Яндекс. Толока — обман или некомпетентность ? | Параноик
Началась эта стори вчера. У одного и того же заказчика выполнял задания. Вчера к слову они стоили у меня 0.7 центов. Сегодня уже обучение снова.
Ну думаю сейчас быстренько сравню и т.д.. Рука набита тем более знания по теме есть.
Но вышло всё как всегда)..
Столько несоотвествий у меня никогда небыло. Я уже снова плюнул на Толоку но тут внезапно меня задело одно задание которое не прошло оценку.
задания Я.массалиязадания Я.массалия
Вот есть два сайта. На левом, центр поддержки. Я это задание уже проходил. Левый сайт не подходит точно. Правый же сайт, мало того что там написанно в шапке что оно продаеться, а учитывая как написанно то админ имеет начальные знания в HTML и скорее всего не может поддерживать больше сам сайт.
И конечно перейдя по ссылке увидел вот что:
404404
Но у заказчика там всё нормально же, задания в минус. .
.
То есть задание даеться сразу или на котором завалят, или сами не смотрят что дают. Или те люди кто должен составлять задания сами не смотрят что дают. незнаю, но факт остаеться фактом. Человек делает задание правильно а ему говорят — нет уважаемый Вы неправы..
Было еще одно задание, где Википедия с его текстом мелким шрифтом был признам лучшим сайтом чем сайт с темой по теме, одекватным шрифтом и прочими вещами. Тут конечно я дал маху, не посмотрел сразу исходный код странички что бы были доки, но на скрине якобы на мобильной версии и так было понятно что сайт с темой по теме выглядит удобочитаемым нежеле мелкий премелкий шрифт на википедии.
И такое не первый раз. Я незнаю как там всё происходит, смотрят ли они сами и пробуют ли вчитаться. Но лично знаю по опыту что размер букв имеет значение особенно на трубке.
Даже если сайт якобы адаптирован под мобилки это не значит что он априори лучше.
Вот грубо говоря адаптация Википедии под небольшой смартфон. .
.
Левый блок с навигацией вообще там не должен быть, а это одна треть экрана !.. Но по мнению спецо с Толоки Википедия лучше..
Яндекс. Толока — обман или некомпетентность ?Ну что сказать еще о Толоке.. Я незнаю.. Радости от прохождения задания нет вообще. Заработать там можно, на телефон, когда совсем прижмет. Это конечно моё мнение личное..
| Сервис | URL | Описание | Годы работы |
|---|---|---|---|
| Локальная сеть Яндекса | [128] | Предоставляла возможность пользоваться всеми службами Яндекса не по федеральному, а по локальному тарифу | 2008 — 2016 |
| Фабрика данных Яндекса | [129] | Работа с большими файлами. Заменена на Яндекс.Облако | 2014 — 2018 |
| Яндекс.Лента | [130] | Служба чтения RSS-лент онлайн. Заменена на Яндекс.Новости | ? |
| Яндекс.Медиана | [131] | Сервис для мониторинга СМИ и сайтов | 2016 — ? |
Яндекс. Мастер Мастер | [132] | Служба вызова исполнителей мелких бытовых заданий. | 2014[29] — 2015[30] |
| Яндекс.Книга | [133] | Поиск книг, авторов. | |
| Яндекс.Виджеты | [134] | Виджеты для главной страницы Яндекса и рабочего стола Windows | ? |
| Мои находки | [135] | История индивидуальных поисковых запросов | 2007 — ? |
| Яндекс.Спамооборона | [136] | Спам-фильтр для корпоративного использования | 2005 — ? |
| Яндекс.Строка | [137] | Дополнительная панель инструментов для панели задач, позволяющая вести поиск в интернете и на компьютере. Заменена на Алису. | ? |
| Яндекс.Manul | [138] | Свободный антивирус для сайтов. | 2015 — ? |
| Яндекс.Кит | [139] | Операционная система на основе Андроид | 2014 — 2015 |
Яндекс. Shell Shell | [140] | Объёмный интерфейс для телефонов на базе «Андроид». В данный момент заменён на Яндекс.Лончер. | ? |
| Яндекс.Store | [141] | Магазин приложений «Яндекса» для смартфонов и планшетов | 2013 — 2020 |
| Антивирус | [142] | «Яндекс»-версия Антивируса Касперского | ? |
| «Дзен-Поиск» | [143] | «Медитативный поиск», не требующий введения поискового запроса | 2001 — 2015 |
| Яндекс.Диктовка | [144] | Приложение для перевода устной речи в текст[31] | 30 октября 2014—2016 |
