называемые «узлы») соединены физическими кабелями и программным обеспечением.The clustered servers (called nodes) are connected by physical cables and by software. При сбое на одном из узлов кластера его функции немедленно передаются другому узлу (этот процесс называется отработкой отказа).If one of the cluster nodes fails, another node begins to provide service (a process known as failover). В службе можно столкнуться с минимальными нарушениями.Users experience a minimum of disruptions in service.
При сбое на одном из узлов кластера его функции немедленно передаются другому узлу (этот процесс называется отработкой отказа).If one of the cluster nodes fails, another node begins to provide service (a process known as failover). В службе можно столкнуться с минимальными нарушениями.Users experience a minimum of disruptions in service.
В этом руководстве описаны шаги по установке и настройке отказоустойчивого кластера файлового сервера общего назначения с двумя узлами.This guide describes the steps for installing and configuring a general purpose file server failover cluster that has two nodes. Создавая конфигурацию в этом руководство, вы можете изучить отказоустойчивые кластеры и ознакомиться с интерфейсом оснастки управления отказоустойчивыми кластерами в Windows Server 2019 или Windows Server 2016.By creating the configuration in this guide, you can learn about failover clusters and familiarize yourself with the Failover Cluster Management snap-in interface in Windows Server 2019 or Windows Server 2016.
Общие сведения о кластере файлового сервера с двумя узламиOverview for a two-node file server cluster
Серверы в отказоустойчивом кластере могут работать в различных ролях, включая роли файлового сервера, сервера Hyper-V или сервера базы данных, а также обеспечивают высокий уровень доступности для различных служб и приложений.Servers in a failover cluster can function in a variety of roles, including the roles of file server, Hyper-V server, or database server, and can provide high availability for a variety of other services and applications. В этом руководство описано, как настроить кластер файлового сервера с двумя узлами.This guide describes how to configure a two-node file server cluster.
Отказоустойчивый кластер обычно включает в себя единицу хранения, которая физически подключена ко всем серверам в кластере, хотя каждый заданный том в хранилище доступен только одному серверу за раз.A failover cluster usually includes a storage unit that is physically connected to all the servers in the cluster, although any given volume in the storage is only accessed by one server at a time. На следующей схеме показан отказоустойчивый кластер с двумя узлами, подключенный к единице хранения.The following diagram shows a two-node failover cluster connected to a storage unit.
На следующей схеме показан отказоустойчивый кластер с двумя узлами, подключенный к единице хранения.The following diagram shows a two-node failover cluster connected to a storage unit.
Тома хранилища или логические номера устройств (LUN), предоставляемые узлам в кластере, не должны предоставляться другим серверам, включая серверы в другом кластере.Storage volumes or logical unit numbers (LUNs) exposed to the nodes in a cluster must not be exposed to other servers, including servers in another cluster. Это показано на схеме ниже.The following diagram illustrates this.
Обратите внимание, что для обеспечения максимальной доступности любого сервера важно следовать рекомендациям по управлению сервером, например, тщательному управлению физической средой серверов, тестированию изменений программного обеспечения перед их полным внедрением и тщательно отслеживать обновления программного обеспечения и изменения конфигурации на всех кластеризованных серверах.Note that for the maximum availability of any server, it is important to follow best practices for server management—for example, carefully managing the physical environment of the servers, testing software changes before fully implementing them, and carefully keeping track of software updates and configuration changes on all clustered servers.
В следующем сценарии описано, как можно настроить отказоустойчивый кластер файлового сервера.The following scenario describes how a file server failover cluster can be configured. Общие файлы находятся в хранилище кластера, а кластеризованный сервер может работать как файловый сервер, который их использует.The files being shared are on the cluster storage, and either clustered server can act as the file server that shares them.
Общие папки в отказоустойчивом кластереShared folders in a failover cluster
В следующем списке описаны функции конфигурации общих папок, интегрированные в отказоустойчивую кластеризацию.The following list describes shared folder configuration functionality that is integrated into failover clustering:
Область отображения ограничена только кластеризованными общими папками (без смешивания с некластеризованными общими папками). когда пользователь просматривает общие папки, указывая путь к кластеризованному файловому серверу, на экран будут включены только общие папки, которые являются частью конкретной роли файлового сервера.
Display is scoped to clustered shared folders only (no mixing with non-clustered shared folders): When a user views shared folders by specifying the path of a clustered file server, the display will include only the shared folders that are part of the specific file server role. Она будет исключать некластеризованные общие папки и использует часть отдельных ролей файлового сервера, которые находятся на узле кластера.It will exclude non-clustered shared folders and shares part of separate file server roles that happen to be on a node of the cluster.Перечисление на основе доступа. можно использовать перечисление на основе доступа, чтобы скрыть указанную папку от представления пользователей.Access-based enumeration: You can use access-based enumeration to hide a specified folder from users’ view. Вместо того чтобы разрешить пользователям просматривать папку, но не обращаться к ней, можно запретить им просматривать папку.Instead of allowing users to see the folder but not access anything on it, you can choose to prevent them from seeing the folder at all.
Перечисление на основе доступа для кластеризованной общей папки можно настроить так же, как и для некластеризованной общей папки.You can configure access-based enumeration for a clustered shared folder in the same way as for a non-clustered shared folder.Автономный доступ. можно настроить автономный доступ (кэширование) для кластеризованной общей папки таким же образом, как и для некластеризованной общей папки.Offline access: You can configure offline access (caching) for a clustered shared folder in the same way as for a nonclustered shared folder.
Кластерные диски всегда распознаются как часть кластера: независимо от того, используется ли интерфейс отказоустойчивого кластера, проводник или оснастка управления хранилищем, Windows определяет, назначен ли диск в хранилище кластера.Clustered disks are always recognized as part of the cluster: Whether you use the failover cluster interface, Windows Explorer, or the Share and Storage Management snap-in, Windows recognizes whether a disk has been designated as being in the cluster storage.
Если такой диск уже был настроен в оснастке управления отказоустойчивыми кластерами как часть кластеризованного файлового сервера, можно использовать любой из упомянутых выше интерфейсов для создания общего ресурса на диске.If such a disk has already been configured in Failover Cluster Management as part of a clustered file server, you can then use any of the previously mentioned interfaces to create a share on the disk. Если такой диск не был настроен как часть кластеризованного файлового сервера, создать на нем общую папку по ошибке невозможно.If such a disk has not been configured as part of a clustered file server, you cannot mistakenly create a share on it. Вместо этого для предоставления общего доступа необходимо сначала настроить диск в составе кластеризованного файлового сервера.Instead, an error indicates that the disk must first be configured as part of a clustered file server before it can be shared.Интеграция служб для сетевой файловой системы. роль файлового сервера в Windows Server включает в себя дополнительную службу ролей под названием службы для NFS.
Integration of Services for Network File System: The File Server role in Windows Server includes the optional role service called Services for Network File System (NFS). Установив службу роли и настроив общие папки с помощью служб для NFS, можно создать кластеризованный файловый сервер, который поддерживает клиенты на базе UNIX.By installing the role service and configuring shared folders with Services for NFS, you can create a clustered file server that supports UNIX-based clients.
 Display is scoped to clustered shared folders only (no mixing with non-clustered shared folders): When a user views shared folders by specifying the path of a clustered file server, the display will include only the shared folders that are part of the specific file server role. Она будет исключать некластеризованные общие папки и использует часть отдельных ролей файлового сервера, которые находятся на узле кластера.It will exclude non-clustered shared folders and shares part of separate file server roles that happen to be on a node of the cluster.
Display is scoped to clustered shared folders only (no mixing with non-clustered shared folders): When a user views shared folders by specifying the path of a clustered file server, the display will include only the shared folders that are part of the specific file server role. Она будет исключать некластеризованные общие папки и использует часть отдельных ролей файлового сервера, которые находятся на узле кластера.It will exclude non-clustered shared folders and shares part of separate file server roles that happen to be on a node of the cluster. Перечисление на основе доступа для кластеризованной общей папки можно настроить так же, как и для некластеризованной общей папки.You can configure access-based enumeration for a clustered shared folder in the same way as for a non-clustered shared folder.
Перечисление на основе доступа для кластеризованной общей папки можно настроить так же, как и для некластеризованной общей папки.You can configure access-based enumeration for a clustered shared folder in the same way as for a non-clustered shared folder. Если такой диск уже был настроен в оснастке управления отказоустойчивыми кластерами как часть кластеризованного файлового сервера, можно использовать любой из упомянутых выше интерфейсов для создания общего ресурса на диске.If such a disk has already been configured in Failover Cluster Management as part of a clustered file server, you can then use any of the previously mentioned interfaces to create a share on the disk. Если такой диск не был настроен как часть кластеризованного файлового сервера, создать на нем общую папку по ошибке невозможно.If such a disk has not been configured as part of a clustered file server, you cannot mistakenly create a share on it. Вместо этого для предоставления общего доступа необходимо сначала настроить диск в составе кластеризованного файлового сервера.Instead, an error indicates that the disk must first be configured as part of a clustered file server before it can be shared.
Если такой диск уже был настроен в оснастке управления отказоустойчивыми кластерами как часть кластеризованного файлового сервера, можно использовать любой из упомянутых выше интерфейсов для создания общего ресурса на диске.If such a disk has already been configured in Failover Cluster Management as part of a clustered file server, you can then use any of the previously mentioned interfaces to create a share on the disk. Если такой диск не был настроен как часть кластеризованного файлового сервера, создать на нем общую папку по ошибке невозможно.If such a disk has not been configured as part of a clustered file server, you cannot mistakenly create a share on it. Вместо этого для предоставления общего доступа необходимо сначала настроить диск в составе кластеризованного файлового сервера.Instead, an error indicates that the disk must first be configured as part of a clustered file server before it can be shared. Integration of Services for Network File System: The File Server role in Windows Server includes the optional role service called Services for Network File System (NFS). Установив службу роли и настроив общие папки с помощью служб для NFS, можно создать кластеризованный файловый сервер, который поддерживает клиенты на базе UNIX.By installing the role service and configuring shared folders with Services for NFS, you can create a clustered file server that supports UNIX-based clients.
Integration of Services for Network File System: The File Server role in Windows Server includes the optional role service called Services for Network File System (NFS). Установив службу роли и настроив общие папки с помощью служб для NFS, можно создать кластеризованный файловый сервер, который поддерживает клиенты на базе UNIX.By installing the role service and configuring shared folders with Services for NFS, you can create a clustered file server that supports UNIX-based clients.Требования к отказоустойчивому кластеру с двумя узламиRequirements for a two-node failover cluster
Для отказоустойчивого кластера в Windows Server 2016 или Windows Server 2019, который считается официально поддерживаемым решением корпорации Майкрософт, решение должно удовлетворять следующим критериям.For a failover cluster in Windows Server 2016 or Windows Server 2019 to be considered an officially supported solution by Microsoft, the solution must meet the following criteria.
Все компоненты оборудования и программного обеспечения должны отвечать требованиям сертификации для логотипа соответствующей ОС.
All hardware and software components must meet the qualifications for the appropriate logo. Для Windows Server 2016 это логотип «сертифицировано для Windows Server 2016».For Windows Server 2016, this is the «Certified for Windows Server 2016» logo. Для Windows Server 2019 это логотип «сертифицировано для Windows Server 2019».For Windows Server 2019, this is the «Certified for Windows Server 2019» logo. Дополнительные сведения о сертифицированных оборудовании и программном обеспечении см. на веб-сайте каталога Microsoft Windows Server .For more information about what hardware and software systems have been certified, please visit the Microsoft Windows Server Catalog site.Полностью настроенное решение (серверы, сеть и хранилище) должно пройти все тесты в мастере проверки, который является частью оснастки отказоустойчивого кластера.The fully configured solution (servers, network, and storage) must pass all tests in the validation wizard, which is part of the failover cluster snap-in.
 All hardware and software components must meet the qualifications for the appropriate logo. Для Windows Server 2016 это логотип «сертифицировано для Windows Server 2016».For Windows Server 2016, this is the «Certified for Windows Server 2016» logo. Для Windows Server 2019 это логотип «сертифицировано для Windows Server 2019».For Windows Server 2019, this is the «Certified for Windows Server 2019» logo. Дополнительные сведения о сертифицированных оборудовании и программном обеспечении см. на веб-сайте каталога Microsoft Windows Server .For more information about what hardware and software systems have been certified, please visit the Microsoft Windows Server Catalog site.
All hardware and software components must meet the qualifications for the appropriate logo. Для Windows Server 2016 это логотип «сертифицировано для Windows Server 2016».For Windows Server 2016, this is the «Certified for Windows Server 2016» logo. Для Windows Server 2019 это логотип «сертифицировано для Windows Server 2019».For Windows Server 2019, this is the «Certified for Windows Server 2019» logo. Дополнительные сведения о сертифицированных оборудовании и программном обеспечении см. на веб-сайте каталога Microsoft Windows Server .For more information about what hardware and software systems have been certified, please visit the Microsoft Windows Server Catalog site.
Для отказоустойчивого кластера с двумя узлами необходимо следующее:The following will be needed for a two-node failover cluster.
Серверы: Рекомендуется использовать совпадающие компьютеры с одинаковыми или аналогичными компонентами.Servers: We recommend using matching computers with the same or similar components. Серверы для отказоустойчивого кластера с двумя узлами должны работать под управлением одной и той же версии Windows Server.The servers for a two-node failover cluster must run the same version of Windows Server. Они также должны иметь одинаковые обновления программного обеспечения (исправления).They should also have the same software updates (patches).
Сетевые адаптеры и кабель: Сетевое оборудование, как и другие компоненты решения отказоустойчивого кластера, должно быть совместимо с Windows Server 2016 или Windows Server 2019.Network Adapters and cable: The network hardware, like other components in the failover cluster solution, must be compatible with Windows Server 2016 or Windows Server 2019.
При использовании iSCSI сетевые адаптеры должны быть выделены для сетевого взаимодействия или iSCSI, а не для обоих.If you use iSCSI, the network adapters must be dedicated to either network communication or iSCSI, not both. Избегайте единственных точек отказа в сетевой инфраструктуре, соединяющей узлы кластера.In the network infrastructure that connects your cluster nodes, avoid having single points of failure. Это достигается несколькими способами.There are multiple ways of accomplishing this. Вы можете подключать узлы кластера к разным сетям.You can connect your cluster nodes by multiple, distinct networks. Можно также соединить узлы кластера в одну сеть, основанную на сгруппированных сетевых адаптерах, дублированных коммутаторах и маршрутизаторах и аналогичном оборудовании, исключающем появление единственных точек отказа.Alternatively, you can connect your cluster nodes with one network that is constructed with teamed network adapters, redundant switches, redundant routers, or similar hardware that removes single points of failure.Примечание
Если узлы кластера подключены к одной сети, сеть будет передавать требование избыточности в мастере проверки конфигурации.If the cluster nodes are connected with a single network, the network will pass the redundancy requirement in the Validate a Configuration wizard. Однако в отчет будет включено предупреждение о том, что сеть не должна иметь единой точки отказа.However, the report will include a warning that the network should not have a single point of failure.
Контроллеры устройств или соответствующие адаптеры для хранилища:Device Controllers or appropriate adapters for storage:
- Последовательный подключенный SCSI или Fibre Channel: Если вы используете последовательный подключенный SCSI или Fibre Channel, во всех кластеризованных серверах все компоненты стека хранилища должны быть идентичными.Serial Attached SCSI or Fibre Channel: If you are using Serial Attached SCSI or Fibre Channel, in all clustered servers, all components of the storage stack should be identical. Необходимо, чтобы программное обеспечение Multipath I/O (MPIO) и программные компоненты модуля для конкретных устройств (DSM) были идентичными.It is required that the multipath I/O (MPIO) software and Device Specific Module (DSM) software components be identical. Рекомендуется, чтобы контроллеры запоминающих устройств, то есть адаптер шины (HBA), драйверы HBA и встроенное ПО HBA, присоединенные к хранилищу кластера, были идентичными.It is recommended that the mass-storage device controllers—that is, the host bus adapter (HBA), HBA drivers, and HBA firmware—that are attached to cluster storage be identical. При использовании различных HBA следует уточнить у поставщика хранилища, обеспечиваются ли при этом поддерживаемые или рекомендуемые конфигурации.If you use dissimilar HBAs, you should verify with the storage vendor that you are following their supported or recommended configurations.
- iSCSI: При использовании iSCSI на каждом кластерном сервере должен быть один или несколько сетевых адаптеров или адаптеров шины, выделенных для хранилища ISCSI. iSCSI: If you are using iSCSI, each clustered server must have one or more network adapters or host bus adapters that are dedicated to the ISCSI storage. Сеть, используемая для iSCSI, не может использоваться для сетевого взаимодействия.The network you use for iSCSI cannot be used for network communication. На всех кластеризованных серверах сетевые адаптеры для подключения к целевому хранилищу iSCSI должны быть одинаковыми. Рекомендуется использовать адаптеры Gigabit Ethernet или с более высокой пропускной способностью.In all clustered servers, the network adapters you use to connect to the iSCSI storage target should be identical, and we recommend that you use Gigabit Ethernet or higher.
- Последовательный подключенный SCSI или Fibre Channel: Если вы используете последовательный подключенный SCSI или Fibre Channel, во всех кластеризованных серверах все компоненты стека хранилища должны быть идентичными.Serial Attached SCSI or Fibre Channel: If you are using Serial Attached SCSI or Fibre Channel, in all clustered servers, all components of the storage stack should be identical.
Хранилище: Необходимо использовать общее хранилище, сертифицированное для Windows Server 2016 или Windows Server 2019.Storage: You must use shared storage that is certified for Windows Server 2016 or Windows Server 2019.
Для отказоустойчивого кластера с двумя узлами хранилище должно содержать по крайней мере два отдельных тома (LUN), если для кворума используется диск-свидетель.
For a two-node failover cluster, the storage should contain at least two separate volumes (LUNs) if using a witness disk for quorum. Диск-свидетель — это диск в хранилище кластера, предназначенный для хранения копии базы данных конфигурации кластера.The witness disk is a disk in the cluster storage that is designated to hold a copy of the cluster configuration database. Для этого примера кластера с двумя узлами в качестве конфигурации кворума будет использоваться большинство узлов и дисков.For this two-node cluster example, the quorum configuration will be Node and Disk Majority. Большинство узлов и дисков означает, что узлы и диск-свидетель содержат копии конфигурации кластера, и кластер имеет кворум, если большинство из них (два из трех) этих копий доступны.Node and Disk Majority means that the nodes and the witness disk each contain copies of the cluster configuration, and the cluster has quorum as long as a majority (two out of three) of these copies are available. Другой том (LUN) будет содержать файлы, общие для пользователей. The other volume (LUN) will contain the files that are being shared to users.К хранилищу предъявляются следующие требования.Storage requirements include the following:
- Для использования собственной поддержки дисков, включенной в компонент отказоустойчивого кластера, применяйте базовые, а не динамические диски.To use the native disk support included in failover clustering, use basic disks, not dynamic disks.
- Рекомендуется отформатировать разделы с файловой системой NTFS (для диска-свидетеля раздел должен быть NTFS).We recommend that you format the partitions with NTFS (for the witness disk, the partition must be NTFS).
- Для разделения диска на разделы можно использовать основную загрузочную запись (MBR) или таблицу разделов GPT.For the partition style of the disk, you can use either master boot record (MBR) or GUID partition table (GPT).
- Хранилище должно правильно реагировать на определенные команды SCSI. хранилище должно соответствовать стандарту, именуемому SCSI PRIMARY Commands-3 (SPC-3). The storage must respond correctly to specific SCSI commands, the storage must follow the standard called SCSI Primary Commands-3 (SPC-3). В частности, хранилище должно поддерживать постоянные резервирования, как указано в стандарте SPC-3.In particular, the storage must support Persistent Reservations as specified in the SPC-3 standard.
- Драйвер минипорта, используемый для хранения данных, должен работать с драйвером хранилища Microsoft Storport.The miniport driver used for the storage must work with the Microsoft Storport storage driver.
 При использовании iSCSI сетевые адаптеры должны быть выделены для сетевого взаимодействия или iSCSI, а не для обоих.If you use iSCSI, the network adapters must be dedicated to either network communication or iSCSI, not both. Избегайте единственных точек отказа в сетевой инфраструктуре, соединяющей узлы кластера.In the network infrastructure that connects your cluster nodes, avoid having single points of failure. Это достигается несколькими способами.There are multiple ways of accomplishing this. Вы можете подключать узлы кластера к разным сетям.You can connect your cluster nodes by multiple, distinct networks. Можно также соединить узлы кластера в одну сеть, основанную на сгруппированных сетевых адаптерах, дублированных коммутаторах и маршрутизаторах и аналогичном оборудовании, исключающем появление единственных точек отказа.Alternatively, you can connect your cluster nodes with one network that is constructed with teamed network adapters, redundant switches, redundant routers, or similar hardware that removes single points of failure.
При использовании iSCSI сетевые адаптеры должны быть выделены для сетевого взаимодействия или iSCSI, а не для обоих.If you use iSCSI, the network adapters must be dedicated to either network communication or iSCSI, not both. Избегайте единственных точек отказа в сетевой инфраструктуре, соединяющей узлы кластера.In the network infrastructure that connects your cluster nodes, avoid having single points of failure. Это достигается несколькими способами.There are multiple ways of accomplishing this. Вы можете подключать узлы кластера к разным сетям.You can connect your cluster nodes by multiple, distinct networks. Можно также соединить узлы кластера в одну сеть, основанную на сгруппированных сетевых адаптерах, дублированных коммутаторах и маршрутизаторах и аналогичном оборудовании, исключающем появление единственных точек отказа.Alternatively, you can connect your cluster nodes with one network that is constructed with teamed network adapters, redundant switches, redundant routers, or similar hardware that removes single points of failure.
 Необходимо, чтобы программное обеспечение Multipath I/O (MPIO) и программные компоненты модуля для конкретных устройств (DSM) были идентичными.It is required that the multipath I/O (MPIO) software and Device Specific Module (DSM) software components be identical. Рекомендуется, чтобы контроллеры запоминающих устройств, то есть адаптер шины (HBA), драйверы HBA и встроенное ПО HBA, присоединенные к хранилищу кластера, были идентичными.It is recommended that the mass-storage device controllers—that is, the host bus adapter (HBA), HBA drivers, and HBA firmware—that are attached to cluster storage be identical. При использовании различных HBA следует уточнить у поставщика хранилища, обеспечиваются ли при этом поддерживаемые или рекомендуемые конфигурации.If you use dissimilar HBAs, you should verify with the storage vendor that you are following their supported or recommended configurations.
Необходимо, чтобы программное обеспечение Multipath I/O (MPIO) и программные компоненты модуля для конкретных устройств (DSM) были идентичными.It is required that the multipath I/O (MPIO) software and Device Specific Module (DSM) software components be identical. Рекомендуется, чтобы контроллеры запоминающих устройств, то есть адаптер шины (HBA), драйверы HBA и встроенное ПО HBA, присоединенные к хранилищу кластера, были идентичными.It is recommended that the mass-storage device controllers—that is, the host bus adapter (HBA), HBA drivers, and HBA firmware—that are attached to cluster storage be identical. При использовании различных HBA следует уточнить у поставщика хранилища, обеспечиваются ли при этом поддерживаемые или рекомендуемые конфигурации.If you use dissimilar HBAs, you should verify with the storage vendor that you are following their supported or recommended configurations. iSCSI: If you are using iSCSI, each clustered server must have one or more network adapters or host bus adapters that are dedicated to the ISCSI storage. Сеть, используемая для iSCSI, не может использоваться для сетевого взаимодействия.The network you use for iSCSI cannot be used for network communication. На всех кластеризованных серверах сетевые адаптеры для подключения к целевому хранилищу iSCSI должны быть одинаковыми. Рекомендуется использовать адаптеры Gigabit Ethernet или с более высокой пропускной способностью.In all clustered servers, the network adapters you use to connect to the iSCSI storage target should be identical, and we recommend that you use Gigabit Ethernet or higher.
iSCSI: If you are using iSCSI, each clustered server must have one or more network adapters or host bus adapters that are dedicated to the ISCSI storage. Сеть, используемая для iSCSI, не может использоваться для сетевого взаимодействия.The network you use for iSCSI cannot be used for network communication. На всех кластеризованных серверах сетевые адаптеры для подключения к целевому хранилищу iSCSI должны быть одинаковыми. Рекомендуется использовать адаптеры Gigabit Ethernet или с более высокой пропускной способностью.In all clustered servers, the network adapters you use to connect to the iSCSI storage target should be identical, and we recommend that you use Gigabit Ethernet or higher. For a two-node failover cluster, the storage should contain at least two separate volumes (LUNs) if using a witness disk for quorum. Диск-свидетель — это диск в хранилище кластера, предназначенный для хранения копии базы данных конфигурации кластера.The witness disk is a disk in the cluster storage that is designated to hold a copy of the cluster configuration database. Для этого примера кластера с двумя узлами в качестве конфигурации кворума будет использоваться большинство узлов и дисков.For this two-node cluster example, the quorum configuration will be Node and Disk Majority. Большинство узлов и дисков означает, что узлы и диск-свидетель содержат копии конфигурации кластера, и кластер имеет кворум, если большинство из них (два из трех) этих копий доступны.Node and Disk Majority means that the nodes and the witness disk each contain copies of the cluster configuration, and the cluster has quorum as long as a majority (two out of three) of these copies are available. Другой том (LUN) будет содержать файлы, общие для пользователей.
For a two-node failover cluster, the storage should contain at least two separate volumes (LUNs) if using a witness disk for quorum. Диск-свидетель — это диск в хранилище кластера, предназначенный для хранения копии базы данных конфигурации кластера.The witness disk is a disk in the cluster storage that is designated to hold a copy of the cluster configuration database. Для этого примера кластера с двумя узлами в качестве конфигурации кворума будет использоваться большинство узлов и дисков.For this two-node cluster example, the quorum configuration will be Node and Disk Majority. Большинство узлов и дисков означает, что узлы и диск-свидетель содержат копии конфигурации кластера, и кластер имеет кворум, если большинство из них (два из трех) этих копий доступны.Node and Disk Majority means that the nodes and the witness disk each contain copies of the cluster configuration, and the cluster has quorum as long as a majority (two out of three) of these copies are available. Другой том (LUN) будет содержать файлы, общие для пользователей. The other volume (LUN) will contain the files that are being shared to users.
The other volume (LUN) will contain the files that are being shared to users. The storage must respond correctly to specific SCSI commands, the storage must follow the standard called SCSI Primary Commands-3 (SPC-3). В частности, хранилище должно поддерживать постоянные резервирования, как указано в стандарте SPC-3.In particular, the storage must support Persistent Reservations as specified in the SPC-3 standard.
The storage must respond correctly to specific SCSI commands, the storage must follow the standard called SCSI Primary Commands-3 (SPC-3). В частности, хранилище должно поддерживать постоянные резервирования, как указано в стандарте SPC-3.In particular, the storage must support Persistent Reservations as specified in the SPC-3 standard.Развертывание сетей хранения данных с отказоустойчивыми кластерамиDeploying storage area networks with failover clusters
При развертывании сети хранения данных (SAN) с отказоустойчивым кластером следует соблюдать следующие рекомендации.When deploying a storage area network (SAN) with a failover cluster, the following guidelines should be observed.
Подтвердите сертификацию хранилища: С помощью сайта каталога Windows Server убедитесь, что хранилище поставщика, включая драйверы, встроенное по и программное обеспечение, сертифицировано для windows Server 2016 или windows Server 2019.
Confirm certification of the storage: Using the Windows Server Catalog site, confirm the vendor’s storage, including drivers, firmware and software, is certified for Windows Server 2016 or Windows Server 2019.Изоляция устройств хранения данных, один кластер на устройство: Серверы из разных кластеров не должны иметь доступ к одним и тем же устройствам хранения.Isolate storage devices, one cluster per device: Servers from different clusters must not be able to access the same storage devices. В большинстве случаев LUN, используемый для одного набора серверов кластера, должен быть изолирован от всех других серверов через маскирование или зонирование LUN.In most cases, a LUN that is used for one set of cluster servers should be isolated from all other servers through LUN masking or zoning.
Рассмотрите возможность использования программного обеспечения Multipath I/O: В структуре хранилища высокой доступности можно развертывать отказоустойчивые кластеры с несколькими адаптерами шины с помощью программного обеспечения Multipath I/O.
Consider using multipath I/O software: In a highly available storage fabric, you can deploy failover clusters with multiple host bus adapters by using multipath I/O software. Это обеспечивает максимальный уровень резервирования и доступности.This provides the highest level of redundancy and availability. Многопутевое решение должно основываться на Microsoft Multipath I/O (MPIO).The multipath solution must be based on Microsoft Multipath I/O (MPIO). Поставщик оборудования хранилища может предоставить аппаратный модуль MPIO (DSM) для вашего оборудования, хотя Windows Server 2016 и Windows Server 2019 включают один или несколько DSM в составе операционной системы.The storage hardware vendor may supply an MPIO device-specific module (DSM) for your hardware, although Windows Server 2016 and Windows Server 2019 include one or more DSMs as part of the operating system.
 Confirm certification of the storage: Using the Windows Server Catalog site, confirm the vendor’s storage, including drivers, firmware and software, is certified for Windows Server 2016 or Windows Server 2019.
Confirm certification of the storage: Using the Windows Server Catalog site, confirm the vendor’s storage, including drivers, firmware and software, is certified for Windows Server 2016 or Windows Server 2019. Consider using multipath I/O software: In a highly available storage fabric, you can deploy failover clusters with multiple host bus adapters by using multipath I/O software. Это обеспечивает максимальный уровень резервирования и доступности.This provides the highest level of redundancy and availability. Многопутевое решение должно основываться на Microsoft Multipath I/O (MPIO).The multipath solution must be based on Microsoft Multipath I/O (MPIO). Поставщик оборудования хранилища может предоставить аппаратный модуль MPIO (DSM) для вашего оборудования, хотя Windows Server 2016 и Windows Server 2019 включают один или несколько DSM в составе операционной системы.The storage hardware vendor may supply an MPIO device-specific module (DSM) for your hardware, although Windows Server 2016 and Windows Server 2019 include one or more DSMs as part of the operating system.
Consider using multipath I/O software: In a highly available storage fabric, you can deploy failover clusters with multiple host bus adapters by using multipath I/O software. Это обеспечивает максимальный уровень резервирования и доступности.This provides the highest level of redundancy and availability. Многопутевое решение должно основываться на Microsoft Multipath I/O (MPIO).The multipath solution must be based on Microsoft Multipath I/O (MPIO). Поставщик оборудования хранилища может предоставить аппаратный модуль MPIO (DSM) для вашего оборудования, хотя Windows Server 2016 и Windows Server 2019 включают один или несколько DSM в составе операционной системы.The storage hardware vendor may supply an MPIO device-specific module (DSM) for your hardware, although Windows Server 2016 and Windows Server 2019 include one or more DSMs as part of the operating system.Требования к сетевой инфраструктуре и учетным записям доменаNetwork infrastructure and domain account requirements
Вам потребуется следующая сетевая инфраструктура для отказоустойчивого кластера с двумя узлами и учетной записи администратора со следующими разрешениями домена:You will need the following network infrastructure for a two-node failover cluster and an administrative account with the following domain permissions:
Сетевые параметры и IP-адреса: При использовании одинаковых сетевых адаптеров для сети также используйте одинаковые параметры связи на этих адаптерах (например, скорость, дуплексный режим, управление потоком и тип носителя).
Network settings and IP addresses: When you use identical network adapters for a network, also use identical communication settings on those adapters (for example, Speed, Duplex Mode, Flow Control, and Media Type). Кроме того, сравните параметры на сетевом адаптере и коммутаторе, к которому он подключается, и убедитесь в том, что они не конфликтуют.Also, compare the settings between the network adapter and the switch it connects to and make sure that no settings are in conflict.Если есть частные сети, которые не маршрутизируются в остальную часть сетевой инфраструктуры, убедитесь, что для каждой из этих частных сетей используется уникальная подсеть.If you have private networks that are not routed to the rest of your network infrastructure, ensure that each of these private networks uses a unique subnet. Это необходимо даже в том случае, если каждому сетевому адаптеру присвоен уникальный IP-адрес.This is necessary even if you give each network adapter a unique IP address.
Например, если в центральном офисе есть узел кластера, использующий одну физическую сеть, а в филиале есть другой узел, использующий отдельную физическую сеть, не указывайте адрес 10.0.0.0/24 для обеих сетей, даже если каждому адаптеру присвоен уникальный IP-адрес.For example, if you have a cluster node in a central office that uses one physical network, and another node in a branch office that uses a separate physical network, do not specify 10.0.0.0/24 for both networks, even if you give each adapter a unique IP address.Дополнительные сведения о сетевых адаптерах см. в разделе Требования к оборудованию для отказоустойчивого кластера с двумя узлами выше в этом разделе.For more information about the network adapters, see Hardware requirements for a two-node failover cluster, earlier in this guide.
DNS: Для разрешения имен серверы в кластере должны использовать систему доменных имен (DNS).DNS: The servers in the cluster must be using Domain Name System (DNS) for name resolution.
Можно использовать протокол динамического обновления DNS.The DNS dynamic update protocol can be used.Роль домена: Все серверы в кластере должны находиться в одном домене Active Directory.Domain role: All servers in the cluster must be in the same Active Directory domain. Мы рекомендуем, чтобы все кластерные серверы имели одинаковую роль домена (рядовой сервер или контроллер домена).As a best practice, all clustered servers should have the same domain role (either member server or domain controller). Рекомендованная роль — рядовой сервер.The recommended role is member server.
Контроллер домена: Рекомендуется, чтобы кластерные серверы были рядовыми серверами.Domain controller: We recommend that your clustered servers be member servers. Если это так, вам потребуется дополнительный сервер, который выступает в качестве контроллера домена в домене, содержащем отказоустойчивый кластер.If they are, you need an additional server that acts as the domain controller in the domain that contains your failover cluster.
Клиенты: По мере необходимости для тестирования можно подключить один или несколько сетевых клиентов к создаваемому отказоустойчивому кластеру и наблюдать за последствиями на клиенте при перемещении или отработке отказа кластеризованного файлового сервера с одного узла кластера на другой.Clients: As needed for testing, you can connect one or more networked clients to the failover cluster that you create, and observe the effect on a client when you move or fail over the clustered file server from one cluster node to the other.
Учетная запись для администрирования кластера: При первом создании кластера или добавлении в него серверов необходимо войти в домен с учетной записью, обладающей правами администратора и разрешениями на всех серверах в этом кластере.Account for administering the cluster: When you first create a cluster or add servers to it, you must be logged on to the domain with an account that has administrator rights and permissions on all servers in that cluster.
Она не обязательно должна входить в группу «Администраторы домена». Например, это может быть учетная запись пользователя домена, входящая в группу «Администраторы» на каждом кластерном сервере.The account does not need to be a Domain Admins account, but can be a Domain Users account that is in the Administrators group on each clustered server. Кроме того, если учетная запись не является учетной записью администраторов домена, то учетной записи (или группе, в которую входит эта учетная запись) необходимо предоставить разрешения Создание объектов компьютеров и чтение всех свойств в подразделении домена, которое будет размещаться в.In addition, if the account is not a Domain Admins account, the account (or the group that the account is a member of) must be given the Create Computer Objects and Read All Properties permissions in the domain organizational unit (OU) that is will reside in.
 Network settings and IP addresses: When you use identical network adapters for a network, also use identical communication settings on those adapters (for example, Speed, Duplex Mode, Flow Control, and Media Type). Кроме того, сравните параметры на сетевом адаптере и коммутаторе, к которому он подключается, и убедитесь в том, что они не конфликтуют.Also, compare the settings between the network adapter and the switch it connects to and make sure that no settings are in conflict.
Network settings and IP addresses: When you use identical network adapters for a network, also use identical communication settings on those adapters (for example, Speed, Duplex Mode, Flow Control, and Media Type). Кроме того, сравните параметры на сетевом адаптере и коммутаторе, к которому он подключается, и убедитесь в том, что они не конфликтуют.Also, compare the settings between the network adapter and the switch it connects to and make sure that no settings are in conflict. Например, если в центральном офисе есть узел кластера, использующий одну физическую сеть, а в филиале есть другой узел, использующий отдельную физическую сеть, не указывайте адрес 10.0.0.0/24 для обеих сетей, даже если каждому адаптеру присвоен уникальный IP-адрес.For example, if you have a cluster node in a central office that uses one physical network, and another node in a branch office that uses a separate physical network, do not specify 10.0.0.0/24 for both networks, even if you give each adapter a unique IP address.
Например, если в центральном офисе есть узел кластера, использующий одну физическую сеть, а в филиале есть другой узел, использующий отдельную физическую сеть, не указывайте адрес 10.0.0.0/24 для обеих сетей, даже если каждому адаптеру присвоен уникальный IP-адрес.For example, if you have a cluster node in a central office that uses one physical network, and another node in a branch office that uses a separate physical network, do not specify 10.0.0.0/24 for both networks, even if you give each adapter a unique IP address..png) Можно использовать протокол динамического обновления DNS.The DNS dynamic update protocol can be used.
Можно использовать протокол динамического обновления DNS.The DNS dynamic update protocol can be used.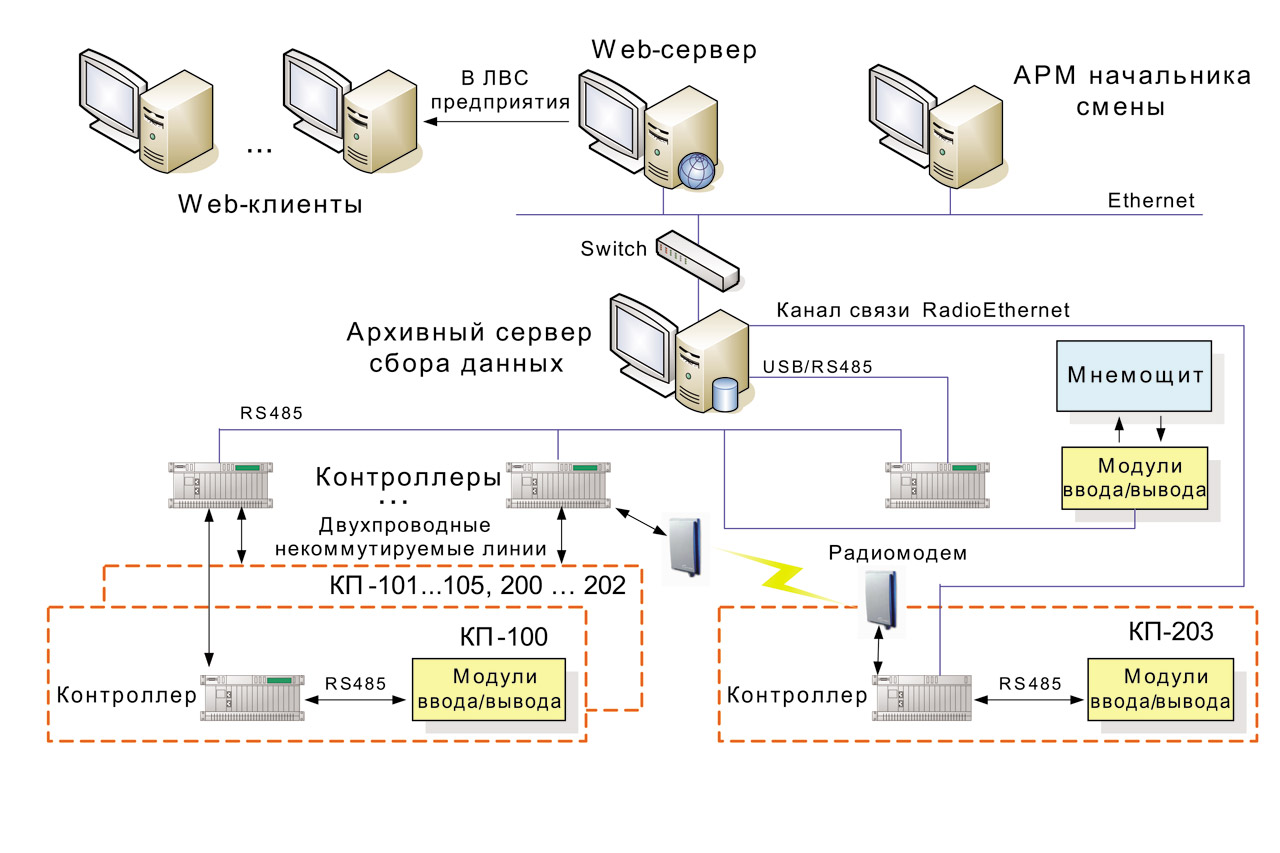
Действия по установке кластера файловых серверов с двумя узламиSteps for installing a two-node file server cluster
Чтобы установить отказоустойчивый кластер файлового сервера с двумя узлами, необходимо выполнить следующие действия. You must complete the following steps to install a two-node file server failover cluster.