| Яндекс.Закладки | [145] | Система хранения закладок | 22 июня 2000 — 13 апреля 2015 |
| Яндекс.Город | [146] | Служба поиска и выбора организаций с отзывами и рейтингом | 2014[32] — 2016[33] |
| Яндекс.Краски | [147] | Программа позволяла с помощью специальных инструментов в интерфейсе рисовать различные картинки | 2007 — 2013[34] |
| Мой Круг | [148] | Социальная сеть.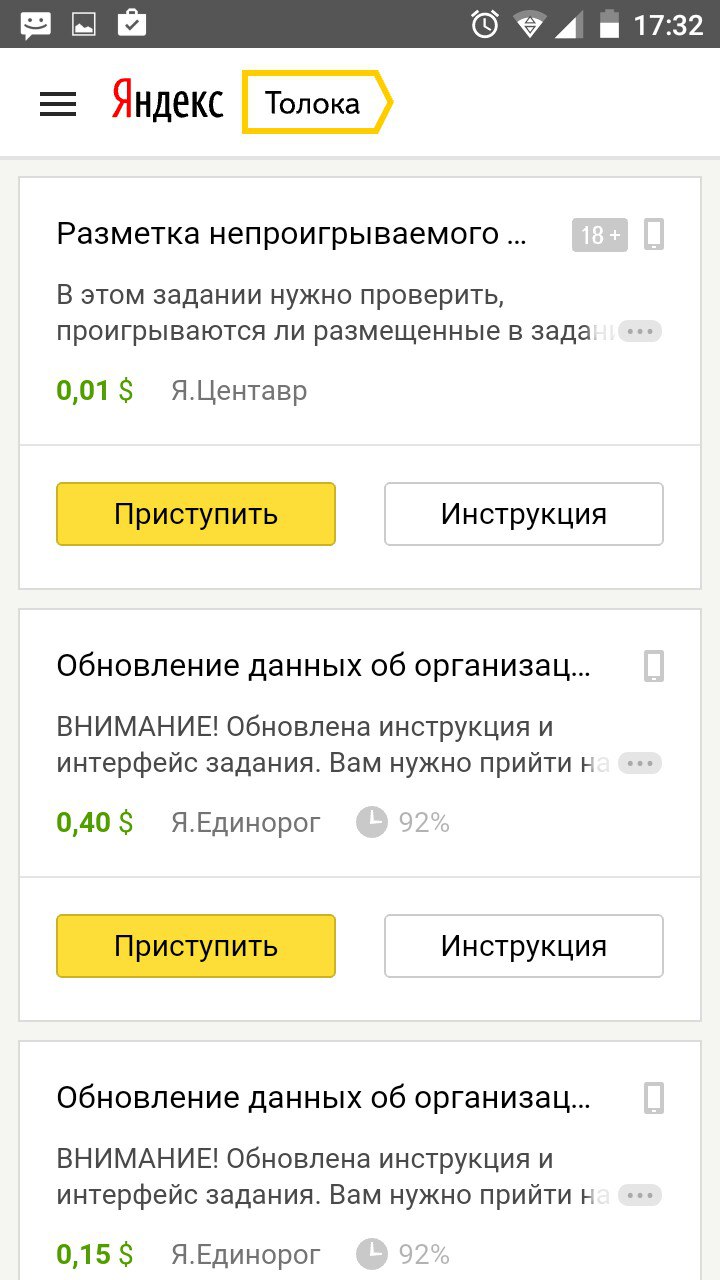 Продана компании «Тематические медиа» Продана компании «Тематические медиа» | 2007 — 2015[35] |
| Яндекс.Народ | [149] | Бесплатная служба для создания сайтов. Переехала на uCoz)[36] | 2000 — 2013 |
| Яндекс.Нано | [150] | Площадка для тестирования новых служб | 2007 — 2009 |
| Я.Онлайн | [151] | Мессенджер на основе технологии Jabber[37] | 2007 — 2013 |
| Яндекс.Ответы | [152] | Служба вопросов и ответов | 2009 — 2010 |
| Яндекс.Открытки | [153] | Служба для отправки электронных открыток | 2000[40] — 31 декабря 2013 |
| Персональный поиск Яндекса | [154] | Поиск по файлам на компьютере пользователя | 2005 — 2007 |
| Яндекс.Прогулки | ? [155] | Путеводитель по городам России в виде мобильного приложения[41] | 2015 — 2015[42] |
| Пульс блогосферы | [156] | Определял всплеск запросов к тому или иному слову или фразе | 2007—2013[43] |
Яндекс. | [157] | Сайт о пиве[44] | 2001 — 2004 |
| Яндекс.WiFi | [158] | Сеть бесплатных точек беспроводного доступа | ? |
| Я.ру | [159] | Блог-платформа | 2007 — 2014[45] |
| Яндекс.Словари | [160] | Энциклопедии, справочники, словари-переводчики | 2006 — 2016[46] |
| Яндекс.Каталог | [161] | Каталог веб-сайтов с сортировкой по индексу цитирования. Пополняется вручную редакторами каталога, имеется возможность платной регистрации | 2000 — 2018 |
| Яндекс.Фотки | [162] | Бесплатный фотохостинг. Имеет технологию распознавания лиц на фотографиях[47] | 2007 — 2018 |
| Яндекс.Толк | [163] | Сервис для профессиональных статей | 2018 — 2019[48] |
| Яндекс.Каршеринг | ? | Сервис отображал на карте города расположение автомобилей каршеринговых служб. Был закрыт в ноябре 2017 из-за невозможности ввести функцию бронирования автомобилей, так как сервисы каршеринга отказывались предоставлять необходимые данные. После был заменён на Яндекс.Драйв Был закрыт в ноябре 2017 из-за невозможности ввести функцию бронирования автомобилей, так как сервисы каршеринга отказывались предоставлять необходимые данные. После был заменён на Яндекс.Драйв | 2012 — 2017 |
| Яндекс.Игрушки | [164] [165] | Каталог игр Яндекса. Его новый аналог — games.yandex.ru | ? |
| Bringly | [166] | Платформа для трансграничной онлайн-торговли | 2018 — 2019[50] |
| Яндекс.Люди | ? | Поиск профилей в социальных сетях | 2012 — 2020[51] |
| Яндекс.Аура | [167] | Социальная сеть | 2019 — 2020[52] |
| Яндекс.Транспорт | [168] | Приложение для устройств на базе iOS и «Андроид» для отслеживания положения общественного транспорта в реальном времени. | 2014 — 2020 |
Яндекс.
 Толока — что можем почерпнуть? — Блог Андрея Отто
Толока — что можем почерпнуть? — Блог Андрея Отто Яндекс.Толока — площадка для тестировщиков, асессоров «из народа». Основная цель — оценка и анализ контента.
Некоторые задания в Яндекс.Толоке могут помочь понять принципы хороших элементов сайта.
Критерии выбора хороших картинок
Хорошо:
- картинка хорошего качества, без ненужных надписей или видоизменений,
- по запросам об известных людях — их фото, памятники,
- по запросам об известных людях — их кадры из экранизаций,
- скриншоты из игр или фильмов хорошего качества.
Плохо:
- когда картинка не соответствует запросу или соответствует, но частично,
- качество картинки неудовлетворительное,
- содержит юморные надписи (демотиваторы — плохо),
- водяные знаки мешающие просмотру,
- фотожабы,
- если картинка чем-то отталкивает, то это не лучшая картинка,
- если запрос — страна, то изображение флага не подходит,
- по запросам о людях искусства — результаты их творчества,
- обложки альбомов,
- логотипы компаний.