You must complete the following steps to install a two-node file server failover cluster.
Шаг 1. Подключение серверов кластера к сетям и хранилищуStep 1: Connect the cluster servers to the networks and storage
Шаг 2. Установка компонента отказоустойчивого кластераStep 2: Install the failover cluster feature
Шаг 3. Проверка конфигурации кластераStep 3: Validate the cluster configuration
Шаг 4. Создание кластераStep 4: Create the cluster
Если вы уже установили узлы кластера и хотите настроить отказоустойчивый кластер файлового сервера, см. раздел действия по настройке кластера файлового сервера с двумя узлами далее в этом руководстве.If you have already installed the cluster nodes and want to configure a file server failover cluster, see Steps for configuring a two-node file server cluster, later in this guide.
Шаг 1. Подключение серверов кластера к сетям и хранилищуStep 1: Connect the cluster servers to the networks and storage
Для сети отказоустойчивого кластера Избегайте наличия единой точки отказа. For a failover cluster network, avoid having single points of failure. Это достигается несколькими способами.There are multiple ways of accomplishing this. Вы можете подключать узлы кластера к разным сетям.You can connect your cluster nodes by multiple, distinct networks. Кроме того, можно подключить узлы кластера к одной сети, созданной с помощью групповых сетевых адаптеров, избыточных коммутаторов, избыточных маршрутизаторов или аналогичного оборудования, которое удаляет единые точки отказа (если используется сеть для iSCSI, необходимо создать эту сеть в дополнение к другим сетям).Alternatively, you can connect your cluster nodes with one network that is constructed with teamed network adapters, redundant switches, redundant routers, or similar hardware that removes single points of failure (If you use a network for iSCSI, you must create this network in addition to the other networks).
For a failover cluster network, avoid having single points of failure. Это достигается несколькими способами.There are multiple ways of accomplishing this. Вы можете подключать узлы кластера к разным сетям.You can connect your cluster nodes by multiple, distinct networks. Кроме того, можно подключить узлы кластера к одной сети, созданной с помощью групповых сетевых адаптеров, избыточных коммутаторов, избыточных маршрутизаторов или аналогичного оборудования, которое удаляет единые точки отказа (если используется сеть для iSCSI, необходимо создать эту сеть в дополнение к другим сетям).Alternatively, you can connect your cluster nodes with one network that is constructed with teamed network adapters, redundant switches, redundant routers, or similar hardware that removes single points of failure (If you use a network for iSCSI, you must create this network in addition to the other networks).
Для кластера файловых серверов с двумя узлами при подключении серверов к хранилищу кластера необходимо предоставить по крайней мере два тома (LUN). For a two-node file server cluster, when you connect the servers to the cluster storage, you must expose at least two volumes (LUNs). При тщательном тестировании конфигурации можно предоставить дополнительные тома.You can expose additional volumes as needed for thorough testing of your configuration. Не предоставляйте кластеризованные тома серверам, которые не находятся в кластере.Do not expose the clustered volumes to servers that are not in the cluster.
For a two-node file server cluster, when you connect the servers to the cluster storage, you must expose at least two volumes (LUNs). При тщательном тестировании конфигурации можно предоставить дополнительные тома.You can expose additional volumes as needed for thorough testing of your configuration. Не предоставляйте кластеризованные тома серверам, которые не находятся в кластере.Do not expose the clustered volumes to servers that are not in the cluster.
Подключение серверов кластера к сетям и хранилищуTo connect the cluster servers to the networks and storage
Ознакомьтесь с подробными сведениями о сетях в разделе Требования к оборудованию для отказоустойчивого кластера с двумя узлами, а также требований к учетной записи домена для отказоустойчивого кластера с двумя узлами, ранее в этом разделе.Review the details about networks in Hardware requirements for a two-node failover cluster and Network infrastructure and domain account requirements for a two-node failover cluster, earlier in this guide.
Подключите и настройте сети, которые будут использовать серверы в кластере.Connect and configure the networks that the servers in the cluster will use.
Если конфигурация теста включает клиенты или некластеризованный контроллер домена, убедитесь, что эти компьютеры могут подключаться к кластеризованным серверам по крайней мере с одной сетью.If your test configuration includes clients or a non-clustered domain controller, make sure that these computers can connect to the clustered servers through at least one network.
Чтобы физически подключить серверы к хранилищу, следуйте инструкциям изготовителя.Follow the manufacturer’s instructions for physically connecting the servers to the storage.
Убедитесь в том, что диски (LUN), которые вы хотите использовать в кластере, доступны кластерным серверам (и только им).Ensure that the disks (LUNs) that you want to use in the cluster are exposed to the servers that you will cluster (and only those servers).
Для предоставления дисков или LUN можно использовать любой из следующих интерфейсов:You can use any of the following interfaces to expose disks or LUNs:интерфейс, предоставленный изготовителем хранилища;The interface provided by the manufacturer of the storage.
Если вы используете iSCSI, соответствующий интерфейс iSCSI.If you are using iSCSI, an appropriate iSCSI interface.
Если вы приобрели программное обеспечение, которое управляет форматом или функцией диска, следуйте инструкциям поставщика о том, как использовать это программное обеспечение с Windows Server.If you have purchased software that controls the format or function of the disk, follow instructions from the vendor about how to use that software with Windows Server.
На одном из серверов, которые необходимо включить в кластер, нажмите кнопку Пуск, выберите пункт Администрирование, затем — Управление компьютером и Управление дисками.On one of the servers that you want to cluster, click Start, click Administrative Tools, click Computer Management, and then click Disk Management.
(Если отображается диалоговое окно Контроль учетных записей пользователей, убедитесь, что отображаемое действие является нужным, и нажмите кнопку продолжить.) В окне «Управление дисками» убедитесь, что диски кластера видимы.(If the User Account Control dialog box appears, confirm that the action it displays is what you want, and then click Continue.) In Disk Management, confirm that the cluster disks are visible.Если требуется объем хранилища более 2 терабайт, а для управления форматом диска используется интерфейс Windows, преобразуйте тип разделов диска в таблицу разделов GPT.If you want to have a storage volume larger than 2 terabytes, and you are using the Windows interface to control the format of the disk, convert that disk to the partition style called GUID partition table (GPT). Для этого создайте резервную копию данных на диске, удалите все тома на диске, а затем в разделе «Управление дисками» щелкните правой кнопкой мыши диск (не раздел) и выберите команду Преобразовать в диск GPT.
To do this, back up any data on the disk, delete all volumes on the disk and then, in Disk Management, right-click the disk (not a partition) and click Convert to GPT Disk. Если объем меньше 2 терабайт, то вместо таблицы разделов GPT можно использовать тип разделов, называемый основной загрузочной записью (MBR).For volumes smaller than 2 terabytes, instead of using GPT, you can use the partition style called master boot record (MBR).Проверьте форматы всех предоставленных томов или LUN.Check the format of any exposed volume or LUN. Рекомендуется использовать NTFS в качестве формата (для диска-свидетеля требуется NTFS).We recommend NTFS for the format (for the witness disk, you must use NTFS).
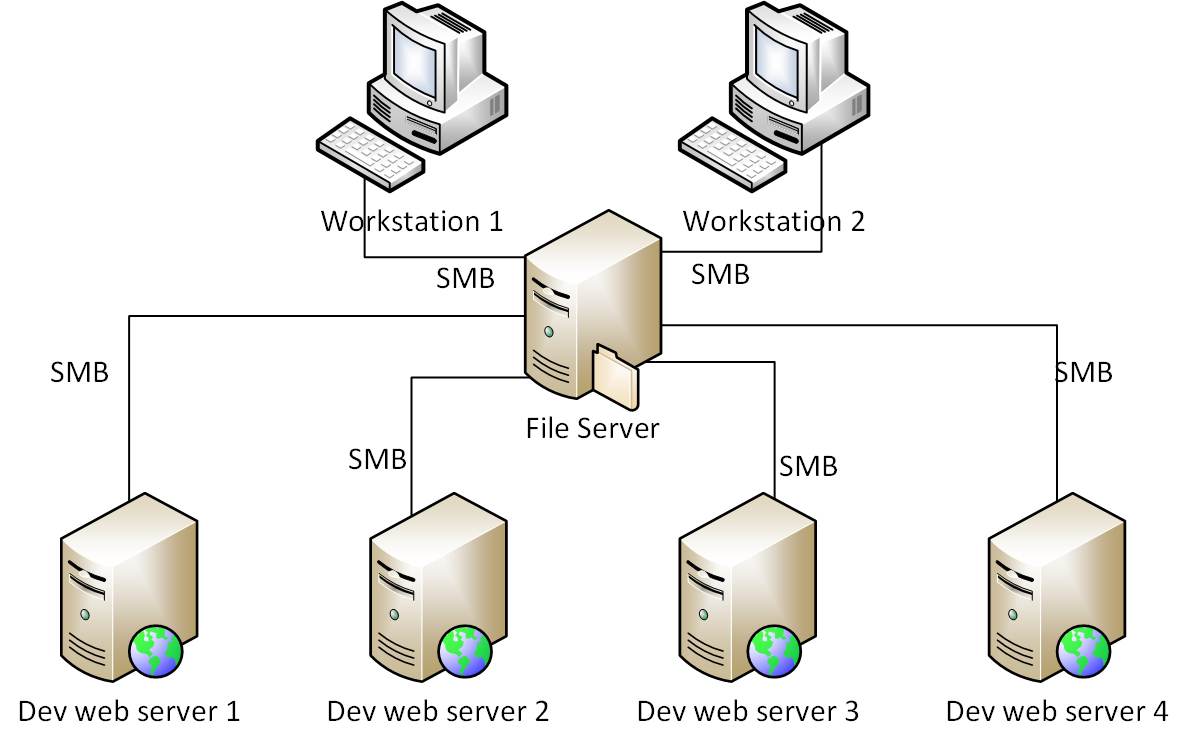
 Для предоставления дисков или LUN можно использовать любой из следующих интерфейсов:You can use any of the following interfaces to expose disks or LUNs:
Для предоставления дисков или LUN можно использовать любой из следующих интерфейсов:You can use any of the following interfaces to expose disks or LUNs: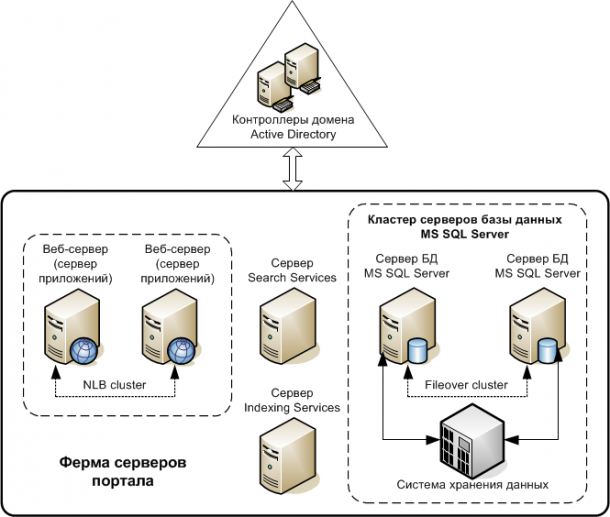 (Если отображается диалоговое окно Контроль учетных записей пользователей, убедитесь, что отображаемое действие является нужным, и нажмите кнопку продолжить.) В окне «Управление дисками» убедитесь, что диски кластера видимы.(If the User Account Control dialog box appears, confirm that the action it displays is what you want, and then click Continue.) In Disk Management, confirm that the cluster disks are visible.
(Если отображается диалоговое окно Контроль учетных записей пользователей, убедитесь, что отображаемое действие является нужным, и нажмите кнопку продолжить.) В окне «Управление дисками» убедитесь, что диски кластера видимы.(If the User Account Control dialog box appears, confirm that the action it displays is what you want, and then click Continue.) In Disk Management, confirm that the cluster disks are visible. To do this, back up any data on the disk, delete all volumes on the disk and then, in Disk Management, right-click the disk (not a partition) and click Convert to GPT Disk. Если объем меньше 2 терабайт, то вместо таблицы разделов GPT можно использовать тип разделов, называемый основной загрузочной записью (MBR).For volumes smaller than 2 terabytes, instead of using GPT, you can use the partition style called master boot record (MBR).
To do this, back up any data on the disk, delete all volumes on the disk and then, in Disk Management, right-click the disk (not a partition) and click Convert to GPT Disk. Если объем меньше 2 терабайт, то вместо таблицы разделов GPT можно использовать тип разделов, называемый основной загрузочной записью (MBR).For volumes smaller than 2 terabytes, instead of using GPT, you can use the partition style called master boot record (MBR).Шаг 2. Установка роли файлового сервера и компонента отказоустойчивого кластераStep 2: Install the file server role and failover cluster feature
На этом шаге будет установлена роль файлового сервера и компонент отказоустойчивого кластера.In this step, the file server role and failover cluster feature will be installed.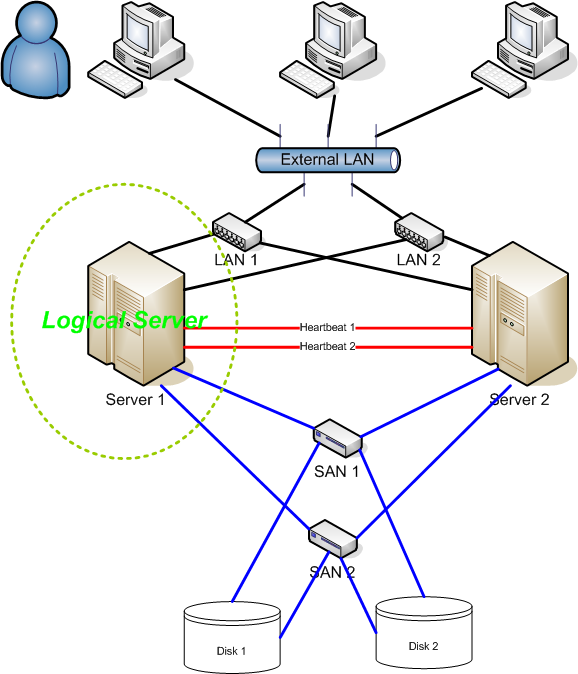 Оба сервера должны работать под управлением Windows Server 2016 или Windows Server 2019.Both servers must be running either Windows Server 2016 or Windows Server 2019.
Оба сервера должны работать под управлением Windows Server 2016 или Windows Server 2019.Both servers must be running either Windows Server 2016 or Windows Server 2019.
Использование диспетчер сервераUsing Server Manager
Откройте Диспетчер сервера и в раскрывающемся списке Управление выберите Добавить роли и компоненты.Open Server Manager and under the Manage drop down, select Add Roles and Features.
Если откроется окно перед началом , нажмите кнопку Далее.If the Before you begin window opens, choose Next.
Для типа установки выберите Установка на основе ролей или компонентов и Далее.For the Installation Type, select Role-based or feature-based installation and Next.
Убедитесь, что выбран параметр выбрать сервер из пула серверов , имя компьютера выделено и нажмите кнопку Далее.Ensure Select a server from the server pool is selected, the name of the machine is highlighted, and Next.
Для роли сервера в списке ролей откройте Файловые службы, выберите файловый сервер и Далее.For the Server Role, from the list of roles, open File Services, select File Server, and Next.
Для функций в списке компонентов выберите отказоустойчивая кластеризация.For the Features, from the list of features, select Failover Clustering. Всплывающее диалоговое окно содержит список средств администрирования, которые также устанавливаются.A popup dialog will show that lists the administration tools also being installed. Не заключайте все выбранные элементы, выберите Добавить компоненты и Далее.
Keep all the selected, choose Add Features and Next.На странице Подтверждение щелкните Установить.On the Confirmation page, select Install.
После завершения установки перезагрузите компьютер.Once the installation completes, restart the computer.
Повторите эти действия на втором компьютере.Repeat the steps on the second machine.

 Keep all the selected, choose Add Features and Next.
Keep all the selected, choose Add Features and Next.Регистрация с помощью PowerShellUsing PowerShell
Откройте сеанс администрирования PowerShell, щелкнув правой кнопкой мыши кнопку Пуск и выбрав пункт Windows PowerShell (администратор).Open an administrative PowerShell session by right-clicking the Start button and then selecting Windows PowerShell (Admin).
Чтобы установить роль файлового сервера, выполните команду:To install the File Server Role, run the command:
Install-WindowsFeature -Name FS-FileServerЧтобы установить компонент отказоустойчивой кластеризации и его средства управления, выполните команду:To install the Failover Clustering feature and its management tools, run the command:
Install-WindowsFeature -Name Failover-Clustering -IncludeManagementToolsПосле завершения установки их можно проверить с помощью команд:Once they have completed, you can verify they are installed with the commands:
Get-WindowsFeature -Name FS-FileServer Get-WindowsFeature -Name Failover-ClusteringУбедившись, что они установлены, перезапустите компьютер с помощью команды:Once verified they are installed, restart the machine with the command:
Restart-ComputerПовторите эти действия на втором сервере.
Repeat the steps on the second server.
 Repeat the steps on the second server.
Repeat the steps on the second server.Шаг 3. Проверка конфигурации кластераStep 3: Validate the cluster configuration
Перед созданием кластера настоятельно рекомендуется проверить конфигурацию.Before creating a cluster, we strongly recommend that you validate your configuration. Проверка позволяет убедиться, что конфигурация серверов, сети и хранилища соответствует набору конкретных требований для отказоустойчивых кластеров.Validation helps you confirm that the configuration of your servers, network, and storage meets a set of specific requirements for failover clusters.
Использование диспетчера отказоустойчивого кластера.Using Failover Cluster Manager
В Диспетчер сервера выберите раскрывающийся список сервис и выберите Диспетчер отказоустойчивости кластеров.From Server Manager, choose the Tools drop down and select Failover Cluster Manager.
В Диспетчер отказоустойчивости кластеров перейдите к среднему столбцу в разделе Управление и выберите проверить конфигурацию.In Failover Cluster Manager, go to the middle column under Management and choose Validate Configuration.
Если откроется окно перед началом , нажмите кнопку Далее.If the Before you begin window opens, choose Next.
В окне Выбор серверов или кластера добавьте имена двух компьютеров, которые будут узлами кластера.In the Select Servers or a Cluster window, add in the names of the two machines that will be the nodes of the cluster. Например, если имена являются NODE1 и NODE2, введите имя и нажмите кнопку Добавить.For example, if the names are NODE1 and NODE2, enter the name and select Add.
Можно также нажать кнопку Обзор , чтобы найти в Active Directory имена.You can also choose the Browse button to search Active Directory for the names. Как только они будут перечислены в списке Выбранные серверы, нажмите кнопку Далее.Once both are listed under Selected Servers, choose Next.В окне » Параметры тестирования » выберите выполнить все тесты (рекомендуется) и Далее.In the Testing Options window, select Run all tests (recommended), and Next.
На странице Подтверждение появится список всех тестов, которые будут проверяться.On the Confirmation page, it will give you the listing of all the tests it will check. Нажмите кнопку Далее, после чего начнется тестирование.Choose Next and the tests will begin.
После выполнения тестов отобразится страница Сводка .Once completed, the Summary page appears after the tests run. Чтобы просмотреть разделы справки, которые помогут вам интерпретировать результаты, щелкните Подробнее о тестах проверки кластера.To view Help topics that will help you interpret the results, click More about cluster validation tests.
На странице Сводка щелкните пункт Просмотреть отчет, чтобы просмотреть результаты тестов.While still on the Summary page, click View Report and read the test results. Внесите необходимые изменения в конфигурацию и повторно запустите тесты.Make any necessary changes in the configuration and rerun the tests.
Просмотр результатов тестов после закрытия мастера см. в разделе Системрут\клустер\репортс\валидатион Report Date and time.html.To view the results of the tests after you close the wizard, see SystemRoot\Cluster\Reports\Validation Report date and time. html.Чтобы просмотреть разделы справки о проверке кластера после закрытия мастера, в разделе Управление отказоустойчивым кластером нажмите кнопку Справка, щелкните разделы справки, перейдите на вкладку содержимое, разверните содержимое для справки по отказоустойчивому кластеру и щелкните Проверка конфигурации отказоустойчивого кластера.To view Help topics about cluster validation after you close the wizard, in Failover Cluster Management, click Help, click Help Topics, click the Contents tab, expand the contents for the failover cluster Help, and click Validating a Failover Cluster Configuration.

 Можно также нажать кнопку Обзор , чтобы найти в Active Directory имена.You can also choose the Browse button to search Active Directory for the names. Как только они будут перечислены в списке Выбранные серверы, нажмите кнопку Далее.Once both are listed under Selected Servers, choose Next.
Можно также нажать кнопку Обзор , чтобы найти в Active Directory имена.You can also choose the Browse button to search Active Directory for the names. Как только они будут перечислены в списке Выбранные серверы, нажмите кнопку Далее.Once both are listed under Selected Servers, choose Next.
 html.
html.Регистрация с помощью PowerShellUsing PowerShell
Откройте сеанс администрирования PowerShell, щелкнув правой кнопкой мыши кнопку Пуск и выбрав пункт Windows PowerShell (администратор).Open an administrative PowerShell session by right-clicking the Start button and then selecting Windows PowerShell (Admin).
Чтобы проверить компьютеры (например, имена компьютеров NODE1 и NODE2) для отказоустойчивой кластеризации, выполните команду:To validate the machines (for example, the machine names being NODE1 and NODE2) for Failover Clustering, run the command:
Test-Cluster -Node "NODE1","NODE2"Чтобы просмотреть результаты тестов после закрытия мастера, ознакомьтесь с указанным файлом (в Системрут\клустер\репортс ) , внесите необходимые изменения в конфигурацию и повторно запустите тесты.To view the results of the tests after you close the wizard, see the file specified (in SystemRoot\Cluster\Reports), then make any necessary changes in the configuration and rerun the tests.
Дополнительные сведения см. в разделе Проверка конфигурации отказоустойчивого кластера.For more info, see Validating a Failover Cluster Configuration.
Шаг 4. Создание кластераStep 4: Create the Cluster
Следующий пример приведет к созданию кластера из компьютеров и конфигурации. The following will create a cluster out of the machines and configuration you have.
The following will create a cluster out of the machines and configuration you have.
Использование диспетчера отказоустойчивого кластера.Using Failover Cluster Manager
В Диспетчер сервера выберите раскрывающийся список сервис и выберите Диспетчер отказоустойчивости кластеров.From Server Manager, choose the Tools drop down and select Failover Cluster Manager.
В Диспетчер отказоустойчивости кластеров перейдите к среднему столбцу в разделе Управление и выберите создать кластер.In Failover Cluster Manager, go to the middle column under Management and choose Create Cluster.
Если откроется окно перед началом , нажмите кнопку Далее.If the Before you begin window opens, choose Next.
В окне Выбор серверов добавьте имена двух компьютеров, которые будут узлами кластера.In the Select Servers window, add in the names of the two machines that will be the nodes of the cluster. Например, если имена являются NODE1 и NODE2, введите имя и нажмите кнопку Добавить.For example, if the names are NODE1 and NODE2, enter the name and select Add. Можно также нажать кнопку Обзор , чтобы найти в Active Directory имена.You can also choose the Browse button to search Active Directory for the names. Как только они будут перечислены в списке Выбранные серверы, нажмите кнопку Далее.Once both are listed under Selected Servers, choose Next.
В точке доступа для администрирования окна кластера введите имя кластера, который будет использоваться.In the Access Point for Administering the Cluster window, input the name of the cluster you will be using.
Обратите внимание, что это не имя, которое будет использоваться для подключения к общим файловым ресурсам с помощью.Please note that this is not the name you will be using to connect to your file shares with. Это предназначено для простого администрирования кластера.This is for simply administrating the cluster.Примечание
Если используются статические IP-адреса, необходимо выбрать сеть для использования и ввести IP-адрес, который будет использоваться для имени кластера.If you are using static IP Addresses, you will need to select the network to use and input the IP Address it will use for the cluster name. Если для IP-адресов используется DHCP, IP-адрес будет настроен автоматически.If you are using DHCP for your IP Addresses, the IP Address will be configured automatically for you.
Нажмите кнопку Далее.Choose Next.
На странице Подтверждение проверьте, что вы настроили, и нажмите кнопку Далее , чтобы создать кластер.
On the Confirmation page, verify what you have configured and select Next to create the Cluster.На странице Сводка будет предоставлена созданная конфигурация.On the Summary page, it will give you the configuration it has created. Можно выбрать пункт Просмотреть отчет, чтобы просмотреть отчет о создании.You can select View Report to see the report of the creation.

 Обратите внимание, что это не имя, которое будет использоваться для подключения к общим файловым ресурсам с помощью.Please note that this is not the name you will be using to connect to your file shares with. Это предназначено для простого администрирования кластера.This is for simply administrating the cluster.
Обратите внимание, что это не имя, которое будет использоваться для подключения к общим файловым ресурсам с помощью.Please note that this is not the name you will be using to connect to your file shares with. Это предназначено для простого администрирования кластера.This is for simply administrating the cluster. On the Confirmation page, verify what you have configured and select Next to create the Cluster.
On the Confirmation page, verify what you have configured and select Next to create the Cluster.Регистрация с помощью PowerShellUsing PowerShell
Откройте сеанс администрирования PowerShell, щелкнув правой кнопкой мыши кнопку Пуск и выбрав пункт Windows PowerShell (администратор).Open an administrative PowerShell session by right-clicking the Start button and then selecting Windows PowerShell (Admin).
Выполните следующую команду, чтобы создать кластер, если используются статические IP-адреса.Run the following command to create the cluster if you are using static IP Addresses.
Например, имена компьютеров — NODE1 и NODE2, имя кластера будет КЛАСТЕРом, а IP-адрес будет 1.1.1.1.For example, the machine names are NODE1 and NODE2, the name of the cluster will be CLUSTER, and the IP Address will be 1.1.1.1.New-Cluster -Name CLUSTER -Node "NODE1","NODE2" -StaticAddress 1.1.1.1Выполните следующую команду, чтобы создать кластер, если для IP-адресов используется DHCP.Run the following command to create the cluster if you are using DHCP for IP Addresses. Например, имена компьютеров — NODE1 и NODE2, а имя кластера будет КЛАСТЕРом.For example, the machine names are NODE1 and NODE2, and the name of the cluster will be CLUSTER.
New-Cluster -Name CLUSTER -Node "NODE1","NODE2"
 Например, имена компьютеров — NODE1 и NODE2, имя кластера будет КЛАСТЕРом, а IP-адрес будет 1.1.1.1.For example, the machine names are NODE1 and NODE2, the name of the cluster will be CLUSTER, and the IP Address will be 1.1.1.1.
Например, имена компьютеров — NODE1 и NODE2, имя кластера будет КЛАСТЕРом, а IP-адрес будет 1.1.1.1.For example, the machine names are NODE1 and NODE2, the name of the cluster will be CLUSTER, and the IP Address will be 1.1.1.1.Действия по настройке отказоустойчивого кластера файлового сервераSteps for configuring a file server failover cluster
Чтобы настроить отказоустойчивый кластер файлового сервера, выполните следующие действия. To configure a file server failover cluster, follow the below steps.
To configure a file server failover cluster, follow the below steps.
В Диспетчер сервера выберите раскрывающийся список сервис и выберите Диспетчер отказоустойчивости кластеров.From Server Manager, choose the Tools drop down and select Failover Cluster Manager.
Когда диспетчер отказоустойчивости кластеров откроется, он автоматически отобразит имя созданного кластера.When Failover Cluster Manager opens, it should automatically bring in the name of the cluster you created. Если это не так, перейдите к среднему столбцу в разделе » Управление » и выберите подключиться к кластеру.If it does not, go to the middle column under Management and choose Connect to Cluster. Введите имя созданного кластера и нажмите кнопку ОК.Input the name of the cluster you created and OK.
В дереве консоли щелкните знак «>» рядом с созданным кластером, чтобы развернуть элементы под ним.In the console tree, click the «>» sign next to the cluster that you created to expand the items underneath it.
Щелкните правой кнопкой мыши роли и выберите пункт настроить роль.Right mouse click on Roles and select Configure Role.
Если откроется окно перед началом , нажмите кнопку Далее.If the Before you begin window opens, choose Next.
В списке ролей выберите файловый сервер и Далее.In the list of roles, choose File Server and Next.
Для типа файлового сервера выберите файловый сервер для общего использования и Далее.For the File Server Type, select File Server for general use and Next.
Сведения о Scale-Out файлового сервера см. в разделе Общие сведения о Масштабируемый файловый сервер.For info about Scale-Out File Server, see Scale-Out File Server overview.В окне точка доступа клиента введите имя файлового сервера, который будет использоваться.In the Client Access Point window, input the name of the file server you will be using. Обратите внимание, что это не имя кластера.Please note that this is not the name of the cluster. Это для подключения к общей папке.This is for the file share connectivity. Например, если я хочу подключиться к серверу, выводимое \ имя будет «Server».For example, if I want to connect to \SERVER, the name inputted would be SERVER.
Примечание
Если используются статические IP-адреса, необходимо выбрать сеть для использования и ввести IP-адрес, который будет использоваться для имени кластера.If you are using static IP Addresses, you will need to select the network to use and input the IP Address it will use for the cluster name.
Если для IP-адресов используется DHCP, IP-адрес будет настроен автоматически.If you are using DHCP for your IP Addresses, the IP Address will be configured automatically for you.Нажмите кнопку Далее.Choose Next.
В окне Выбор хранилища выберите дополнительный диск (а не следящий сервер), в котором будут храниться общие папки, и нажмите кнопку Далее.In the Select Storage window, select the additional drive (not the witness) that will hold your shares, and click Next.
На странице Подтверждение Проверьте конфигурацию и нажмите кнопку Далее.On the Confirmation page, verify your configuration and select Next.
На странице Сводка будет предоставлена созданная конфигурация.On the Summary page, it will give you the configuration it has created.
Можно выбрать пункт Просмотреть отчет, чтобы просмотреть отчет о создании роли файлового сервера.You can select View Report to see the report of the file server role creation.


 Если для IP-адресов используется DHCP, IP-адрес будет настроен автоматически.If you are using DHCP for your IP Addresses, the IP Address will be configured automatically for you.
Если для IP-адресов используется DHCP, IP-адрес будет настроен автоматически.If you are using DHCP for your IP Addresses, the IP Address will be configured automatically for you. Можно выбрать пункт Просмотреть отчет, чтобы просмотреть отчет о создании роли файлового сервера.You can select View Report to see the report of the file server role creation.
Можно выбрать пункт Просмотреть отчет, чтобы просмотреть отчет о создании роли файлового сервера.You can select View Report to see the report of the file server role creation.Примечание
Если роль не добавляется или не запускается должным образом, CNO (объект имени кластера) может не иметь разрешения на создание объектов в Active Directory.If the role does not add or start correctly, the CNO (Cluster Name Object) may not have permission to create objects in Active Directory. Роли файлового сервера требуется объект компьютера с таким же именем, как и точка доступа клиента, предоставленная на шаге 8.The File Server role requires a Computer object of the same name as the «Client Access Point» provided in Step 8.
В разделе роли в дереве консоли вы увидите созданную роль с именем, которое вы создали в списке.Under Roles in the console tree, you will see the new role you created listed as the name you created.
Выделив его, на панели действия справа выберите Добавить общую папку.With it highlighted, under the Actions pane on the right, choose Add a share.Запустите мастер общих ресурсов, выполнив следующие действия:Run through the share wizard inputting the following:
- Тип общего ресурса, который он будетType of share it will be
- Расположение или путь к папке, к которой будет предоставлен общий доступLocation/path the folder shared will be
- Имя общего ресурса, к которому будут подключаться пользователиThe name of the share users will connect to
- Дополнительные параметры, такие как перечисление на основе доступа, кэширование, шифрование и т. д.Additional settings such as Access-based enumeration, caching, encryption, etc.
- Разрешения на уровне файлов, если они не используются по умолчаниюFile level permissions if they will be other than the defaults
На странице Подтверждение проверьте, что вы настроили, и нажмите кнопку создать , чтобы создать общую папку файлового сервера.
On the Confirmation page, verify what you have configured, and select Create to create the file server share.На странице результаты выберите Закрыть, если она создала общую папку.On the Results page, select Close if it created the share. Если не удалось создать общую папку, будут выдаваться все возникшие ошибки.If it could not create the share, it will give you the errors incurred.
Нажмите кнопку Закрыть.Choose Close.
Повторите эту процедуру для всех дополнительных общих папок.Repeat this process for any additional shares.
 Выделив его, на панели действия справа выберите Добавить общую папку.With it highlighted, under the Actions pane on the right, choose Add a share.
Выделив его, на панели действия справа выберите Добавить общую папку.With it highlighted, under the Actions pane on the right, choose Add a share. On the Confirmation page, verify what you have configured, and select Create to create the file server share.
On the Confirmation page, verify what you have configured, and select Create to create the file server share.Как установить Node.js на сервер с Linux – База знаний Timeweb Community
Node.js — среда выполнения JavaScript на стороне сервера. Это кроссплатформенная программа с открытым исходным кодом, которая активно используется в разработке.
В качестве примера поставим Node.js на виртуальный выделенный сервер с Ubuntu 18.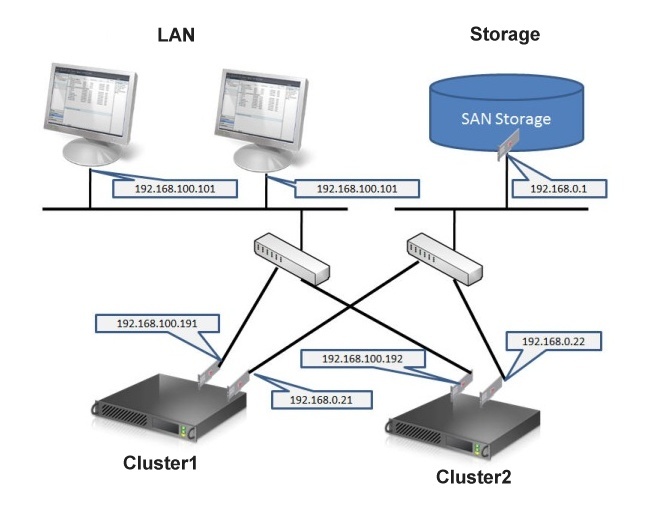 04.
04.
Как установить Node.js через панель управления сервером
У меня есть VDS на Timeweb. Поставить на него Node.js можно при создании нового сервера или через переустановку программного обеспечения.
Например, мне нужен новый сервер с Node.js. Все просто:
- Переходим на вкладку «Список VDS».
- Нажимаем на кнопку «Создать сервер».
- Пишем любое имя и нажимаем «Далее».
- В разделе «Программное обеспечение» выбираем операционную систему и дополнительное ПО — в моем случае это Ubuntu 18.04 и Node.js.
- Затем выбираем конфигурацию сервера, опционально добавляем публичный SSH-ключ и включаем защиту от DDoS.
- Нажимаем «Создать сервер» и оплачиваем выбранную конфигурацию.
У меня уже есть один VDS с установленной Ubuntu 18.04. Поэтому вместо того, чтобы создавать новый сервер, я просто переустанавливаю программное обеспечение. Для этого нужно выбрать VDS на дашборде и перейти в раздел «Система». Здесь есть вкладка «Программное обеспечение». Внутри нее — кнопка «Переустановить».
Здесь есть вкладка «Программное обеспечение». Внутри нее — кнопка «Переустановить».
Дальше все то же самое, что и при настройке конфигурации нового сервера. Необходимо выбрать операционную систему и дополнительное ПО. Затем появится предупреждение о том, что переустановка уничтожит все данные с системного накопителя. Нужно подтвердить намерение, поставив галочку, и затем нажать на кнопку «Начать переустановку».
Сервер выключится, затем включится. На привязанный к учетной записи адрес электронной почты придет письмо с информацией о том, что операционная система переустановлена. В этом сообщении будут также данные для удаленного подключения к серверу.
Чтобы убедиться в том, что установка завершена, открываем консоль в панели управления сервером или подключаемся через SSH. Выполняем команду
Готово, можно работать с Node.js.
Как установить Node.js на хостинг из репозитория Ubuntu
Если хостер не предоставляет возможность установки Node. js при конфигурации сервера, можно инсталлировать среду разработки другими способами.
js при конфигурации сервера, можно инсталлировать среду разработки другими способами.
Самый простой вариант на Ubuntu — установка из репозитория дистрибутива. Мы можем подключиться к серверу через SSH или использовать консоль в его панели управления. Разницы нет — команды в обоих случаях будут одинаковыми.
Первый шаг — обновление кэша APT. Оно выполняется следующей командой:
Мы убедились, что репозитории синхронизированы. Теперь можно загрузить и установить Node.js. Выполняем в консоли команду:
Инсталляция начнется после ввода пароля от сервера. Система установит последнюю стабильную версию Node.js. Чтобы убедиться в том, что инсталляция прошла успешна, вызовем проверку версии:
Можно также установить менеджер пакетов Node.js, который называется NPM. Для этого в терминале выполняем команду
Если вы решите, что Node.js вам не нужна, удалите платформу следующей командой:
Это самый простой способ. Минус у него один — вы не можете выбрать версию Node. js, которая будет установлена на сервер. Если для вас это важно, используйте другой способ инсталляции.
js, которая будет установлена на сервер. Если для вас это важно, используйте другой способ инсталляции.
Как установить Node.js на сервер с помощью NVM
Node Version Manager (NVM) позволяет при установке выбрать конкретную версию Node.js. Это полезно, если вы хотите использовать не последнюю стабильную сборку, а одну из предыдущих версий.
Первый шаг — установка NVM. Для этого мы будем использовать wget. Если вы не уверены, что он у вас есть, выполните в консоли следующую команду:
Затем инсталлируйте последнюю версию nvm:
wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.35.3/install.sh | bash
Обратите внимание на номер версии — в нашем случае это 0.35.3. Посмотреть его можно на GitHub, где лежат файлы nvm.
Затем нужно перелогиниться в систему или обновить данные. Для этого выполните команду:
Теперь можно с помощью NVM посмотреть все доступные для установки версии Node.js и выбрать подходящую. Сначала выведем список для Ubuntu:
Чтобы выбрать версию, укажите ее номер в команде. Например:
Например:
Чтобы убедиться в том, что установка прошла успешно, проверьте версию Node.js:
Если в консоли отобразился номер сборки, значит, все хорошо.
Если вы решите отказаться от Node.js, то избавьтесь от NVM. Сначала нужно его деактивировать:
А затем удалить:
После этого можно будет заново установить Node.js тем же методом, если появится такая необходимость.
Как установить Node.js из репозитория бинарных дистрибутивов
Это тоже простой способ, который позволяет получить новую версию Node.js с помощью пары запросов. Например, для установки версии 12 на Ubuntu нужно выполнить в терминале две команды:
curl -sL https://deb.nodesource.com/setup_12.x | sudo -E bash - sudo apt-get install -y nodejs
Первая команда добавляет репозиторий, вторая — устанавливает среду.
Полный список команд можно посмотреть на GitHub. Там есть подробные описания автоматической и ручной установок Node.js на Ubuntu и Debian.
Компоненты Kubernetes | Kubernetes
При развёртывании Kubernetes вы имеете дело с кластером.
Кластер Kubernetes cluster состоит из набор машин, так называемые узлы, которые запускают контейнеризированные приложения. Кластер имеет как минимум один рабочий узел.
В рабочих узлах размещены поды, являющиеся компонентами приложения. Плоскость управления управляет рабочими узлами и подами в кластере. В промышленных средах плоскость управления обычно запускается на нескольких компьютерах, а кластер, как правило, развёртывается на нескольких узлах, гарантируя отказоустойчивость и высокую надёжность.
На этой странице в общих чертах описывается различные компоненты, необходимые для работы кластера Kubernetes.
Ниже показана диаграмма кластера Kubernetes со всеми связанными компонентами.
Плоскость управления компонентами
Компоненты панели управления отвечают за основные операции кластера (например, планирование), а также обрабатывают события кластера (например, запускают новый под, когда поле replicas развертывания не соответствует требуемому количеству реплик).
Компоненты панели управления могут быть запущены на любой машине в кластере. Однако для простоты сценарии настройки обычно запускают все компоненты панели управления на одном компьютере и в то же время не позволяют запускать пользовательские контейнеры на этом компьютере. Смотрите страницу Создание высоконадёжных кластеров для примера настройки нескольких ведущих виртуальных машин.
kube-apiserver
Сервер API — компонент Kubernetes панели управления, который представляет API Kubernetes. API-сервер — это клиентская часть панели управления Kubernetes
Основной реализацией API-сервера Kubernetes является kube-apiserver. kube-apiserver предназначен для горизонтального масштабирования, то есть развёртывание на несколько экземпляров. Вы можете запустить несколько экземпляров kube-apiserver и сбалансировать трафик между этими экземплярами.
etcd
Распределённое и высоконадёжное хранилище данных в формате «ключ-значение», которое используется как основное хранилище всех данных кластера в Kubernetes.