Средне:
- картинки, которые не подходят к вышеописанным,
- приемлемое качество,
- с небольшими дефектами,
- с небольшими надписями (сайт или имя),
- подходящие по смыслу картинки, но содержащие отталкивающие сцены (жестокость, кровь),
- детские фото известных людей,
- по запросам об известных людях — рисунки,
- постеры фильмов.

Критерии выбора хорошего авторитетного сайта
Чтобы комментировать, зарегистрируйтесь или авторизуйтесьХорошо:
- известный сайт,
- государственный сайт,
- официальный сайт организации (даже официальная страница в соцсети),
- текст написан специалистом,
- нет или мало рекламы,
- если группа, то много подписчиков,
- настоящий аккаунт известного человека,
- есть форум или живое общение в комментах,
- свежие обновления,
- визуально красивые сайты.

Плохо:
- мусорный контент,
- текст не имеющий смысла,
- реклама мошенников,
- поехала верстка,
- не видно картинок,
- файлы битые,
- опасный контент,
- вирус на сайте,
- лжемедицина,
- обман,
- много рекламы.
Если над сайтом работает 1 человек, то весь сайт (а не только отдельные страницы) или авторитетный, или нет.
В случае, если над сайтом работает много людей (ex. Википедия), то оцениваются отдельные страницы.

Пошаговый пример создания статьи в Wiki
Все накопленные данные по проекту удобно хранить в общей базе знаний (Wiki).
Как вы увидите в нашем ролике, создание целого раздела не займет больше 3 минут.
Например, создадим и наполним раздел Спецтехника в группе Аренда спецтехники.
Порядок действий:
- Переходим в группу, кликаем на пункте Wiki в меню
- На главной странице нажимаем копку Создать
- Вводим заголовок страницы и заголовки разделов
- Добавляем и форматируем тексты определений в каждый раздел.
- Задаем внутренние гиперссылки для тех понятий, для которых будут созданы отдельные соответствующие страницы
- Из получившихся красных ссылок создаем соответствующие страницы
- Указываем категорию для страницы
- Заполняем страницу нужным текстом, картинками, с помощью визуального редактора форматируем страницу по корпоративным стандартам или же по собственному вкусу
- После нажатия на кнопку Опубликовать получаем готовую страницу, где можно проверить наполнение информацией, форматирование, переходы по ссылкам и т. д.
- Нажав на ссылку Категории в конце страницы, можно проверить состав и наполненность категорий, корректность переходов по страницам
- В случае необходимости, страницы можно отредактировать (кнопка Править) или восстановить какую-либо из предыдущих версий (список версий доступен по кнопке История)
 д.
д.Как видите, создание полноценной базы знаний не требует большого труда и времени, а лишь немного внимания. А польза собственной Wiki несомненна — ведь так можно быстро ввести новичка в курс дела, сэкономить время при использовании стандартных документов и алгоритмов работы, и даже обезопасить себя от того, чтобы ваш уникальный опыт использовали конкуренты.
Советую также прочитать:
zyltrc
4.5 454 zyltrc
Яндекс.Почта — бесплатная и надежная электронная почта
Завести почту на Яндексе: надежная защита от спама и вирусов, сортировка
входящих по категориям, выделение писем от людей, бесплатно 10 ГБ на . ..
..
Яндекс.Деньги
Раздаём 5 миллионов баллов. Платите Яндекс.Деньгами и получите шанс выиграть от 50 до 4 000 баллов. 1 балл = 1 ₽. Как это работает. Я.Кард …
money.yandex.ruЯндекс
Яндекс — облегчённая версия. Поисковая строка, почтовый ящик и быстрый переход к сервисам Яндекса.
ya.ruЯндекс.Вебмастер
С помощью Вебмастера можно следить за статистикой запросов, по
которым сайт показывается в поиске. Сервис позволяет наблюдать за тем,
как …
Сервис позволяет наблюдать за тем,
как …
Яндекс — YouTube
В одном обычном городском доме появилась первая Яндекс.Станция — умная колонка с Алисой внутри. С тех пор её обладателям стало всё делать …
www.youtube.comЯндекс
Яндекс — поисковая система и интернет-портал. Поиск по интернету и другие сервисы: карты и навигатор, транспорт и такси, погода, новости, музыка, …
yandex.ruЯндекс — Википедия
«Я́ндекс» — российская транснациональная компания, зарегистрированная
в Нидерландах и владеющая одноимённой системой поиска в Сети, .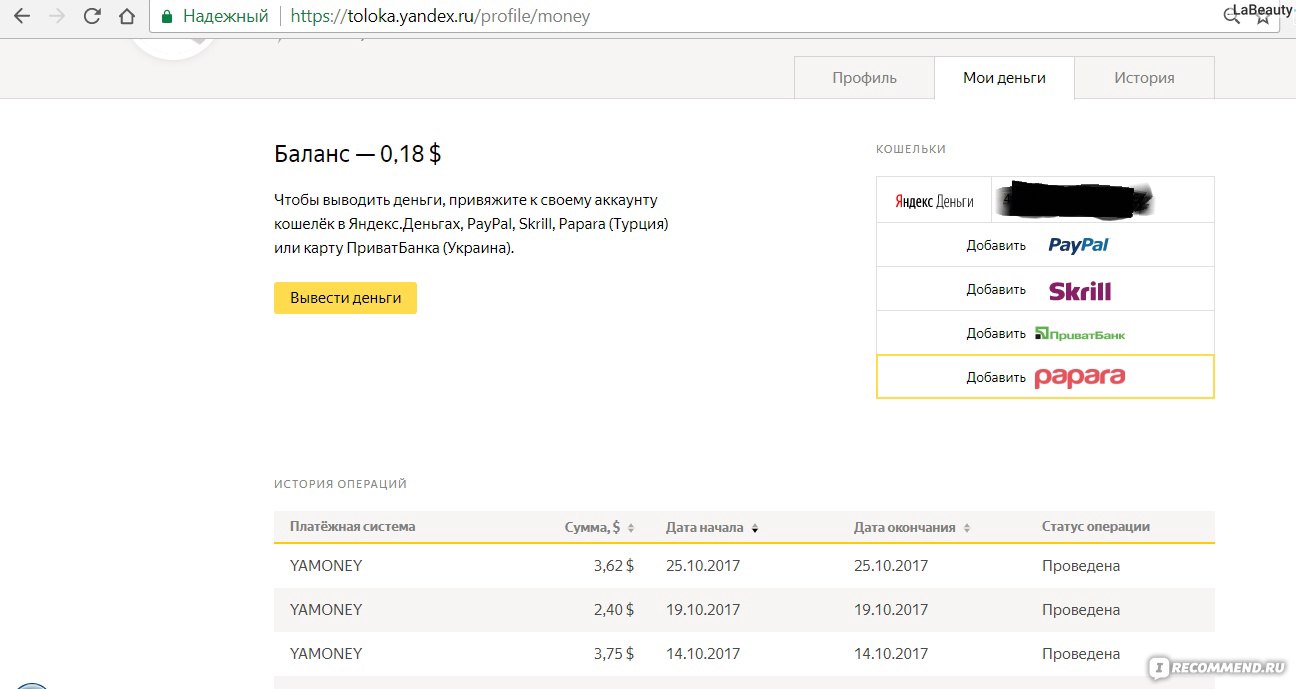 ..