Если ваш кластер Kubernetes использует etcd в качестве основного хранилища, убедитесь, что у вас настроено резервное копирование данных.
Вы можете найти подробную информацию о etcd в официальной документации.
kube-scheduler
Компонент плоскости управления, который отслеживает созданные поды без привязанного узла и выбирает узел, на котором они должны работать.
При планировании развёртывания подов на узлах учитываются множество факторов, включая требования к ресурсам, ограничения, связанные с аппаратными/программными политиками, принадлежности (affinity) и непринадлежности (anti-affinity) узлов/подов, местонахождения данных, предельных сроков.
kube-controller-manager
Компонент Control Plane запускает процессы контроллера.
Вполне логично, что каждый контроллер в свою очередь представляет собой отдельный процесс, и для упрощения все такие процессы скомпилированы в один двоичный файл и выполняются в одном процессе.
Эти контроллеры включают:
- Контроллер узла (Node Controller): уведомляет и реагирует на сбои узла.
- Контроллер репликации (Replication Controller): поддерживает правильное количество подов для каждого объекта контроллера репликации в системе.
- Контроллер конечных точек (Endpoints Controller): заполняет объект конечных точек (Endpoints), то есть связывает сервисы (Services) и поды (Pods).
- Контроллеры учетных записей и токенов (Account & Token Controllers): создают стандартные учетные записи и токены доступа API для новых пространств имен.
cloud-controller-manager
cloud-controller-manager запускает контроллеры, которые взаимодействуют с основными облачными провайдерами. Двоичный файл cloud-controller-manager — это альфа-функциональность, появившиеся в Kubernetes 1.6.
cloud-controller-manager запускает только циклы контроллера, относящиеся к облачному провайдеру. Вам нужно отключить эти циклы контроллера в kube-controller-manager. Вы можете отключить циклы контроллера, установив флаг --cloud-provider со значением external при запуске kube-controller-manager.
С помощью cloud-controller-manager код как облачных провайдеров, так и самого Kubernetes может разрабатываться независимо друг от друга. В предыдущих версиях код ядра Kubernetes зависел от кода, предназначенного для функциональности облачных провайдеров. В будущих выпусках код, специфичный для облачных провайдеров, должен поддерживаться самим облачным провайдером и компоноваться с cloud-controller-manager во время запуска Kubernetes.
Следующие контроллеры зависят от облачных провайдеров:
- Контроллер узла (Node Controller): проверяет облачный провайдер, чтобы определить, был ли удален узел в облаке после того, как он перестал работать
- Контроллер маршрутов (Route Controller): настраивает маршруты в основной инфраструктуре облака
- Контроллер сервисов (Service Controller): создаёт, обновляет и удаляет балансировщики нагрузки облачного провайдера.
- Контроллер тома (Volume Controller): создаёт, присоединяет и монтирует тома, а также взаимодействует с облачным провайдером для оркестрации томов.

Компоненты узла
Компоненты узла работают на каждом узле, поддерживая работу подов и среды выполнения Kubernetes.
kubelet
Агент, работающий на каждом узле в кластере. Он следит за тем, чтобы контейнеры были запущены в поде.
Утилита kubelet принимает набор PodSpecs, и гарантирует работоспособность и исправность определённых в них контейнеров. Агент kubelet не отвечает за контейнеры, не созданные Kubernetes.
kube-proxy
kube-proxy — сетевой прокси, работающий на каждом узле в кластере, и реализующий часть концепции сервис.
kube-proxy конфигурирует правила сети на узлах. При помощи них разрешаются сетевые подключения к вашими подам изнутри и снаружи кластера.
kube-proxy использует уровень фильтрации пакетов в операционной системы, если он доступен. В противном случае, kube-proxy сам обрабатывает передачу сетевого трафика.
Среда выполнения контейнера
Среда выполнения контейнера — это программа, предназначенная для выполнения контейнеров.
Kubernetes поддерживает несколько сред для запуска контейнеров: Docker, containerd, CRI-O, и любая реализация Kubernetes CRI (Container Runtime Interface).
Дополнения
Дополнения используют ресурсы Kubernetes (DaemonSet, Deployment и т.д.) для расширения функциональности кластера. Поскольку дополнения охватывают весь кластер, ресурсы относятся к пространству имен kube-system.
Некоторые из дополнений описаны ниже; более подробный список доступных расширений вы можете найти на странице Дополнения.
DNS
Хотя прочие дополнения не являются строго обязательными, однако при этом у всех Kubernetes-кластеров должен быть кластерный DNS, так как многие примеры предполагают его наличие.
Кластерный DNS — это DNS-сервер наряду с другими DNS-серверами в вашем окружении, который обновляет DNS-записи для сервисов Kubernetes.
Контейнеры, запущенные посредством Kubernetes, автоматически включают этот DNS-сервер в свои DNS.
Веб-интерфейс (Dashboard)
Dashboard — это универсальный веб-интерфейс для кластеров Kubernetes. С помощью этой панели, пользователи могут управлять и устранять неполадки кластера и приложений, работающих в кластере.
С помощью этой панели, пользователи могут управлять и устранять неполадки кластера и приложений, работающих в кластере.
Мониторинг ресурсов контейнера
Мониторинг ресурсов контейнера записывает общие метрики о контейнерах в виде временных рядов в центральной базе данных и предлагает пользовательский интерфейс для просмотра этих данных.
Логирование кластера
Механизм логирования кластера отвечает за сохранение логов контейнера в централизованном хранилище логов с возможностью их поиска/просмотра.
Что дальше
Изменено June 01, 2020 at 9:17 AM PST: add ru pages (1224efaa6)ylabio/node-server: Сервер на node.js и mongodb для API
Requirements
- Node.js >= 7
- MongoDB >= 3
Settings
Настроойки всех сервисов проекта в файле ./config.js
Локальные настройки в ./config-local.js В них переопределяются общие настройки на значения,
которые не должны попасть в репозиторий. Например параметры доступа к базе.
В файле ./config-spec.js настройки для автотестирование, в частности, указывается тестовая база данных.
Develop
npm install Установка пакетов при развертывании или обновлениии кода.
npm test Автотестирование.
npm run eslint Проверка синтаксиса.
npm start Запуск сервера. Автоматически создаётся база, коллекции, индексы, если чего-то нет.
Production
Используется менеджер процессов PM2.
npm install pm2 -g Установка PM2.
pm2 start process.json Запуск сервера.
pm2 stop process.json Остановка.
pm2 delete process.json Удаление сервера из менеджера процессов.
pm2 monit Мониторинг процесса.
pm2 logs all Просмотр логов процессов
File uploads
Используется Google Storage. Загрузка выполняется проксированием потока в Google Storage. В ngnix необходимо отключить кэширование загружаемых данных и установить необходимый лимит post данных. Отключать кэшировать, чтобы nginx не сохранял фрагменты даных, а сразу отдавал в поток node.
Ключ доступа в /keys/google-storage
Nginx
Пример настройки сервера nginx
server {
server_name example.com;
client_max_body_size 4g; // лимит загружаемых файлов
proxy_request_buffering off; // не сохранять на сервере
location / {
// Все запросы в node.js
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Frame-Options SAMEORIGIN;
proxy_pass http://127.0.0.1:8040; //локальный хост сервера на node.js
}
}
Установка CORS в google storage
Установка CORS для доступа к файлам с разных хостов (со фронта проекта)
Сначала установаить gutils и авторизоваться
gsutil cors set gs-cors-config.json gs://backet-image
gsutil cors set gs-cors-config.json gs://backet-other
API Doc
По адресу http://{host сервера}/api/v1/docs развернута документация в swagger ui
Baidu Optimizes Rack Server Density with Intel® Node Manager
Поиск на сайте Intel.com
Вы можете выполнять поиск по всему сайту Intel.com различными способами.
- Торговое наименование: Core i9
- Номер документа: 123456
- Кодовое название: Kaby Lake
- Специальные операторы: “Ice Lake”, Ice AND Lake, Ice OR Lake, Ice*
Ссылки по теме
Вы также можете воспользоваться быстрыми ссылками ниже, чтобы посмотреть результаты самых популярных поисковых запросов.
Недавние поисковые запросы
Руководство для начинающих по серверной веб-разработке с помощью Node.js | Автор: Чен Хуэй Цзин
Когда я начинал работать в веб-индустрии пару лет назад, я наткнулся на курс по компьютерным сетям профессора Дэвида Ветералла на Coursera. К сожалению, он больше не доступен, но лекции по-прежнему доступны на веб-сайте Pearson.
Мне очень понравился этот курс, потому что он объяснил, что происходило под капотом в доступной форме, так что, если вы можете достать учебник, Компьютерные сети, прочтите его, чтобы узнать все подробности чудес света. сети.
Computer Networks, 5-е изданиеЗдесь, однако, я собираюсь охватить лишь краткий обзор вещей для контекста. HTTP (протокол передачи гипертекста) — это протокол связи, используемый в компьютерных сетях. В Интернете их много, например SMTP (простой протокол передачи почты), FTP (протокол передачи файлов), POP3 (протокол почтового отделения 3) и так далее.
Эти протоколы позволяют устройствам с совершенно разным аппаратным и программным обеспечением взаимодействовать друг с другом, поскольку они обеспечивают четко определенные форматы сообщений, правила, синтаксис, семантику и т. Д.Это означает, что пока устройство поддерживает определенный протокол, оно может взаимодействовать с любым другим устройством в сети.
От TCP / IP и OSI: в чем разница между двумя моделями? Операционные системыобычно поставляются с готовой поддержкой сетевых протоколов, таких как HTTP, что объясняет, почему нам не нужно явно устанавливать какое-либо дополнительное программное обеспечение для доступа в Интернет. Большинство сетевых протоколов поддерживают открытое соединение между двумя устройствами, что позволяет им передавать данные туда и обратно.
HTTP, на котором работает Интернет, отличается. Он известен как протокол без установления соединения, поскольку основан на режиме работы запрос / ответ. Веб-браузеры запрашивают на сервере изображения, шрифты, контент и т. Д., Но после выполнения запроса соединение между браузером и сервером разрывается.
Упрощение запроса / ответаТермин «сервер» может немного сбивать с толку людей, плохо знакомых с отраслью, поскольку он может относиться как к аппаратному обеспечению (физические компьютеры, на которых размещены все файлы и программное обеспечение, требуемое веб-сайтами), так и к программному обеспечению (программа, позволяющая пользователям для доступа к этим файлам в сети).
Сегодня мы поговорим о программном обеспечении. Но сначала несколько определений. URL обозначает универсальный указатель ресурсов и состоит из 3 частей: протокола , сервера и запрошенного файла .
Анатомия URL-адреса Протокол HTTP определяет несколько методов, которые браузер может использовать, чтобы попросить сервер выполнить ряд различных действий, наиболее распространенными из которых являются GET и POST . Когда пользователь щелкает ссылку или вводит URL-адрес в адресной строке, браузер отправляет на сервер запрос GET , чтобы получить ресурс, определенный в URL-адресе.
Серверу необходимо знать, как обрабатывать этот HTTP-запрос, чтобы получить правильный файл, а затем отправить его обратно браузеру, который его запросил. Самыми популярными программами веб-серверов, которые справляются с этим, являются Apache и NGINX.
Веб-серверы обрабатывают входящие запросы и отвечают на них соответственно.Оба являются полными пакетами программного обеспечения с открытым исходным кодом, которые включают такие функции, как схемы аутентификации, перезапись URL-адресов, ведение журнала и проксирование, и это лишь некоторые из них. И Apache, и NGINX написаны на C.Технически вы можете написать веб-сервер на любом языке. Python, Go, Ruby — этот список можно продолжать довольно долго. Просто одни языки справляются с определенными задачами лучше, чем другие.
Node.js — это среда выполнения Javascript, построенная на движке Javascript V8 Chrome. Он поставляется с модулем http, который предоставляет набор функций и классов для создания HTTP-сервера.
Для этого базового HTTP-сервера мы также будем использовать файловую систему, путь и URL-адрес, все из которых являются встроенными в Node.js-модулей.
Начните с импорта необходимых модулей.
const http = require ('http') // Для использования HTTP-интерфейсов в Node.js
const fs = require ('fs') // Для взаимодействия с файловой системой
const path = require ('path') // Для работы с путями файлов и каталогов
const url = require ('url') // Для разрешения и синтаксического анализа URL Мы также создадим словарь типов MIME, чтобы мы могли назначить соответствующий тип MIME запрошенному ресурсу на основе на его расширении.Полный список типов MIME можно найти в Internet Assigned Numbers Authority.
const mimeTypes = {
'.html': 'text / html',
'.js': 'text / javascript',
'.css': 'text / css',
'.ico': 'image / x-icon ',
' .png ':' image / png ',
' .jpg ':' image / jpeg ',
' .gif ':' image / gif ',
' .svg ':' image / svg + xml ',
' .json ':' application / json ',
' .woff ':' font / woff ',
' .woff2 ':' font / woff2 '
} Теперь мы можем создать HTTP-сервер с http.createServer () , которая вернет новый экземпляр http.Server .
const server = http.createServer ()
Мы передадим функцию обработчика запросов в createServer () с объектами request и response . Эта функция вызывается один раз каждый раз, когда к серверу делается HTTP-запрос.
server.on ('request', (req, res) => {
// здесь нужно сделать больше
}) Сервер запускается путем вызова метода listen на объекте сервера с номер порта, который мы хотим, чтобы сервер слушал, например 5000 .
server.listen (5000)
Объект запроса является экземпляром IncomingMessage и позволяет нам получать доступ ко всем видам информации о запросе, такой как статус ответа, заголовки и данные.
Объект ответа является экземпляром ServerResponse, который является потоком с возможностью записи и предоставляет множество методов для отправки данных обратно клиенту.
В обработчике запросов мы хотим сделать следующее:
- Анализировать входящий запрос и обрабатывать те, которые не имеют расширений
const parsedUrl = new URL (req.url, 'https://node-http.glitch.me/')
let pathName = parsedUrl.pathname
let ext = path.extname (pathName)// Для обработки URL-адресов с завершающим '/' путем удаления вышеупомянутого '/ '
// затем перенаправляем пользователя на этот URL с использованием заголовка' Location '
if (pathName! ==' / '&& pathName [pathName.length - 1] ===' / ') {
res.writeHead (302 , {'Location': pathName.slice (0, -1)})
res.end ()
return
}// Если запрос относится к корневому каталогу, вернуть index.html
// В противном случае добавьте '.html' к любому другому запросу без расширения
if (pathName === '/') {
ext = '.html'
pathName = '/index.html'
} else if (! ext) {
ext = '.html'
pathName + = ext
}
- Выполните некоторые элементарные проверки, чтобы определить, существует ли запрошенный ресурс, и отреагировать соответствующим образом
// Создайте действительный путь к файлу, чтобы соответствующий к ресурсам можно получить доступ
const filePath = path.join (process.cwd (), '/ public', pathName)
// Проверяем, существует ли запрошенный актив на сервере
fs.exists (filePath, function (exists, err) {
// Если ресурс не существует, ответьте 404 Not Found
if (! exists ||! mimeTypes [ext]) {
console.log ('Файл не exist: '+ pathName)
res.writeHead (404, {' Content-Type ':' text / plain '})
res.write (' 404 Not Found ')
res.end ()
return
}
/ / В противном случае ответьте статусом 200 OK,
// и добавьте правильный заголовок типа содержимого
res.writeHead (200, {'Content-Type': mimeTypes [ext]})
// Прочтите файл с компьютера и передать его в ответ
const fileStream = fs.createReadStream (filePath)
fileStream.pipe (res)
})
Весь код размещен на Glitch, и вы можете сделать ремикс проекта, если хотите.
https://glitch.com/edit/#!/node-http
Фреймворки Node.js, такие как Express, Koa.js и Hapi.js, поставляются с различными полезными функциями промежуточного программного обеспечения в дополнение к множеству других полезных функций которые избавляют разработчиков от необходимости писать сами.
Лично я считаю, что хорошо сначала изучить основы без фреймворков, просто для того, чтобы понять, что происходит под капотом, а после этого сходить с ума с любым фреймворком, который вам нравится.
Express имеет собственное встроенное промежуточное ПО для обслуживания статических файлов, поэтому код, необходимый для выполнения тех же действий, что и в собственном Node.js, намного короче.
const express = require ('express')
const app = express () // Обслуживать статические файлы из общей папки
app.use (express.static ('public')) // Обслуживать индекс. html, когда пользователи обращаются к корневому каталогу
// с помощью res.sendFile ()
app.get ('/', (req, res) => {
res.sendFile (__ dirname + '/ public / index.html ')
}) app.listen (5000) Koa.js не связывает какое-либо промежуточное ПО в своем ядре, поэтому любое необходимое промежуточное ПО должно устанавливаться отдельно. Последняя версия Koa.js использует асинхронные функции в пользу обратных вызовов. Для обслуживания статических файлов вы можете использовать промежуточное ПО koa-static .
const serve = require ('koa-static')
const koa = require ('koa')
const app = new koa () // Обслуживать статические файлы из 'общедоступной' папки
// По умолчанию koa -static будет обслуживать индекс.html в корневом каталоге
app.use (serve (__ dirname + '/public'))app.listen(5000) Hapi.js поддерживает конфигурацию и вращается вокруг настройки объекта server . Он использует плагины для расширения возможностей, таких как маршрутизация, аутентификация и так далее. Для обслуживания статических файлов нам понадобится плагин под названием inert .
const path = require ('path')
const hapi = require ('hapi')
const inert = require ('inert') // Маршруты могут быть настроены на сервере объекта
const server = new hapi.Сервер ({
порт: 5000,
маршруты: {
файлы: {
relativeTo: path.join (__ dirname, 'public')
}
}
}) const init = async () => {
// server. Команда register () добавляет плагин в приложение
await server.register (inert) // inert добавляет обработчик каталога в
// указывает маршрут для обслуживания нескольких файлов
server.route ({
method: 'GET',
путь: '/ {param *}',
обработчик: {
каталог: {
путь: '.',
redirectToSlash: true,
index: true
}
}
}) await server.start ()
} init () У каждой из этих платформ есть свои плюсы и минусы, и они будут более очевидны для больших приложений, чем просто для обслуживания одной HTML-страницы. Выбор фреймворка во многом зависит от реальных требований проекта, над которым вы работаете.
Если сетевая сторона вещей всегда была для вас черным ящиком, надеюсь, эта статья может послужить полезным введением в протокол, на котором работает Интернет. Я также настоятельно рекомендую прочитать Node.js API документация, которая очень хорошо написана и является большим подспорьем для всех, кто плохо знаком с Node.js.
Что такое узел в компьютерной сети?
Узел — это любое физическое устройство в сети других инструментов, которое может отправлять, получать или пересылать информацию. Персональный компьютер — самый распространенный узел. Он называется компьютерным узлом или интернет-узлом .
Модемы, коммутаторы, концентраторы, мосты, серверы и принтеры также являются узлами, как и другие устройства, которые подключаются через Wi-Fi или Ethernet.Например, в сети, соединяющей три компьютера и один принтер, а также еще два беспроводных устройства, всего шесть узлов.
Узлы в компьютерной сети должны иметь определенную форму идентификации, например IP-адрес или MAC-адрес, чтобы другие сетевые устройства могли их распознать. Узел без этой информации или тот, который находится в автономном режиме, больше не функционирует как узел.
Что делает сетевой узел?
Сетевые узлы — это физические части, составляющие сеть.Обычно они включают в себя любое устройство, которое получает и передает информацию. Но они могут получать и хранить данные, передавать информацию в другое место или вместо этого создавать и отправлять данные.
Например, компьютерный узел может создавать резервные копии файлов в Интернете или отправлять электронную почту, но он также может транслировать видео и загружать другие файлы. Сетевой принтер может получать запросы на печать от других устройств в сети, а сканер может отправлять изображения обратно на компьютер. Маршрутизатор определяет, какие данные поступают на какие устройства, запрашивающие загрузку файлов в системе, но он также может отправлять запросы в общедоступный Интернет.