..
Скачать Яндекс.Диск на компьютер, смартфон и планшет
Бесплатное приложение Яндекс.Диск надежно сохраняет и синхронизирует все ваши файлы, фотографии и документы между компьютером, …
disk.yandex.ruЯндекс.Плюс — скидки, бонусы и привилегии на сервисах Яндекса
Подписка Яндекс.Плюс даёт полный доступ к Яндекс.Музыке, скидку на поездки с Яндекс.Такси и каршерингом Яндекс.Драйв, бесплатную доставку на …
plus.yandex.ru Яндекс. Толока — заработок в интернете без вложений
Яндекс.Толока — интернет-сервис, позволяющий зарабатывать деньги в свободное время, выполняя несложные задания с компьютера или мобильного …
toloka.yandex.ruЯндекс — Википедия
«Я́ндекс» — российская транснациональная компания, зарегистрированная в Нидерландах и владеющая одноимённой системой поиска в Сети…
ru.wikipedia.orgЯндекс (@yandex) | Твиттер
Самые новые твиты от Яндекс (@yandex): «Команда Яндекс. Практикума запустила новое медиа «Код». Подписывайтесь и читайте статьи о том, как взломать жизненные проблемы с помощью…
Практикума запустила новое медиа «Код». Подписывайтесь и читайте статьи о том, как взломать жизненные проблемы с помощью…
Яндекс — Home | Facebook
Яндекс, Moscow, Russia. 118K likes. Технологии будущего и сервисы, которые делают жизнь лучше уже сегодня.
www.facebook.comЯндекс (@yandex) • Фото и видео в Instagram
58.4 тыс. подписчиков, 11 подписок, 1,418 публикаций — посмотрите в Instagram фото и видео Яндекс (@yandex).
Яндекс | ВКонтакте
Основная цель Яндекса — решать задачи людей. Любые задачи: в сети и в реальном мире, повседневные и редкие, бытовые и научные, за третий класс и за пятый курс.
vk.comЯндекс — облегченная версия поисковой системы
Поисковая строка, доступ к почте и персональным сервисам на Яндексе.
ya.ruЯндекс в Беларуси
На сайте имеется поиск информации с учетом морфологии русского и белорусского языков, есть возможность уточнения поиска по интересующему региону, выбор языка интерфейса, параллельный поиск по новостям, товарам и др. сервисам. Здесь можно узнать самые свежие…
сервисам. Здесь можно узнать самые свежие…
Яндекс | OK.RU
Группа Яндекс в Одноклассниках. Основная цель Яндекса — решать задачи людей. Любые задачи: в сети и в реальном мире, повседневные и редкие, бытовые и научные, за третий класс…
ok.ruЯндекс — YouTube
Яндекс представляет альфа-версию нового Яндекс.Браузера. Такими, по нашему мнению, будут браузеры в будущем.
www. youtube.com
youtube.comЯндекс
Яндекс — поисковая система и интернет-портал. Поиск по интернету и другие сервисы: карты и навигатор, транспорт и такси, погода, новости, музыка, телепрограмма, переводчик…
yandex.ruЗаработать в интернете яндекс толока – Telegraph
Заработать в интернете яндекс толока🔥Капитализация рынка криптовалют выросла в 8 раз за последний месяц!🔥
✅Ты думаешь на этом зарабатывают только избранные?
✅Ты ошибаешься!
✅Заходи к нам и начни зарабатывать уже сейчас!
________________
>>>ВСТУПИТЬ В НАШ ТЕЛЕГРАМ КАНАЛ<<<
________________
✅Всем нашим партнёрам мы даём полную гарантию, а именно:
✅Юридическая гарантия
✅Официально зарегистрированная компания, имеющая все необходимые лицензии для работы с ценными бумагами и криптовалютой
(лицензия ЦБ прикреплена выше).
Дорогие инвесторы‼️
Вы можете оформить и внести вклад ,приехав к нам в офис
г.Красноярск , Взлётная ул., 7, (офисный центр) офис № 17
ОГРН : 1152468048655
ИНН : 2464122732
________________
>>>ВСТУПИТЬ В НАШ ТЕЛЕГРАМ КАНАЛ<<<
________________
✅ДАЖЕ ПРИ ПАДЕНИИ КУРСА КРИПТОВАЛЮТ НАША КОМАНДА ЗАРАБАТЫВЕТ БОЛЬШИЕ ДЕНЬГИ СТАВЯ НА ПОНИЖЕНИЕ КУРСА‼️
‼️Вы часто у нас спрашивайте : «Зачем вы набираете новых инвесторов, когда вы можете вкладывать свои деньги и никому больше не платить !» Отвечаем для всех :
Мы конечно же вкладываем и свои деньги , и деньги инвесторов! Делаем это для того , что бы у нас был больше «общий банк» ! Это даёт нам гораздо больше возможностей и шансов продолжать успешно работать на рынке криптовалют!
________________
>>>ВСТУПИТЬ В НАШ ТЕЛЕГРАМ КАНАЛ<<<
________________
Разметка и сбор данных для ML и других задач
Яндекс.Толока́ — краудсорсинговый проект, созданный в году для быстрой разметки большого количества данных, которые затем используются для машинного обучения.
Как заработать денег через киви
Капитал основной оборотный и финансовый
Как заработать на Яндекс.Толока: Инструкция + личный опыт
Какие акции выпадают в тинькофф инвестиции
Когда ждать коррекцию на фондовом рынке
Работа на Яндекс толока.ТОП заданий для заработка $.Советы
Инвестиции долгосрочные вложения
Работа менеджер по закупкам удаленно
Яндекс.Толока — Википедия
Методы оценки финансовых инвестиций
Как можно зарабатывать деньги бесплатно
Алматы | Поиск
Toggle navigation
-
Поисковые системы
- Яндекс
- Мейл Ру
- Рамблер
- Бинг
- Яху
- Аск
-
Социальные сети
- ВКонтакте
- Фейсбук
- Одноклассники
- Мой Мир
- Твиттер
- Инстаграм
-
Почта
- Мейл Ру Почта
- Гугл Почта
- Яндекс Почта
- Рамблер Почта
-
Новости
- РБК
- РИА Новости
- Лента Ру
- Яндекс Новости
- Закон KZ
-
Знакомства
- Мамба
- LovePlanet
- Love Мейл Ру
- Love Рамблер Ру
-
Словари
- Транслейт Ру
- Гугл Транслейт
- Яндекс Транслейт
- Википедия
- Грамота Ру
- Академик Ру
-
Открытки
- Все Открытки
- Давно Ру
- Солнечный Букет
- Посткард
- Плейкаст
-
Деньги
- Вебмани
- Киви
- Яндекс Деньги
-
Блоги
- Яндекс Блоги
- Лайв Журнал
- Лайв Интернет
- Сплетник
- Блог Ру
- Привет Ру Блоги
Сегодня искали:
nis.edu.kz сборники по внутреннему суммативному оцениванию …· · русский язык · физика.сборник суммативного оценивания в 7классе по русскому языку и литературе в казахской школе www.duf-obozrenie.ru 7 класс сор по казахскому языку 4четверть 1сор временний журнал 5 класс физика есептер жинағы казакша 7-9 сынып бақынов Поиск реализован с помощью YandexXML и Google Custom Search APIToloka / toloka-kit: Толока имеет мощный открытый API, он позволяет вам интегрировать рабочую силу по требованию непосредственно в ваши процессы, а также создавать масштабируемые и полностью автоматизированные конвейеры машинного обучения, работающие без участия человека. Этот инструментарий делает интеграцию еще проще, например позволяет использовать всю мощь Толоки от Jupyter Notebooks.
Документация
Веб-сайт | Документация по API | Платформа
Разработанный инженерами для инженеров, Толока позволяет вам интегрировать рабочую силу по требованию непосредственно в ваши процессы.Наша облачная платформа краудсорсинга — это быстрый и эффективный способ сбора и маркировки больших источников данных для машинного обучения и других бизнес-целей.
Основные преимущества Толоки:
- Данные высшего качества — Собирайте и аннотируйте данные обучения, которые соответствуют отраслевым стандартам качества и превосходят их благодаря множеству методов и механизмов контроля качества, доступных в Толоке.
- Масштабируемые проекты — Любые объемы изображений, текста, речи, аудио или видео данных, собранные и помеченные для вас миллионами опытных пользователей Толоки по всему миру.
- Экономическая эффективность — Экономьте время и деньги с помощью этой специально созданной платформы для обработки крупномасштабных проектов сбора данных и аннотаций, круглосуточно по запросу, без выходных, по вашей цене и в пределах вашего времени.
- Бесплатный мощный API — Создавайте масштабируемые и полностью автоматизированные конвейеры машинного обучения, работающие без участия человека, с помощью мощного открытого API.
Требования
Начало работы
Установить толока-кит проще простого:
Примечание: этот проект все еще находится в стадии интенсивной разработки, и интерфейсы могут немного измениться.Для производственных сред укажите точную версию пакета. Например: toloka-kit == 0.1.8
Попробуйте свою первую программу и проверьте действительность токена OAuth:
импорт толока.клиент как толока
toloka_client = toloka.TolokaClient (input ("Введите ваш токен:"), 'ПРОИЗВОДСТВО')
печать (toloka_client.get_requester ()) Бесплатная пробная версия
Для бесплатного ознакомления с инструментами Толока вы можете использовать промокод TOLOKAKIT1 на 20 долларов на странице своего профиля после регистрации.
Полезные ссылки
Вопросы и отчеты об ошибках
Содействие
Не стесняйтесь вносить свой вклад в толока-кит. Прямо сейчас нам действительно нужно больше примеров использования.
Лицензия
© ООО «ЯНДЕКС», 2020-2021. Под лицензией Apache License версии 2.0. См. Файл LICENSE для более подробной информации.
Обнаруженотоксичных комментариев на русском языке | Сергей Сметанин
Свобода выражения различных точек зрения, включая токсичные, агрессивные и оскорбительные комментарии, может иметь долгосрочное негативное влияние на мнение людей и социальную сплоченность.
Как следствие, способность автоматически определять и модерировать токсичный контент в Интернете для устранения негативных последствий является одной из необходимых задач современного общества. Эта статья направлена на автоматическое обнаружение токсичных комментариев на русском языке. В качестве источника данных мы использовали анонимно опубликованный набор данных Kaggle и дополнительно проверили его качество аннотации. Чтобы построить модель классификации, мы выполнили тонкую настройку двух версий многоязычного универсального кодировщика предложений, двунаправленных представлений кодировщика от Transformers и ruBERT.Finetuned ruBERT достиг F 1 = 92,20%, демонстрируя лучший классификационный балл. Мы сделали обученные модели и образцы кода общедоступными для исследовательского сообщества.