Другие типы узлов
В волоконно-оптической сети кабельного телевидения узлами являются дома или предприятия, которые подключаются к одному и тому же волоконно-оптическому приемнику.
Другим примером узла является устройство, которое обеспечивает интеллектуальную сетевую услугу в сотовой сети, например контроллер базовой станции (BSC) или узел поддержки GPRS шлюза (GGSN). Другими словами, мобильный узел — это то, что обеспечивает программные средства управления оборудованием, например структуру с антеннами, которые передают сигналы на все устройства в сети.
Уильям Бут на UnsplashСуперузл — это узел в одноранговой сети, который функционирует не только как обычный узел, но также как прокси-сервер и устройство, которое передает информацию другим пользователям в системе P2P. Из-за этого суперузлам требуется больше ЦП и пропускной способности, чем для обычных узлов.
Что такое проблема конечного узла?
Термин «проблема конечного узла» относится к риску безопасности, который возникает, когда пользователи подключают свои компьютеры или другие устройства к чувствительной сети физически (например, на работе) или через облако (из любого места), в то же время используя это то же устройство для выполнения незащищенных действий.
Некоторые примеры включают в себя конечного пользователя, который берет свой рабочий ноутбук домой, но затем проверяет свою электронную почту в незащищенной сети, например в кафе, или пользователя, который подключает свой персональный компьютер или телефон к сети Wi-Fi компании.
Один из наиболее серьезных рисков для корпоративной сети — это взломанное личное устройство, которое кто-то использует в этой сети. Проблема довольно ясна: смешивание потенциально незащищенной сети и бизнес-сети, которая, вероятно, содержит конфиденциальные данные.
Устройство конечного пользователя может быть заражено вредоносным ПО с такими вещами, как кейлоггеры или программы передачи файлов, которые извлекают конфиденциальную информацию или перемещают вредоносное ПО в частную сеть после входа в систему.
Решить эту проблему могут сети VPN и двухфакторная аутентификация. То же самое и со специальным загрузочным клиентским программным обеспечением, которое может использовать только определенные программы удаленного доступа.
Однако есть еще один метод — научить пользователей правильно защищать свои устройства. Персональные ноутбуки могут использовать антивирусную программу для защиты своих файлов от вредоносных программ, а смартфоны могут использовать аналогичное приложение для защиты от вредоносных программ для обнаружения вирусов и других угроз, прежде чем они причинят какой-либо вред.
Другие значения узлов
«Узел» также описывает компьютерный файл в древовидной структуре данных. Как и в реальном дереве, ветви которого держат листья, папки в структуре данных содержат записи. Файлы называются листьями или листовыми узлами .
Слово «узел» также встречается в node.js, который представляет собой среду выполнения JavaScript, которая выполняет код JavaScript на стороне сервера. «Js» здесь не относится к расширению файла JS, используемому с файлами JavaScript; это просто название инструмента.
Спасибо, что сообщили нам!
Расскажите, почему!
Другой Недостаточно деталей Сложно понять Веб-сервер— Можно ли сказать, что node.js — это веб-сервер?
Как я чувствую твою боль!
Как и многие, мне было трудно понять суть Node.js, потому что большинство людей пишут / говорят только о той части Node, которую они считают полезной, а та часть, которую они считают интересной, обычно является вторичным преимуществом Node, а не его Основная цель. Должен сказать, что я считаю безумием говорить, что Node — это просто среда выполнения JavaScript.Использование JavaScript в Node и выбор среды выполнения V8 — это просто средство для решения проблемы , лучшие инструменты для решения проблемы, которую разработчики Node хотели решить.
Основная цельNode — сделать управление пользовательскими событиями в веб-приложении более эффективным. Итак, Node , в подавляющем большинстве случаев, используется в серверной части веб-приложения. Управление событиями требует, чтобы что-то на сервере прослушивало эти пользовательские события. Поэтому необходимо настроить http-сервер для маршрутизации каждого события в соответствующий сценарий обработчика.Node предоставляет основу для быстрой настройки сервера для прослушивания выделенного порта для запросов пользователей. Node использует JavaScript для обработки событий, потому что JavaScript имеет функции обратного вызова: это позволяет приостановить выполнение одной задачи до тех пор, пока не будет возвращен результат зависимой задачи. Не многие другие языки имеют эту функцию, а те, которые имеют, могут не иметь столь эффективного интерпретатора, как среда выполнения Google V8. Большинство веб-разработчиков знают JavaScript, поэтому нет необходимости в дополнительном изучении языка с помощью Node. Более того, наличие функций обратного вызова позволяет помещать все пользовательские задачи в один поток без явной блокировки, применяемой к задачам, требующим доступа к базе данных или файловой системе.И это то, что приводит к превосходной эффективности выполнения Node при интенсивном одновременном использовании — основной цели его разработки.
Чтобы помочь пользователям Node быстро писать внутренний код, разработчики Node также организовали как встроенную библиотеку JS для рутинных задач (например, вопросы, связанные с HTTP-запросами, строковое (де) кодирование, потоки и т. Д.), Так и NPM (диспетчер пакетов узла) репозиторий: это поддерживаемый пользователем набор пакетов сценариев с открытым исходным кодом для различных стандартных и пользовательских функций.Все проекты Node позволяют импортировать пакеты NPM в проект с помощью установленной команды npm install .
Пользовательские запросы, обрабатываемые через Node, будут необходимы веб-приложению, например, аутентификация, запросы к базе данных, управление контентом (Strapi CMS) и т. Д. Все это будет отправлено на порт Node. (Там, где анализ данных, полученных из базы данных, занимает много времени ЦП, этот тип процесса лучше всего поместить в отдельный поток, чтобы он не замедлял выполнение более простых пользовательских запросов.) Другие типы пользовательских запросов, например чтобы загрузить другую веб-страницу, загрузить файлы CSS / JS / изображений и т. д., браузер по-прежнему будет отправлять их на порт (ы) по умолчанию на сервере, где их будет обрабатывать программа веб-сервера (Apache, NGinx и т. д.).
Итак, на практике , Node — это в основном каркас для быстрого создания сервера и обработки событий, но он заменяет только некоторые функций программы веб-сервера.
Другие способы использования Node, не связанные с серверной частью, просто используют ту или иную его функцию, например.грамм. двигатель V8. Например, инструменты сборки интерфейса Grunt и Gulp используют Node.js для обработки сценария сборки, который можно закодировать для преобразования SASS в CSS, минимизации файлов CSS / JS, оптимизации размера / загрузки изображения и т. Д. Но такая работа действительно просто побочный продукт использования Node, а не его основное использование, которое заключается в создании эффективных внутренних процессов для веб-приложений.
Что такое Node.js? Объяснение среды выполнения JavaScript
Масштабируемость, задержка и пропускная способность — ключевые показатели производительности веб-серверов.Поддерживать низкую задержку и высокую пропускную способность при увеличении и уменьшении масштабов непросто. Node.js — это среда выполнения JavaScript, которая обеспечивает низкую задержку и высокую пропускную способность за счет «неблокирующего» подхода к обслуживанию запросов. Другими словами, Node.js не тратит время и ресурсы на ожидание возврата запросов ввода-вывода.
При традиционном подходе к созданию веб-серверов для каждого входящего запроса или соединения сервер порождает новый поток выполнения или даже разветвляет новый процесс для обработки запроса и отправки ответа.Концептуально это имеет смысл, но на практике влечет за собой большие накладные расходы.
Хотя порождение потоков требует меньше ресурсов памяти и ЦП, чем разветвление процессов , оно все же может быть неэффективным. Наличие большого количества потоков может привести к тому, что сильно загруженная система будет тратить драгоценные циклы на планирование потоков и переключение контекста, что увеличивает задержку и накладывает ограничения на масштабируемость и пропускную способность.
Node.js использует другой подход.Он запускает однопоточный цикл обработки событий, зарегистрированный в системе, для обработки соединений, и каждое новое соединение вызывает срабатывание функции обратного вызова JavaScript . Функция обратного вызова может обрабатывать запросы с неблокирующими вызовами ввода-вывода и, при необходимости, может порождать потоки из пула для выполнения блокирующих или ресурсоемких операций, а также для балансировки нагрузки между ядрами ЦП. Подход Node к масштабированию с помощью функций обратного вызова требует меньше памяти для обработки большего количества подключений, чем большинство конкурирующих архитектур, масштабируемых с помощью потоков, включая Apache HTTP Server, различные серверы приложений Java, IIS и ASP.NET и Ruby on Rails.
Node.js оказывается весьма полезным не только для серверов, но и для настольных приложений. Также обратите внимание, что приложения Node не ограничиваются чистым JavaScript. Вы можете использовать любой язык, который транслируется в JavaScript, например TypeScript и CoffeeScript. Node.js включает движок Google Chrome V8 JavaScript, который поддерживает синтаксис ECMAScript 2015 (ES6) без необходимости использования транспилятора ES6 в ES5, такого как Babel.
Большая часть утилит Node происходит из его большой библиотеки пакетов, доступ к которой можно получить с помощью команды npm .NPM, менеджер пакетов Node, является частью стандартной установки Node.js, хотя у него есть собственный веб-сайт.
Немного истории JavaScript
В 1995 году Брендан Эйх, в то время подрядчик Netscape, создал язык JavaScript для работы в веб-браузерах — как гласит история, за 10 дней. Первоначально JavaScript был предназначен для включения анимации и других манипуляций с объектной моделью документа браузера (DOM). Вскоре после этого была представлена версия JavaScript для Netscape Enterprise Server.
Название JavaScript было выбрано в маркетинговых целях, так как в то время язык Java Sun был широко разрекламирован. Фактически, язык JavaScript был основан в основном на языках Scheme и Self с поверхностной семантикой, подобной Java.
Первоначально многие программисты считали JavaScript бесполезным для «реальной работы», потому что его интерпретатор работал на порядок медленнее, чем компилируемые языки. Ситуация изменилась, когда несколько исследований, направленных на ускорение JavaScript, начали приносить плоды.Наиболее заметно то, что движок JavaScript Google Chrome V8 с открытым исходным кодом, который выполняет своевременную компиляцию, встраивание и динамическую оптимизацию кода, может фактически превзойти код C ++ для некоторых нагрузок и превзойти Python для большинства случаев использования.
Платформа Node.js на основе JavaScript была представлена в 2009 году Райаном Далем для Linux и MacOS в качестве более масштабируемой альтернативы HTTP-серверу Apache. NPM, написанный Исааком Шлютером, запущен в 2010 году. Нативная версия Node.js для Windows дебютировала в 2011 году.
Joyent владел, управлял и поддерживал разработку Node.js в течение многих лет. В 2015 году проект Node.js был передан Фонду Node.js и стал управляться техническим руководящим комитетом фонда. Node.js также был принят как совместный проект Linux Foundation. В 2019 году Node.js Foundation и JS Foundation объединились и образовали OpenJS Foundation.
Базовая архитектура Node.js
На высоком уровне Node.js сочетает в себе механизм Google V8 JavaScript, однопоточный неблокирующий цикл событий и низкоуровневый API ввода-вывода.Урезанный пример кода, показанный ниже, иллюстрирует базовый шаблон HTTP-сервера с использованием стрелочных функций ES6 (анонимные лямбда-функции, объявленные с использованием оператора жирной стрелки, => ) для обратных вызовов.
В начале кода загружается HTTP-модуль, для переменной hostname устанавливается значение localhost (127.0.0.1), а для переменной port устанавливается значение 3000. Затем создается сервер и обратный вызов функция, в данном случае функция жирной стрелки, которая всегда возвращает один и тот же ответ на любой запрос: statusCode 200 (успех), обычный текст типа содержимого и текстовый ответ «Hello World \ n» .Наконец, он сообщает серверу прослушивать localhost порт 3000 (через сокет) и определяет обратный вызов для печати сообщения журнала на консоли, когда сервер начал прослушивание. Если вы запустите этот код в терминале или консоли с помощью команды node , а затем перейдете к localhost: 3000 с помощью любого веб-браузера на том же компьютере, вы увидите «Hello World» в своем браузере. Чтобы остановить сервер, нажмите Control-C в окне терминала.
Обратите внимание, что каждый вызов, сделанный в этом примере, является асинхронным и неблокирующим.Функции обратного вызова вызываются в ответ на события. Обратный вызов createServer обрабатывает событие запроса клиента и возвращает ответ. Обратный вызов listen обрабатывает событие прослушивания .
Библиотека Node.js
Как вы можете видеть в левой части рисунка ниже, Node.js имеет большой набор функций в своей библиотеке. Модуль HTTP, который мы использовали в примере кода ранее, содержит классы клиента и сервера, как вы можете видеть в правой части рисунка.Функциональность сервера HTTPS с использованием TLS или SSL находится в отдельном модуле.
IDGОдной из проблем, присущих однопотоковому циклу событий, является отсутствие вертикального масштабирования, поскольку поток цикла событий будет использовать только одно ядро ЦП. Между тем современные микросхемы ЦП часто имеют восемь и более ядер, а современные серверные стойки часто имеют несколько микросхем ЦП. Однопоточное приложение не сможет использовать все преимущества более чем 24 ядер в надежной серверной стойке.
Это можно исправить, хотя для этого потребуется дополнительное программирование.Начнем с того, что Node.js может порождать дочерние процессы и поддерживать каналы между родителем и потомками, аналогично тому, как работает системный вызов popen (3) , используя child_process.spawn () и связанные методы.
Модуль кластера даже более интересен, чем модуль дочернего процесса для создания масштабируемых серверов. Метод cluster.fork () порождает рабочие процессы, которые совместно используют порты родительского сервера, используя child_process.spawn () под крышками.Мастер кластера распределяет входящие соединения между своими работниками, используя по умолчанию алгоритм циклического перебора, который чувствителен к нагрузкам рабочих процессов.
Обратите внимание, что Node.js не поддерживает логику маршрутизации. Если вы хотите поддерживать состояние между подключениями в кластере, вам нужно будет хранить объекты сеанса и входа в систему где-нибудь, кроме рабочей памяти.
Экосистема пакетов Node.js
Реестр NPM содержит более 1,2 миллиона пакетов бесплатного многоразового кода Node.js, что делает его крупнейшим реестром программного обеспечения в мире.Обратите внимание, что большинство пакетов NPM (по сути, папки или элементы реестра NPM, содержащие программу, описываемую файлом package.json) содержат несколько модулей (программы, которые вы загружаете с помощью , требуют операторов ). Эти два термина легко спутать, но в этом контексте они имеют особое значение и не должны взаимозаменяться.
NPM может управлять пакетами, которые являются локальными зависимостями конкретного проекта, а также глобально установленными инструментами JavaScript. При использовании в качестве диспетчера зависимостей для локального проекта NPM может установить в одной команде все зависимости проекта через пакет.json файл. При использовании для глобальных установок NPM часто требуются системные (sudo) привилегии.
У вас нет , у вас нет для использования командной строки NPM для доступа к общедоступному реестру NPM. Другие менеджеры пакетов, такие как Yarn от Facebook, предлагают альтернативные возможности на стороне клиента. Вы также можете искать и просматривать пакеты с помощью веб-сайта NPM.
Почему вы хотите использовать пакет NPM? Во многих случаях установка пакета через командную строку NPM — самый быстрый и удобный способ получить последнюю стабильную версию модуля, работающего в вашей среде, и обычно требует меньше усилий, чем клонирование исходного репозитория и сборка установки из репозитория.Если вам не нужна последняя версия, вы можете указать номер версии для NPM, что особенно полезно, когда один пакет зависит от другого пакета и может выйти из строя из-за новой версии зависимости.
Например, платформа Express, минимальная и гибкая среда веб-приложений Node.js, предоставляет надежный набор функций для создания одно-, многостраничных и гибридных веб-приложений. Репозиторий Expresscode, который можно легко клонировать, находится по адресу https://github.com/expressjs/express, а документация по Express находится по адресу https: // expressjs.com /, быстрый способ начать использовать Express — установить его в уже инициализированный локальный рабочий каталог разработки с помощью команды npm , например:
$ npm install express —save
The —save option, который фактически включен по умолчанию в NPM 5.0 и более поздних версиях, сообщает диспетчеру пакетов добавить модуль Express в список зависимостей в файле package.json после установки.
Еще один быстрый способ начать использовать Express — это установить исполняемый генератор express (1) глобально, а затем использовать его для создания приложения локально в новой рабочей папке:
$ npm install -g express-generator @ 4
$ express / tmp / foo && cd / tmp / foo
После этого вы можете использовать NPM для установки всех необходимых зависимостей и запуска сервера в зависимости от содержимого пакета.json, созданный генератором:
$ npm install
$ npm start
Трудно выделить основные моменты из миллиона с лишним пакетов в NPM, но несколько категорий выделяются. Express — самый старый и самый яркий пример фреймворков Node.js. Еще одна большая категория в репозитории NPM — это служебные программы разработки JavaScript, в том числе browserify, сборщик модулей; bower, менеджер пакетов браузера; grunt, средство выполнения задач JavaScript; и gulp, система потоковой сборки.Наконец, важной категорией для корпоративных разработчиков Node.js являются клиенты баз данных, которых более 8000, включая популярные модули, такие как redis, mongoose, firebase и pg, клиент PostgreSQL.
Подводя итог, Node.js — это кроссплатформенная среда выполнения JavaScript для серверов и приложений. Он построен на однопоточном неблокирующем цикле событий, движке Google Chrome V8 JavaScript и низкоуровневом API ввода-вывода. Различные методы, включая кластерный модуль, позволяют Node.js для масштабирования за пределы одного ядра процессора. Помимо своей основной функциональности, Node.js вдохновил экосистему из более чем миллиона пакетов, которые зарегистрированы и имеют версии в репозитории NPM и могут быть установлены с помощью командной строки NPM или альтернативы, такой как Yarn.
Copyright © 2020 IDG Communications, Inc.
Инструменты, методы и советы по созданию высокопроизводительных серверов Node.js — Smashing Magazine
Node — очень универсальная платформа, но одним из основных приложений является создание сетевых процессов.В этой статье мы сосредоточимся на профилировании наиболее распространенного из них: веб-серверов HTTP.
Если вы достаточно долго создавали что-либо с помощью Node.js, то вы, несомненно, испытали неприятные ощущения от неожиданных проблем со скоростью. JavaScript — это ровный асинхронный язык. Это может усложнить рассуждение о производительности , как станет очевидно. Растущая популярность Node.js выявила потребность в инструментах, методах и мышлении, подходящих для ограничений серверного JavaScript.
Что касается производительности, то то, что работает в браузере, не обязательно подходит для Node.js. Итак, как мы можем убедиться, что реализация Node.js работает быстро и соответствует своему назначению? Давайте рассмотрим практический пример.
Инструменты
Узел — очень универсальная платформа, но одним из основных приложений является создание сетевых процессов. Мы собираемся сосредоточиться на профилировании наиболее распространенного из них: веб-серверов HTTP.
Нам понадобится инструмент, который может взорвать сервер большим количеством запросов, одновременно измеряя производительность.Например, мы можем использовать AutoCannon:
npm install -g autocannon
Другие хорошие инструменты для тестирования HTTP включают Apache Bench (ab) и wrk2, но AutoCannon написан на Node, обеспечивает аналогичное (а иногда и большее) давление нагрузки и очень легко устанавливается в Windows, Linux и Mac OS X.
После того, как мы установили базовое измерение производительности, если мы решим, что наш процесс может быть быстрее, нам понадобится какой-то способ диагностики проблем с процессом. Отличным инструментом для диагностики различных проблем с производительностью является Node Clinic, который также можно установить с помощью npm:
npm install -g clinic
Фактически устанавливает набор инструментов.По ходу работы мы будем использовать Clinic Doctor и Clinic Flame (оболочка вокруг 0x).
Примечание : Для этого практического примера нам понадобится Node 8.11.2 или выше.
Код
Наш пример — простой сервер REST с единственным ресурсом: большая полезная нагрузка JSON, представленная как маршрут GET по адресу / seed / v1 . Сервер представляет собой папку app , которая состоит из файла package.json (в зависимости от restify 7.1.0 ), индекса .js и util.js .
Файл index.js для нашего сервера выглядит так:
'use strict'
const restify = require ('restify')
const {etagger, timestamp, fetchContent} = require ('./ util') ()
const server = restify.createServer ()
server.use (etagger (). bind (сервер))
server.get ('/ seed / v1', function (req, res, next) {
fetchContent (req.url, (err, content) => {
если (ошибка) вернуться дальше (ошибка)
res.send ({данные: контент, url: req.url, ts: timestamp ()})
следующий()
})
})
сервер.слушать (3000)
Этот сервер является типичным примером обслуживания динамического содержимого, кэшируемого клиентом. Это достигается с помощью промежуточного программного обеспечения etagger , которое вычисляет заголовок ETag для последнего состояния контента.