В настоящее время сайты социальных сетей стали одним из основных способов выражения мнения в Интернете. Стремительный рост контента привел к тому, что количество непроверенной информации увеличивается с каждым днем. Свобода выражения различных точек зрения, включая ядовитые, агрессивные и оскорбительные комментарии, может иметь долгосрочное негативное влияние на мнения людей и социальную сплоченность.Таким образом, возможность автоматически определять ядовитую речь и неуместный контент в Интернете для устранения негативных последствий — одна из необходимых задач современного общества. Значительное количество исследований уже было проведено крупными компаниями [23], [26], [39], [47], однако для общественного признания таких систем, ограничивающих право на свободу слова, требуется хорошее понимание и общедоступные исследования. необходимо.
В последние годы было организовано растущее количество оценочных треков, таких как [3], [21], [42], и были оценены лучшие подходы к обнаружению.В настоящее время передовые методы глубокого обучения, как правило, являются лучшим методом для решения этой задачи [1], [35]. В то время как в некоторых статьях непосредственно исследовалось обнаружение ядовитой лексики, оскорблений и языка вражды для русскоязычных [2], [8], [17], имеется только один общедоступный набор данных токсичных комментариев на русском языке [5]. Этот набор данных был опубликован на Kaggle без каких-либо подробностей о процессе аннотации, поэтому использование этого набора данных в академических и прикладных проектах без глубокого изучения может быть ненадежным.
Эта статья посвящена автоматическому обнаружению токсичных комментариев в русскоязычных текстах. Для этого мы выполнили аннотационную валидацию набора данных токсичных комментариев для русского языка [5]. Затем мы строим модели классификации, исследуя трансфертное обучение предварительно обученной многоязычной версии предварительно обученного многоязычного универсального кодировщика предложений (M-USE) [48], двунаправленных представлений кодировщика от трансформаторов (M-BERT) [13] и ruBERT [22]. ]. Лучшая модель ruBERT-Toxic достигла F 1 = 92.20% в задаче бинарной классификации. Мы сделали образец кода и настроенные модели M-BERT и M-USE общедоступными на GitHub.
Остальная часть статьи организована следующим образом. В разделе Раздел 2 мы представляем краткий обзор соответствующей работы, включая сводку существующих аннотированных наборов данных на русском языке. В разделе Раздел 3 мы даем общий обзор набора данных токсичных комментариев для русского языка и описываем процесс проверки аннотации. В Раздел 4 мы описываем принятие языковых моделей для задачи классификации текстов.В Раздел 4 мы описываем классификационный эксперимент. В заключение мы представляем производительность нашей системы и дальнейшие исследования.
Проведена большая работа по обнаружению токсичных комментариев по разным источникам данных. Например, Прабово и его коллеги оценили алгоритмы Наивного Байеса (NB), машины опорных векторов (SVM) и дерева решений случайного леса (RFDT) для обнаружения языка вражды и ненормативной лексики в индонезийском Twitter [34]. Результаты экспериментов показали точность 68.43% за иерархический подход с функциями униграммы слов и SVM-моделью. В статье [15] Founta et al. предложил глубокую нейронную сеть на основе ГРУ с предварительно обученными встраиваемыми версиями GloVe для классификации токсичных текстов. Разработанная модель достигла высокой производительности в пяти наборах данных оскорбительных текстов, при этом значение AUC варьировалось от 92% до 98%.
Растущее количество семинаров и конкурсов посвящено задачам по выявлению ядовитой лексики, языка ненависти и ненормативной лексики. Например, HatEval и OffensEval на SemEval-2019; HASOC на FIRE-2019; Совместное задание по выявлению ненормативной лексики на GermEval-2019 и GermEval-2018; TRAC на COLING-2018.Модели, используемые при отправке задач, варьируются от традиционного машинного обучения, например, SVM и логистическая регрессия, до глубокого обучения, например, RNN, LSTM, GRU, CNN, CapsNet, включая механизм внимания [45], [49], до состояния — современные модели глубокого обучения, такие как ELMo [31], BERT [13] и USE [9], [48]. Значительное количество наиболее эффективных команд [18], [24], [27], [28], [30], [36], [38] использовали вложения из перечисленных предварительно обученных языковых моделей. Поскольку представления из предварительно обученных языковых моделей продемонстрировали высокие классификационные баллы, они широко использовались в дальнейших исследованиях.Например, ученые из Университета Лотарингии выполнили мультиклассовую и бинарную классификацию твитов, используя два подхода: обучение классификатора DNN с предварительно обученными встраиваниями слов и тонкая настройка предварительно обученной модели BERT [14]. Они заметили, что точная настройка BERT работает намного лучше, чем нейронные сети CNN и Bidirectional LSTM, построенные на основе встраиваний FastText.
Хотя значительное количество исследований посвящено изучению токсического и агрессивного поведения в русскоязычных источниках в социальных сетях [7], [33], [41], существует ограниченное количество исследовательских работ, непосредственно посвященных автоматической классификации токсичности текстов. .Гордеев использовал сверточные нейронные сети (CNN) и классификатор случайного леса (RFC) для определения состояния агрессии в англоязычных и русскоязычных текстах [17]. Корпус аннотированных сообщений об агрессии составлял около 1000 аннотированных сообщений для русского и около 1000 для английского; однако он не был опубликован. Обученная модель CNN достигла 66,68% точности бинарной классификации агрессии в русскоязычных текстах. Основываясь на результатах, авторы сочли, что подходы CNN и глубокого обучения кажутся более перспективными и многообещающими в задаче обнаружения агрессии.Андрусяк и его коллеги предложили неконтролируемый вероятностный подход с исходным словарем для классификации оскорбительных комментариев с YouTube, написанных на украинском и русском языках [2]. Авторы опубликовали вручную помеченный набор данных из 2000 комментариев, но он содержит комментарии как на русском, так и на украинском языках. Следовательно, его нельзя напрямую применять для исследования русскоязычного контента.