Файл util.js предоставляет элементы реализации, которые обычно используются в таком сценарии, функцию для получения соответствующего контента из серверной части, промежуточное ПО etag и функцию отметок времени, которая предоставляет отметки времени поминутно база:
'строгое использование'
require ('события').defaultMaxListeners = Бесконечность
const crypto = require ('крипто')
module.exports = () => {
const content = crypto.rng (5000) .toString ('шестнадцатеричный')
const ONE_MINUTE = 60000
var last = Date.now ()
функция timestamp () {
var now = Date.now ()
если (сейчас - последний> = ONE_MINUTE) последний = сейчас
вернуться последним
}
function etagger () {
var cache = {}
var afterEventAttached = false
function attachAfterEvent (server) {
если (attachAfterEvent === true) возврат
afterEventAttached = true
сервер.on ('after', (req, res) => {
если (res.statusCode! == 200) вернуть
если (! res._body) вернуть
константный ключ = crypto.createHash ('sha512')
.update (req.url)
.digest ()
.toString ('шестнадцатеричный')
const etag = crypto.createHash ('sha512')
.update (JSON.stringify (res._body))
.digest ()
.toString ('шестнадцатеричный')
if (cache [ключ]! == etag) cache [key] = etag
})
}
return function (req, res, next) {
attachAfterEvent (это)
константный ключ = крипто.createHash ('sha512')
.update (req.url)
.digest ()
.toString ('шестнадцатеричный')
if (ключ в кеше) res.set ('Etag', cache [ключ])
res.set ('Cache-Control', 'public, max-age = 120')
следующий()
}
}
функция fetchContent (url, cb) {
setImmediate (() => {
if (url! == '/ seed / v1') cb (Object.assign (Error ('Not Found'), {statusCode: 404}))
иначе cb (нуль, содержимое)
})
}
return {timestamp, etagger, fetchContent}
}
Ни в коем случае не воспринимайте этот код как пример передового опыта! В этом файле есть несколько запахов кода, но мы найдем их в процессе измерения и профилирования приложения.
Чтобы получить полный исходный код для нашей отправной точки, медленный сервер можно найти здесь.
Профилирование
Для профилирования нам понадобятся два терминала: один для запуска приложения, а другой — для его нагрузочного тестирования.
В одном терминале, в приложении , мы можем запустить папку:
node index.js
В другом терминале мы можем профилировать его так:
autocannon -c100 localhost: 3000 / seed / v1
Это откроет 100 одновременных подключений и засыпает сервер запросами в течение десяти секунд.
Результаты должны быть примерно такими (Запуск 10s test @ http: // localhost: 3000 / seed / v1 — 100 подключений):
| Stat | Avg | Stdev | Max | |
|---|---|---|---|---|
| Задержка (мс) | 3086,81 | 1725,2 | 5554 | |
| Треб / сек | 23,1 | 19,18 | 65 | |
| 197,7 кБ | 688,13 кБ |
Результаты могут отличаться в зависимости от машины. Однако, учитывая, что сервер Node.js «Hello World» легко способен обрабатывать тридцать тысяч запросов в секунду на той машине, которая дала такие результаты, 23 запроса в секунду со средней задержкой более 3 секунд — это мрачно.
Диагностика
Обнаружение проблемной области
Мы можем диагностировать приложение с помощью одной команды благодаря команде Clinic Doctor –on-port.В папке app мы запускаем:
Clinical doctor --on-port = ’autocannon -c100 localhost: $ PORT / seed / v1’ - node index.js
Это создаст HTML-файл, который автоматически откроется в нашем браузере после завершения профилирования.
Результаты должны выглядеть примерно так:
Результаты врача клиникиДоктор сообщает нам, что у нас, вероятно, возникла проблема с петлей событий.
Наряду с сообщением в верхней части пользовательского интерфейса мы также можем видеть, что диаграмма цикла событий имеет красный цвет и показывает постоянно увеличивающуюся задержку.Прежде чем мы углубимся в то, что это означает, давайте сначала разберемся, как диагностированная проблема влияет на другие показатели.
Мы видим, что ЦП постоянно находится на уровне 100% или выше, поскольку процесс усердно работает для обработки запросов в очереди. Механизм JavaScript узла (V8) фактически использует два ядра ЦП в этом случае, потому что машина многоядерная, а V8 использует два потока. Один для цикла событий, а другой — для сборки мусора. Когда мы видим, что в некоторых случаях загрузка ЦП увеличивается до 120%, это означает, что процесс собирает объекты, связанные с обработанными запросами.
Мы видим, что это коррелирует на графике памяти. Сплошная линия на диаграмме «Память» — это показатель «Используемая куча». Каждый раз, когда происходит скачок загрузки ЦП, мы видим, что в строке Heap Used падает, показывая, что память освобождается.
На Активные дескрипторы не влияет задержка цикла событий. Активный дескриптор — это объект, который представляет либо ввод-вывод (например, дескриптор сокета или файла), либо таймер (например, setInterval ). Мы проинструктировали AutoCannon открыть 100 соединений ( -c100 ).Активных дескрипторов остается постоянное количество 103. Остальные три — дескрипторы для STDOUT, STDERR и дескриптор для самого сервера.
Если щелкнуть панель «Рекомендации» в нижней части экрана, мы должны увидеть что-то вроде следующего:
Просмотр рекомендаций по конкретной проблемеКраткосрочное смягчение последствий
Анализ основных причин серьезных проблем с производительностью может занять время. В случае реального развертывания проекта стоит добавить защиту от перегрузки для серверов или служб.Идея защиты от перегрузки состоит в том, чтобы отслеживать задержку цикла событий (среди прочего) и отвечать сообщением «503 Service Unavailable», если пороговое значение превышено. Это позволяет балансировщику нагрузки переключаться на другие экземпляры или, в худшем случае, означает, что пользователям придется обновляться. Модуль защиты от перегрузки может обеспечить это с минимальными накладными расходами для Express, Koa и Restify. Фреймворк Hapi имеет параметр конфигурации загрузки, который обеспечивает такую же защиту.
Понимание проблемной области
Как поясняется в кратком объяснении в Clinic Doctor, если цикл событий задерживается до уровня, который мы наблюдаем, очень вероятно, что одна или несколько функций «блокируют» цикл событий.
Для Node.js особенно важно распознавать эту основную характеристику JavaScript: асинхронные события не могут происходить до тех пор, пока не будет завершен текущий исполняемый код.
Вот почему setTimeout не может быть точным.
Например, попробуйте запустить следующее в DevTools браузера или в Node REPL:
console.time ('timeout')
setTimeout (console.timeEnd, 100, 'таймаут')
пусть n = 1e7
в то время как (n--) Math.random ()
В результате измерения времени никогда не будет 100 мс.Вероятно, это будет в диапазоне от 150 мс до 250 мс. setTimeout запланировал асинхронную операцию ( console.timeEnd ), но текущий исполняемый код еще не завершен; есть еще две строчки. Текущий исполняемый код известен как текущий «тик». Для выполнения тика необходимо вызвать Math.random десять миллионов раз. Если это занимает 100 мс, то общее время до разрешения тайм-аута будет 200 мс (плюс сколько времени требуется функции setTimeout , чтобы фактически поставить в очередь тайм-аут заранее, обычно это пара миллисекунд).
В контексте сервера, если операция в текущем тике занимает много времени для завершения, запросы не могут быть обработаны, и выборка данных не может произойти, потому что асинхронный код не будет выполняться, пока не завершится текущий тик. Это означает, что дорогостоящий в вычислительном отношении код замедлит все взаимодействия с сервером. Поэтому рекомендуется разделить ресурсоемкую работу на отдельные процессы и вызывать их с главного сервера, это позволит избежать случаев, когда редко используемый, но дорогостоящий маршрут снижает производительность других часто используемых, но недорогих маршрутов.
В примере сервера есть код, который блокирует цикл событий, поэтому следующим шагом будет поиск этого кода.
Анализируем
Один из способов быстро определить плохо работающий код — создать и проанализировать график пламени. График пламени представляет вызовы функций как блоки, расположенные друг над другом — не во времени, а в совокупности. Причина, по которой он называется «графиком пламени», заключается в том, что он обычно использует цветовую схему от оранжевого до красного, где чем краснее блок, тем «горячее» функция, то есть с большей вероятностью он блокирует цикл событий.Захват данных для графика пламени осуществляется путем выборки процессора — это означает, что снимается моментальный снимок функции, которая выполняется в данный момент, и ее стек. Нагрев определяется процентом времени во время профилирования, в течение которого данная функция находится на вершине стека (например, функция, выполняемая в данный момент) для каждого образца. Если это не последняя функция, которую когда-либо вызывали в этом стеке, то, вероятно, она блокирует цикл обработки событий.
Давайте воспользуемся clinic flame для создания графа пламени для примера приложения:
clinic flame --on-port = ’autocannon -c100 localhost: $ PORT / seed / v1’ - индекс узла.js
Результат должен открыться в нашем браузере с примерно следующим:
Визуализация графика пламени Clinic Ширина блока показывает, сколько времени он потратил на CPU в целом. Три основных стека занимают больше всего времени, и все они выделяют сервер на как самую горячую функцию. По правде говоря, все три стека одинаковы. Они расходятся, потому что во время профилирования оптимизированные и неоптимизированные функции рассматриваются как отдельные кадры вызовов. Функции с префиксом * оптимизированы механизмом JavaScript, а функции с префиксом ~ не оптимизированы.Если оптимизированное состояние для нас не важно, мы можем еще больше упростить график, нажав кнопку «Объединить». Это должно привести к виду, подобному следующему:
С самого начала мы можем сделать вывод, что проблемный код находится в файле util.js кода приложения.
Медленная функция также является обработчиком событий: функции, ведущие к функции, являются частью модуля событий ядра , а сервер . на — резервное имя для анонимной функции, предоставляемой как функция обработки событий.Мы также можем видеть, что этот код не находится в том же тике, что и код, который фактически обрабатывает запрос. Если бы это было так, функции из модулей core http , net и stream были бы в стеке.
Такие основные функции можно найти, развернув другие, гораздо меньшие, части графика пламени. Например, попробуйте использовать поисковый ввод в правом верхнем углу пользовательского интерфейса для поиска send (имя внутренних методов restify и http ).Он должен быть справа от графика (функции отсортированы в алфавитном порядке):
Обратите внимание, насколько все сравнительно малы фактические блоки обработки HTTP.
Мы можем щелкнуть один из блоков, выделенных голубым цветом, который развернется, чтобы отобразить такие функции, как writeHead и write в файле http_outgoing.js (часть библиотеки Node core http ):
Мы можем щелкнуть все стеки , чтобы вернуться в главное представление.
Ключевым моментом здесь является то, что даже несмотря на то, что функция server.on не находится в том же тике, что и фактический код обработки запроса, она по-прежнему влияет на общую производительность сервера, задерживая выполнение кода, работающего в других отношениях.
Отладка
Мы знаем из графика пламени, что проблемной функцией является обработчик событий, переданный на сервер на в файле util.js .
Давайте посмотрим:
сервер.on ('after', (req, res) => {
если (res.statusCode! == 200) вернуть
если (! res._body) вернуть
константный ключ = crypto.createHash ('sha512')
.update (req.url)
.digest ()
.toString ('шестнадцатеричный')
const etag = crypto.createHash ('sha512')
.update (JSON.stringify (res._body))
.digest ()
.toString ('шестнадцатеричный')
if (cache [ключ]! == etag) cache [key] = etag
})
Хорошо известно, что криптография, как и сериализация ( JSON.stringify ), как правило, дорого обходится, но почему они не отображаются на графике пламени? Эти операции есть в захваченных примерах, но они скрыты за фильтром cpp .Если мы нажмем кнопку cpp , мы должны увидеть что-то вроде следующего:
Внутренние инструкции V8, относящиеся как к сериализации, так и к криптографии, теперь показаны как самые горячие стеки и занимают большую часть времени. Метод JSON.stringify напрямую вызывает код C ++; вот почему мы не видим функции JavaScript. В случае криптографии такие функции, как createHash и update , находятся в данных, но они либо встроены (что означает, что они исчезают в объединенном представлении), либо слишком малы для визуализации.
Как только мы начнем размышлять о коде в функции etagger , быстро станет очевидно, что он плохо спроектирован. Почему мы берем экземпляр server из контекста функции? Идет много хеширования, все ли это необходимо? Также в реализации отсутствует поддержка заголовка If-None-Match , которая могла бы снизить некоторую нагрузку в некоторых реальных сценариях, поскольку клиенты будут делать только головной запрос для определения свежести.
Давайте пока проигнорируем все эти моменты и подтвердим вывод о том, что фактическая работа, выполняемая на сервере . на , действительно является узким местом. Этого можно добиться, установив для кода server.on пустую функцию и сгенерировав новый флеймограф.
Измените функцию etagger на следующее:
function etagger () {
var cache = {}
var afterEventAttached = false
function attachAfterEvent (server) {
если (attachAfterEvent === true) возврат
afterEventAttached = true
сервер.on ('после', (req, res) => {})
}
return function (req, res, next) {
attachAfterEvent (это)
константный ключ = crypto.createHash ('sha512')
.update (req.url)
.digest ()
.toString ('шестнадцатеричный')
if (ключ в кеше) res.set ('Etag', cache [ключ])
res.set ('Cache-Control', 'public, max-age = 120')
следующий()
}
}
Функция прослушивателя событий передана серверу . на теперь не работает.
Давайте снова запустим clinic flame :
clinic flame --on-port = 'autocannon -c100 localhost: $ PORT / seed / v1' - индекс узла.js
В результате должен получиться график пламени, подобный следующему:
График пламени сервера, когда server.on — пустая функция Это выглядит лучше, и мы должны были заметить увеличение количества запросов в секунду. Но почему код, излучающий событие, такой горячий? Мы ожидаем, что на этом этапе код обработки HTTP будет занимать большую часть времени ЦП, в событии server.on ничего не выполняется.
Узкое место этого типа возникает из-за того, что функция выполняется чаще, чем должна.
Следующий подозрительный код в верхней части файла util.js может быть подсказкой:
require ('events'). DefaultMaxListeners = Infinity
Давайте удалим эту строку и начнем наш процесс с --trace-warnings flag:
node --trace-warnings index.js
Если мы профилируем с AutoCannon в другом терминале, например:
autocannon -c100 localhost: 3000 / seed / v1
Наш процесс выведет что-то подобное:
(узел: 96371) MaxListenersExceededWarning: Обнаружена возможная утечка памяти EventEmitter.11 после добавления слушателей. Используйте emitter.setMaxListeners (), чтобы увеличить лимит
в _addListener (events.js: 280: 19)
в Server.addListener (events.js: 297: 10)
at attachAfterEvent
(/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14)
на сервере.
(/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7)
по вызову
(/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9)
в следующий
(/ Пользователи / davidclements / z / nearForm / keep-node-fast / slow / node_modules / restify / lib / chain.js: 120: 9)
в Chain.run
(/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5)
на Server._runUse
(/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19)
на Server._runRoute
(/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10)
на Server._afterPre
(/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Узел сообщает нам, что к объекту server прикреплено множество событий.Это странно, потому что есть логическое значение, которое проверяет, было ли присоединено событие, а затем возвращается раньше, по существу, делая attachAfterEvent нерабочим после присоединения первого события.
Давайте посмотрим на функцию attachAfterEvent :
var afterEventAttached = false
function attachAfterEvent (server) {
если (attachAfterEvent === true) возврат
afterEventAttached = true
server.on ('после', (req, res) => {})
}
Условная проверка неверна! Он проверяет, истинно ли attachAfterEvent вместо afterEventAttached .Это означает, что новое событие присоединяется к экземпляру сервера при каждом запросе, а затем все предыдущие присоединенные события запускаются после каждого запроса. Упс!
Оптимизация
Теперь, когда мы обнаружили проблемные области, давайте посмотрим, сможем ли мы сделать сервер быстрее.
Low-Hanging Fruit
Давайте вернем сервер server.on в код слушателя (вместо пустой функции) и будем использовать правильное логическое имя в условной проверке.Наша функция etagger выглядит следующим образом:
function etagger () {
var cache = {}
var afterEventAttached = false
function attachAfterEvent (server) {
если (afterEventAttached === true) возврат
afterEventAttached = true
server.on ('after', (req, res) => {
если (res.statusCode! == 200) вернуть
если (! res._body) вернуть
константный ключ = crypto.createHash ('sha512')
.update (req.url)
.digest ()
.toString ('шестнадцатеричный')
const etag = крипто.createHash ('sha512')
.update (JSON.stringify (res._body))
.digest ()
.toString ('шестнадцатеричный')
if (cache [ключ]! == etag) cache [key] = etag
})
}
return function (req, res, next) {
attachAfterEvent (это)
константный ключ = crypto.createHash ('sha512')
.update (req.url)
.digest ()
.toString ('шестнадцатеричный')
if (ключ в кеше) res.set ('Etag', cache [ключ])
res.set ('Cache-Control', 'public, max-age = 120')
следующий()
}
}
Теперь мы снова проверяем исправление путем профилирования.Запускаем сервер в одном терминале:
node index.js
Затем профилируйте с помощью AutoCannon:
autocannon -c100 localhost: 3000 / seed / v1
Мы должны увидеть результаты где-то в диапазоне 200-кратного улучшения (Запуск теста 10s @ http: // localhost: 3000 / seed / v1 — 100 подключений):
| Stat | Avg | Stdev | Макс | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Задержка (мс) | 19.47 | 4,29 | 103 | |||||||||||||||||
| Треб / сек | 5011,11 | 506,2 | 5487 | |||||||||||||||||
| байт / сек | 902 МБ | 5,45 МБ | 902 МБ5,45 МБ | 905 10 с, 519,64 МБ на чтение
| Stat | Avg | Stdev | Max |
|---|---|---|---|
| Задержка (мс) | 0.64 | 0,86 | 17 |
| Треб / сек | 8330.91 | 757,63 | 8991 |
| Байт / сек | МБ | 84,17 МБ | 905 | 7,64 909 11s, 937,22 МБ при чтении Хотя улучшение в 1,6 раза является значительным, можно утверждать, что в зависимости от ситуации оправданы ли усилия, изменения и нарушение кода, необходимые для создания этого улучшения. Особенно по сравнению с 200-кратным улучшением исходной реализации с одним исправлением ошибки. Для достижения этого улучшения использовалась та же итерационная техника профилирования, генерации флеймграфа, анализа, отладки и оптимизации для получения окончательного оптимизированного сервера, код которого можно найти здесь. Последними изменениями для достижения 8000 запросов / с были: Эти изменения немного более сложны, немного более разрушительны для кодовой базы и оставляют промежуточное ПО Давайте посмотрим на график пламени для этих последних улучшений: График исправного пламени после всех улучшений производительности Самая горячая часть графика пламени является частью ядра узла в модуле Предотвращение проблем с производительностьюВ заключение приведу несколько предложений о способах предотвращения проблем с производительностью до их развертывания. Использование инструментов производительности в качестве неформальных контрольных точек во время разработки может отфильтровать ошибки производительности до того, как они попадут в рабочую среду.Рекомендуется сделать AutoCannon и Clinic (или их эквиваленты) частью повседневных инструментов разработки. При покупке фреймворка узнайте, какова его политика в отношении производительности. Если во фреймворке не уделяется первоочередное внимание производительности, важно проверить, соответствует ли это инфраструктурным практикам и бизнес-целям. Например, Restify явно (с момента выпуска версии 7) вложил средства в повышение производительности библиотеки. Однако, если низкая стоимость и высокая скорость являются абсолютным приоритетом, рассмотрите возможность использования Fastify, который, по оценке автора Restify, на 17% быстрее. Не упустите возможность выбора других библиотек, оказывающих большое влияние, — особенно обратите внимание на ведение журнала. По мере исправления проблем разработчики могут решить добавить дополнительный вывод журнала, чтобы помочь отладить связанные проблемы в будущем. Использование неэффективного регистратора со временем может снизить производительность, как в басне о кипящей лягушке. Регистратор pino — это самый быстрый регистратор JSON с разделителями новой строки, доступный для Node.js. Наконец, всегда помните, что цикл событий является общим ресурсом. Узел.js-сервер в конечном итоге ограничен самой медленной логикой на самом горячем пути. , одностраничные приложения, онлайн-чат и другие веб-приложения.Node.js используется как крупными, устоявшимися компаниями, так и недавно созданными стартапами.Платформа с открытым исходным кодом и полностью бесплатная, используется тысячами разработчиков по всему миру. Это дает множество преимуществ для таблицы, что во многих случаях делает ее лучшим выбором, чем другие серверные платформы, такие как Java или PHP. Эта статья поможет вам познакомиться с архитектурой Node.js. Вы также получите базовое представление о том, как все работает в веб-приложении и как сервер обрабатывает входящие запросы пользователей. Запишитесь на сертификационный курс Node.js и научитесь быстро и эффективно создавать сетевые приложения с помощью JavaScript.Ознакомьтесь с программой курса!Веб-приложения Веб-приложение, как вы, возможно, уже знаете, — это программа, которая запускается на сервере и обрабатывается клиентским браузером, используя Интернет для доступа ко всем ресурсам этого приложения. Обычно его легко разбить на три части:
Рис: Веб-приложение КлиентПользователь взаимодействует с интерфейсной частью веб-приложения.Интерфейс обычно разрабатывается с использованием таких языков, как стили HTML и CSS, наряду с широким использованием фреймворков на основе JavaScript, таких как ReactJS и Angular, которые помогают в проектировании приложений. СерверСервер отвечает за прием клиентских запросов, выполнение необходимых задач и отправку ответов клиентам. Он действует как промежуточное ПО между интерфейсом и хранимыми данными, позволяя клиенту выполнять операции с данными. Node.js, PHP и Java — самые популярные технологии, используемые для разработки и обслуживания веб-сервера. База данныхВ базе данных хранятся данные для веб-приложения. Данные могут быть созданы, обновлены и удалены по запросу клиента. MySQL и MongoDB — одни из самых популярных баз данных, используемых для хранения данных для веб-приложений. Архитектура сервера Node.jsNode.js использует архитектуру «однопотокового цикла событий» для обработки нескольких одновременных клиентов. Модель обработки Node.js основана на модели событий JavaScript вместе с механизмом обратного вызова JavaScript. Рис: Архитектура Node.js Теперь давайте разберемся с каждой частью архитектуры Node.js и рабочим процессом веб-сервера, разработанного с использованием Node.js. Части архитектуры Node.js:
Веб-сервер, разработанный с использованием Node.js, обычно имеет рабочий процесс, очень похожий на схему, показанную ниже. Давайте подробно рассмотрим этот поток операций. Рис: Рабочий процесс архитектуры Node.js
-Запрос данных -Удаление данных -Обновление данных
Один поток из пула потоков назначается одному сложному запросу. Этот поток отвечает за выполнение конкретного запроса на блокировку путем доступа к внешним ресурсам, таким как вычисления, база данных, файловая система и т. Д. После того, как задача выполнена полностью, ответ отправляется в цикл событий, который, в свою очередь, отправляет этот ответ обратно клиенту. Преимущества архитектуры Node.jsАрхитектура Node.js обладает рядом преимуществ, которые дают серверной платформе явное преимущество по сравнению с другими серверными языками:
Все эти преимущества способствуют тому, что серверы, разработанные с использованием Node.js, намного быстрее и быстрее реагируют по сравнению с серверами, разработанными с использованием других технологий разработки серверов. Full Stack Java Developer CourseThe Gateway to Master Web DevelopmentExplore курс Опережая время и мастер Node.js сегодняТеперь, когда у вас есть базовое представление о том, как работает Node.js работает, чтобы не отставать от высоких запросов клиентов, вам может быть интересно, как получить навыки, необходимые, чтобы воспользоваться его растущей популярностью. К счастью, есть несколько отличных возможностей для изучения этого увлекательного практического навыка в удобном для вас темпе. Сертификационный тренинг Node.js от Simplilearn даст вам отличную основу для этой популярной платформы, сочетая в себе живое обучение под руководством инструктора, самоучители и практические проекты, которые помогут вам стать готовыми к карьере по завершении.Начни сегодня и захвати свое будущее! solid / node-solid-server: надежный сервер поверх файловой системы в NodeJS
Solid Поддерживаемые функцииИспользование командной строкиУстановитьВы можете установить и запустить сервер с помощью Node.js напрямую или используя Докер. Этот и следующие разделы описывают первый подход, второй подход см. в разделе использование Docker Раздел ниже. Для установки сначала установите Node, а затем запустите следующий $ npm install -g твердый-сервер Запуск однопользовательского сервера (новичок) Самый простой способ установить Примечание : Если будет предложено ввести ключ SSL и сертификат, следуйте приведенным ниже инструкциям. Чтобы запустить сервер, просто запустите $ солидный старт # Твердый сервер (solid v0.2.24), работающий на https: // localhost: 8443/ Если вместо этого вы предпочитаете использовать флаги, следующий код будет эквивалентом $ solid start --port 8443 --ssl-key путь / к / ssl-key.pem --ssl-cert путь / к / ssl-cert.pem # Твердый сервер (solid v0.2.24), работающий на https: // localhost: 8443/ Если вы хотите запустить $ solid start --root путь / к / папке --port 8443 --ssl-key path / to / ssl-key.pem --ssl-cert path / to / ssl-cert.pem # Твердый сервер (solid v0.2.24), работающий на https: // localhost: 8443/ Запуск в средах разработки Solid требует, чтобы сертификаты SSL были действительными, поэтому вы не можете использовать самозаверяющие сертификаты. Чтобы отключить эту функцию безопасности в средах разработки, вы можете использовать исполняемый файл Если вы хотите работать в многопользовательском режиме на локальном хосте, сделайте следующее:
Как получить SSL-ключ и сертификат?Вам понадобится сертификат SSL от центра сертификации , например, от вашего поставщика домена или Let’s Encrypt !. В целях тестирования можно использовать Обратите внимание, что в этом примере создаются файлы Если вы хотите избавиться от предупреждений браузера, импортируйте свой сертификат fullchain.pem в хранилище «Доверенный корневой сертификат». Работает Solid за обратным прокси (например, NGINX)См. Запуск Solid за обратным прокси. Запуск многопользовательского сервера (промежуточный) Вы можете запустить Пререквизиты:
$ сплошной инициализации .. ? Разрешить пользователям регистрировать свой WebID (да / нет) # напишите здесь `y` .. твердый старт В противном случае, если вы хотите использовать флаги, это будет эквивалент $ solid start --multiuser --port 8443 --ssl-cert / path / to / cert --ssl-key / path / to / key --root ./data У ваших пользователей будет выделенная папка под Как я могу отправлять электронные письма своим пользователям с помощью Gmail?
так же добавить в Обновление с версии<5.3Пожалуйста, примите во внимание примечания к обновлению v5.3. Обновление с версии<5.0Для обновления версии 4 до текущей версии 5 необходимо запустить сценарий миграции, как описано в разделе v5.0 примечания к обновлению. Также имейте в виду, что, начиная с версии 5, сторонние приложения по умолчанию не являются доверенными. Чтобы доверять стороннему приложению, прежде чем вы сможете войти в него, вам сначала нужно перейти в свой профиль по адресу https://example.com/profile/card#me (важно включить туда ‘#me’), а затем наведите указатель мыши на заголовок «карточки», чтобы открыть контекстное меню. Оттуда выберите символ «A», чтобы перейти на панель доверенных приложений, где вы можете занести сторонние приложения в белый список перед их использованием. См. Также https: // github.com / solid / node-solid-server / issues / 1142 об оптимизации этого UX-потока. Дополнительные флаги (эксперт)Инструмент командной строки имеет следующие параметры Вместо использования флагов эти же параметры можно также настроить с помощью переменных среды в виде CLI имеют приоритет над переменными среды, которые имеют приоритет над записями в файле конфигурации. Настройка Solid через файл конфигурации может быть кратким и удобным методом и обычно рекомендуется. Флаги CLI могут быть полезны, когда вы хотите переопределить один параметр конфигурации, а использование переменных среды может быть полезно в ситуациях, когда вы хотите развернуть один общий образ Docker в нескольких средах. Используйте DockerИспользование в производствеСм. Документацию по запуску Solid с помощью docker и docker-compose. У нас настроены автоматические сборки, поэтому фиксация в мастере вызовет сборку https://hub.docker.com/r/nodesolidserver/node-solid-server. Использование при разработкеЕсли вы хотите использовать Docker в разработке, вы можете собрать его локально с помощью: git clone https://github.com/solid/node-solid-server компакт-диск node-solid-server docker build -t узел-твердый-сервер. Запуск с: docker run -p 8443: 8443 --name solid-node-solid-server Это позволит вам войти в систему на https: // localhost: 8443, а затем создать новую учетную запись. но еще не использовать эту учетную запись. После создания новой учетной записи вам необходимо будет создать запись для это в вашем локальном (/ etc /) файле hosts в соответствии с учетной записью и поддоменом, то есть — Вы можете изменить конфигурацию в контейнере докера следующим образом:
Использование библиотекиУстановить зависимости Использование библиотекиБиблиотека предоставляет два API:
В случае, если {
cache: 0, // Устанавливаем время кеширования (в секундах), 0 без кеша
live: true, // Включить поддержку в реальном времени через WebSockets
root: './', // Корневая папка в файловой системе для обслуживания ресурсов
secret: 'node-ldp', // секретный ключ экспресс-сессии
cert: false, // Путь к ssl-сертификату
key: false, // Путь к ssl-ключу
mount: '/', // Куда смонтировать платформу связанных данных
webid: false, // Включить аутентификацию WebID + TLS
суффиксAcl: '.acl ', // Суффикс для файлов acl
corsProxy: false, // Куда смонтировать прокси CORS
errorHandler: false, // функция (err, req, res, next), чтобы иметь собственный обработчик ошибок
errorPages: false // указываем путь, где находятся страницы ошибок
} Взгляните на следующие примеры или в Простой пример Вы можете создать var solid = require ('твердый сервер')
var ldp = solid.createServer ({
ключ: '/path/to/sslKey.pem',
сертификат: '/path/to/sslCert.pem',
webid: true
})
ldp.listen (3000, function () {
// Запущена платформа связанных данных
}) Расширенный пример Вы можете интегрировать var solid = require ('твердый сервер')
var app = require ('экспресс') ()
app.use ('/ test', твердый (ваши настройки))
app.listen (3000, function () {
// Запущено приложение Express с ldp на '/ test'
})
... Лесозаготовки Запустите приложение с набором переменных $ DEBUG = "solid: *" узел app.js Тестирование твердое тело ЛокальноПредварительные требования Чтобы по-настоящему почувствовать платформу Solid и протестировать
Хотя эти шаги технически необязательны (так как вы можете запустить их в HTTP / LDP-only mode), вы не сможете использовать какие-либо реальные функции Solid без них. Создание сертификата для локального тестирования При развертывании Доступ к вашему серверу Если вы запустили свой Редактирование локального / etc / hosts Для тестирования сертификатов и создания учетных записей на поддоменах, тестовый набор Отредактируйте файл Запуск модульных тестов$ npm тест # запуск тестов с журналами $ DEBUG = "solid: *" npm test Чтобы протестировать отдельный компонент, вы можете запустить npm запустить тест- (acl | форматы | параметры | патч) Имена пользователей в черном списке По умолчанию Solid не разрешает использование определенных имен пользователей, поскольку они могут вызвать
путаница или допускать уязвимости для социальной инженерии.Этот список настраивается через Квота По умолчанию файл Получите помощь и внесите свой вкладSolid возможен только благодаря большому сообществу участников. Сердечное спасибо всем за ваши старания! Вы также можете получить или оказать помощь: Взгляните на CONTRIBUTING.md. ЛицензияЛицензия MIT .0 thoughts on “Что такое нода сервера: Что такое нода? — Bitte”Добавить комментарий |
https://forum-internetowe.yum.pl/showthread.php?tid=64135&pid=190264#pid190264
https://emeyaforum.com/showthread.php?tid=56521&pid=114174#pid114174
https://www.ewebtalk.com/showthread.php?tid=2081&pid=30232#pid30232
https://www.chuangyei.com/thread-6070-1-1.html
https://www.xn--cksr0ar36ezxo.com/forum.php?mod=viewthread&tid=118601&extra=
https://vivoes.com/forum.php?mod=viewthread&tid=45394&extra=
https://www.freebeg.com/forum/showthread.php?tid=62106
https://usaxii.com/thread-5038-1-1.html
http://qhlt.waterforex.com/forum.php?mod=viewthread&tid=2126273&extra=page%3D1
https://www.craftaid.net/showthread.php?tid=122335&pid=205665#pid205665
https://emeyaforum.com/showthread.php?tid=56505&pid=118970#pid118970
https://emeyaforum.com/showthread.php?tid=56521&pid=114174#pid114174
https://bbs.xinmengzhilv.tw/thread-61059-1-1.html
https://freebeg.com/forum/showthread.php?tid=64022&pid=75843#pid75843
https://xinruiweb.com/forum.php?mod=viewthread&tid=88
http://forum.l2endless.com/showthread.php?tid=647973&pid=1077127#pid1077127
https://emeyaforum.com/showthread.php?tid=56521&pid=119647#pid119647
https://aopvp.com/forum.php?mod=viewthread&tid=387&pid=144938&page=28&extra=#pid144938
https://mybb.microtradersbd.com/showthread.php?tid=49521&pid=65062#pid65062
https://www.freebeg.com/forum/showthread.php?tid=64027&pid=76103#pid76103
https://forum.bandariklan.com/showthread.php?tid=591318&pid=1230551#pid1230551
https://freebeg.com/forum/showthread.php?tid=64186&pid=76321#pid76321
https://emeyaforum.com/showthread.php?tid=56521&pid=119647#pid119647
https://usaxii.com/thread-4890-1-1.html
https://emeyaforum.com/showthread.php?tid=56521&pid=119647#pid119647
https://egovmetrics.com/AppForum/showthread.php?tid=26&pid=29#pid29
http://www.orlandogamers.org/forum/showthread.php?tid=14636&pid=482439#pid482439
https://sunlightbulb.com/lw/upload/forum.php?mod=viewthread&tid=113022&extra=
http://forum.l2endless.com/showthread.php?tid=630276&pid=1077416#pid1077416
https://gspanel.net/showthread.php?tid=2831&pid=6304#pid6304
https://emeyaforum.com/showthread.php?tid=56521&pid=119647#pid119647
http://forum.l2endless.com/showthread.php?tid=631156&pid=1077787#pid1077787
http://orlandogamers.org/forum/showthread.php?tid=2320&pid=487043#pid487043
https://craftaid.net/showthread.php?tid=122435&pid=205550#pid205550
https://usaxii.com/thread-4819-1-1.html
https://freebeg.com/forum/showthread.php?tid=64186&pid=76321#pid76321
https://www.bullochtaxes.com/forum/viewtopic.php?t=102149
https://horwoodcarpetcleaning.com/x/cdn/?https://wappblaster.com/index.php/2023/06/22/the-art-of-negotiation-tips-for-successful-business-deals/
https://egovmetrics.com/AppForum/showthread.php?tid=57&pid=60#pid60
http://orlandogamers.org/forum/showthread.php?tid=1668&pid=487102#pid487102
http://forum.l2endless.com/showthread.php?tid=631156&pid=1077787#pid1077787
https://egovmetrics.com/AppForum/showthread.php?tid=26&pid=61#pid61
http://forum.l2endless.com/showthread.php?tid=647973&pid=1077127#pid1077127
https://jcw100.com/forum.php?mod=viewthread&tid=88&pid=43541&page=1&extra=#pid43541
https://www.formulersupport.com/Thread-IG-Tchad-insights—271352
http://forum.l2endless.com/showthread.php?tid=384871&pid=1078016#pid1078016
https://hardcoredumper.com/showthread.php?tid=8699&pid=252301#pid252301
http://forum.l2endless.com/showthread.php?tid=630276&pid=1077416#pid1077416
https://sunlightbulb.com/lw/upload/forum.php?mod=viewthread&tid=111404&extra=
https://emeyaforum.com/showthread.php?tid=56521&pid=119647#pid119647
https://forum-internetowe.yum.pl/showthread.php?tid=64134&pid=189270#pid189270
https://forum.uookle.com/forum.php?mod=viewthread&tid=861&pid=4072&page=277&extra=#pid4072
https://www.usaxii.com/thread-4944-1-1.html
https://www.craftaid.net/showthread.php?tid=122335&pid=205418#pid205418
https://jcw100.com/forum.php?mod=viewthread&tid=88&pid=43543&page=2&extra=page%3D1#pid43543
http://forum.l2endless.com/showthread.php?tid=631156&pid=1054262#pid1054262
https://danceplanet.se/555.5/index.php?topic=6125.0
https://vivoes.com/forum.php?mod=viewthread&tid=8384&pid=47765&page=1&extra=#pid47765
https://wap2p.com/f/showthread.php?tid=4200
https://vivoes.com/forum.php?mod=viewthread&tid=45215&extra=
https://www.vivoes.com/forum.php?mod=viewthread&tid=20038&pid=47681&page=1&extra=#pid47681
http://forum.l2endless.com/showthread.php?tid=631156&pid=1077787#pid1077787
https://www.bullochtaxes.com/forum/viewtopic.php?t=102282
https://www.one2bay.de/forum/showthread.php?tid=24500&pid=1744334#pid1744334
http://www.orlandogamers.org/forum/showthread.php?tid=1239&pid=486867#pid486867
https://egovmetrics.com/AppForum/showthread.php?tid=26
https://sunlightbulb.com/lw/upload/forum.php?mod=viewthread&tid=3895&pid=383794&page=1&extra=page%3D1#pid383794
https://forum-internetowe.yum.pl/showthread.php?tid=64135&pid=194742#pid194742
https://rfid-china.com/forum.php?mod=viewthread&tid=108210&extra=
https://gspanel.net/showthread.php?tid=2741&pid=6305#pid6305
https://vivoes.com/forum.php?mod=viewthread&tid=2117&pid=47653&page=1&extra=#pid47653
http://dogone.cher-ish.net/ro/joyful/joyful.cgi?mode=past&pno=0535&pg=160
https://www.esfnc.com/thread-24962-1-1.html
https://jcw100.com/forum.php?mod=viewthread&tid=88&pid=48218&page=2&extra=page%3D1#pid48218
http://forum.l2endless.com/showthread.php?tid=647973&pid=1077127#pid1077127
https://sankuo.onlinehost.cc/forum.php?mod=viewthread&tid=4537&extra=
http://treasureillustrated.com/showthread.php?tid=13472&pid=25822#pid25822
https://forums.cyclone-hosting.net/showthread.php?tid=55809&pid=58244#pid58244
https://www.esfnc.com/thread-24919-1-1.html
https://iymlove.com/thread-227-1-1.html
https://www.aopvp.com/forum.php?mod=viewthread&tid=28140&pid=145065&page=2&extra=page%3D1#pid145065
http://freebeg.com/forum/printthread.php?tid=38176
http://forum.l2endless.com/showthread.php?tid=631156&pid=1077787#pid1077787
https://hkgay.net/showthread.php?tid=127893
https://www.bullochtaxes.com/forum/viewtopic.php?t=102281
https://emeyaforum.com/showthread.php?tid=56505&pid=118970#pid118970
http://forum.l2endless.com/showthread.php?tid=630276&pid=1077416#pid1077416
http://www.orlandogamers.org/forum/showthread.php?tid=1583&pid=485596#pid485596
https://www.tycii.com/thread-16341-1-1.html
https://www.craftaid.net/showthread.php?tid=122334&pid=205668#pid205668
https://aopvp.com/forum.php?mod=viewthread&tid=338&pid=145210&page=14&extra=#pid145210
http://treasureillustrated.com/showthread.php?tid=13472&pid=31172#pid31172
https://praisenpray.org/forums/showthread.php?tid=179256&pid=286670#pid286670
http://www.orlandogamers.org/forum/showthread.php?tid=1239&pid=486859#pid486859
http://www.nihongo.edu.lk/showthread.php?tid=123591&pid=227765#pid227765
https://www.flcolle.com/forum.php?mod=viewthread&tid=8229&extra=
https://www.vivoes.com/forum.php?mod=viewthread&tid=20083&pid=47475&page=1&extra=#pid47475
https://www.tvboxnow.com/viewthread.php?tid=7217777&pid=77340645&page=48&extra=
https://jcw100.com/forum.php?mod=viewthread&tid=88&pid=43534&page=1&extra=#pid43534
http://forum.l2endless.com/showthread.php?tid=631156&pid=1077787#pid1077787