Несколько недавних исследований были направлены на автоматическое определение отношения к мигрантам и этническим группам в русскоязычных социальных сетях, включая выявление атак на основе идентичности.Бодрунова с соавторами изучили отношение к переселенцам с постсоветского Юга по сравнению с другими странами, проанализировав 363 000 сообщений в русскоязычном Живом Журнале [8]. Они обнаружили, что мигранты не вызвали значительного объема обсуждений и не испытали наихудшего обращения в русскоязычных блогах. Более того, к северокавказцам и среднеазиатцам относились по-разному. Исследовательская группа Бессуднова обнаружила, что традиционно русские более враждебно относятся к иммигрантам с Кавказа и Средней Азии; Между тем, они обычно принимают украинцев и молдаван как своих потенциальных соседей [6].Однако, по словам Кольцовой и соавторов, различные выходцы из Центральной Азии и украинцы занимают лидирующие позиции с негативным отношением [19]. Несмотря на то, что некоторые обсуждаемые академические исследования направлены на выявление ядовитой лексики, оскорблений и языка вражды, ни одно из них не сделало свои наборы данных на русском языке общедоступными для исследовательского сообщества. Насколько нам известно, набор данных токсичных комментариев на русском языке [5] является единственным общедоступным набором данных токсичных комментариев на русском языке. Однако этот набор данных был опубликован на Kaggle без какого-либо описания процесса создания и аннотации, поэтому использование этого набора данных в академических и прикладных проектах без углубленного изучения может быть ненадежным.
Таким образом, поскольку существует минимальное количество исследований, направленных на выявление токсичности на русском языке, мы решили оценить модели глубокого обучения на наборе данных токсичных комментариев для русского языка [5]. Насколько нам известно, исследований, посвященных классификации токсичных комментариев на основе этого источника данных, не проводилось. Мы определили Multilingual BERT и Multilingual USE как одну из наиболее распространенных и успешных языковых моделей в последних документах по классификации текстов. Причем только эти языковые модели официально поддерживают русский язык.Мы решили использовать тонкую настройку в качестве подхода к переносу обучения, поскольку недавние исследования точной настройки показали лучшие результаты классификации [13], [22], [43], [48].
Kaggle Russian Language Toxic Comments Dataset [5] — это набор аннотированных комментариев от 2ch и Pikabu, который был опубликован на Kaggle в 2019 году. Он состоит из 14 412 комментариев, из которых 4826 текстов были помечены как токсичные, а 9 586 — как нетоксичные. . Средняя длина комментариев составляет 175 символов; минимальная длина — 21, максимальная — 7,403.
Чтобы проверить качество аннотации набора данных, мы решили вручную аннотировать подмножество комментариев и сравнить исходные ярлыки и наши ярлыки с использованием показателей соглашения между аннотаторами. Мы решили считать аннотацию набора данных действительной в случае достижения существенного или высокого уровня соглашения между аннотаторами. Для начала мы выполнили аннотацию части этого набора данных (3000 комментариев), а затем сравнили наши метки классов с исходными. Аннотацию проводили русскоговорящие на краудсорсинговой платформе Яндекс.Толока, которая уже использовалась в нескольких академических исследованиях русскоязычных текстов [10], [29], [32], [44]. В качестве руководства по аннотации мы использовали инструкции по аннотации токсичности с податрибутами из Jigsaw Toxic Comment Classification Challenge. Согласно руководящим принципам, аннотаторов попросили выявлять токсичность текстов в коллекции онлайн-комментариев. Для каждого предоставленного комментария аннотаторы должны были выбрать уровень токсичности в комментарии. Чтобы получить более точные ответы от аннотаторов и ограничить доступ к задачам для читерских аннотаторов, мы использовали следующие методы: назначение навыков аннотаторам на основе их ответов на контрольные задачи и запрет исполнителей, которые дают неправильные ответы; ограничение доступа к пулу для аннотаторов, которые отвечают слишком быстро; ограничение доступа к задачам для аннотаторов, которые несколько раз подряд не вводят капчу.Каждый пост аннотировали от 3 до 8 аннотаторов с использованием метода динамического перекрытия. Далее результаты были агрегированы по методу Давида-Скене [12] на основе рекомендаций Яндекс.Толоки. Аннотаторы продемонстрировали высокую степень согласованности между аннотаторами, согласно альфа-значению Криппендорфа 0,81. Наконец, коэффициент Каппа Коэна между исходными и нашими агрегированными метками составил 0,68, что, согласно Коэну [11], является существенным уровнем согласия между аннотаторами. В результате мы предположили, что аннотация набора данных действительна, особенно с учетом возможных различий в инструкциях по аннотации.
4.1. Базовые показатели
В качестве базовых подходов мы выбрали один базовый подход на основе машинного обучения и один современный подход на основе нейронных сетей. В обоих случаях мы применили следующие методы предварительной обработки: замену URL-адресов и имен пользователей ключевыми словами, удаление знаков препинания и преобразование строк в нижний регистр.
Первым был Multinomial Naive Bayes (MNB), который, как правило, хорошо справлялся с задачей классификации текстов [16, 40]. Для построения модели MNB мы использовали модель Bag-of-Words и векторизацию TF-IDF.
Второй — нейронная сеть с двунаправленной долгосрочной краткосрочной памятью (BiLSTM), которая продемонстрировала высокие классификационные баллы в недавних исследованиях анализа настроений. Для слоя встраивания нейронной сети мы предварительно обучили вложения Word2Vec ( dim = 300) [25] на коллекции русскоязычных твитов от RuTweetCorp [37]. Поверх вложений Word2Vec мы добавили два сложенных слоя Bidirectional LSTM. Затем мы добавили скрытый полностью связанный слой и выходной слой сигмоида.Чтобы уменьшить переобучение, в нейронную сеть также были добавлены слои регуляризации с гауссовым шумом и слои исключения. Мы использовали оптимизатор Adam с начальной скоростью обучения 0,001 и категориальной двоичной кросс-энтропией в качестве функции потерь. Мы обучили нашу сеть замороженным вложениям для 10 эпох. Мы пытались разморозить вложения в разные эпохи с одновременным снижением скорости обучения, но лучших результатов не добились. Вероятно, это было связано с размером обучающего набора данных [4].
4.2. Представления двунаправленного кодера от трансформаторов
В настоящее время официально доступны две многоязычные версии BERT_BASE, но официально рекомендуется только версия Cased. BERT_BASE принимает последовательность, состоящую не более чем из 512 токенов, и выводит представление этой последовательности. Токенизация выполняется токенизатором WordPiece [46] с предварительной нормализацией текста и разделением знаков препинания. На основе BERTBASE Cased исследователи из Московского физико-технического института предварительно обучили и опубликовали модель ruBERT для русского языка [22].Мы использовали предварительно обученные Multilingual BERT_BASE Cased и ruBERT, которые поддерживают 104 языка, включая русский, с 12 сложенными блоками Transformer, скрытым размером 768, 12 самовнимающими головами и 110M параметрами в целом. Этап тонкой настройки был выполнен с рекомендованными параметрами из статьи [43] и официального репозитория [2]: количество эпох поездов 3, количество шагов разогрева 10%, максимальная длина последовательности 128, размер пакета 32 и скорость обучения 5e-5.
4.3. Многоязычный универсальный кодировщик предложений
В качестве входных данных Multilingual USE_Trans принимает последовательность не более чем из 100 токенов, тогда как Multilingual USE_CNN принимает последовательность не более чем из 256 токенов. Токенизация SentencePiece [20] используется для всех поддерживаемых языков. Мы использовали предварительно обученные многоязычные USETrans, которые поддерживают 16 языков, включая русский, с кодировщиком Transformer с 6 слоями преобразователя, 8 головками внимания, размером фильтра 2048, скрытым размером 512 и 16 параметрами в целом.Мы также использовали предварительно обученный многоязычный USE_CNN, который поддерживает N языков, включая русский, с кодировщиком CNN с 2 слоями CNN, шириной фильтра (1, 2, 3, 5), размером фильтра 256 и N параметрами в целом. Для обеих моделей мы использовали рекомендуемые параметры со страницы TensorFlow Hub: количество эпох обучения 100, размер пакета 32 и скорость обучения 3e-4.
Мы оценили следующие подходы базового и трансферного обучения: полиномиальный наивный байесовский классификатор, нейронная сеть с двунаправленной долгосрочной памятью (BiLSTM), многоязычная версия представления двунаправленного кодера от трансформаторов (M-BERT), ruBERT, две версии Multilingual Universal Кодировщик предложений (M-USE).Эффективность классификации обученных моделей на тестовом подмножестве (20%) можно найти в таблице 2. Все тонко настроенные языковые модели превосходят базовые подходы с точки зрения точности, отзывчивости и 1-меры F . По результатам, ruBERT достиг F 1 = 92,20%, показав лучший классификационный балл.
Таким образом, мы настроили две версии Multilingual Universal Sentence Encoder [48], Multilingual Bidirectional Encoder Views from Transformers [13] и RuBERT [22] для обнаружения токсичных комментариев на русском языке.После точной настройки RuBERTToxic достиг F 1 = 92,20%, продемонстрировав лучший классификационный балл. Вклад этого исследования в практику и исследования тройной. Во-первых, мы изложили имеющуюся базу знаний по обнаружению токсичных комментариев в русскоязычном контенте. При этом мы выявили единственный существующий набор данных токсичных комментариев на русском языке, который является общедоступным. Во-вторых, мы выполнили проверку качества аннотаций для этого набора данных, поскольку он был анонимно опубликован на Kaggle.Наконец, чтобы обеспечить дальнейшие исследования с надежными базовыми классификациями, мы сделали предварительно обученные модели на основе многоязычного BERT, ruBERT и многоязычного USE общедоступными для исследовательского сообщества.
Вы можете найти все ссылки в документе конференции.
Яндекс — Википеди
Википеди, özgür ansiklopedi
Яндекс (Rusça: Яндекс) 1997 yılında kurulan Rusya merkezli çok uluslu bir firmadır. Yandex başta internet tabanlı ürünler ve hizmetleri kapsamak üzere ulaşım, e-ticaret, navigasyon, mobil uygulama ve reklamcılık gibi birçok alanda hizmet veren butmişten fazla servise sahiptir.Яндекс в ana pazarı Rusya ve Bağımsız Devletler Topluluğu’dur. Rusya’nın en büyük teknoloji şirketidir ve% 60,09 pazar payıyla arama motoru pazarının lideridir. [3] Яндекс dünya çapında 17 ülkede 30 office sahiptir, ancak şirketin kurucuları ve çalışanlarının çoğu Rusya’da bulunur. Google ве Baidu’nun ardından dünyanın en büyük 3. arama motorudur. [4]
Türkiye’de% 15,83 [5] pazar payı ile Türkiye’de en çok kullanılan 2. arama motoru olmuştur. Irketin amacı kullanıcıların sorularına doğrudan veya dolaylı cevap verebilmektir. [6]
Yandex.ru ana sayfası Rusya’da en çok ziyaret edilen internet sitesi olmuştur. [7] Яндекс, tüm dünyada 56 milyondan fazla kullanıcıya ulaşmaktadır. [8] Rusya’nın yanı sıra Беларусь, Казахстан, Украина ве Türkiye’de de hizmet vermektedir. [9] Tamamen Yandex’e ait olan alt birim şirketi, Yandex Labs ise San Francisco Körfez Bölgesi’ndir ve bir ar-ge labratuvarı görevi görmektedir.
Яндекс, 30 марта 2015 г. десять раз Mozilla Firefox’un [10] ве 13 Эким 2015 г. десять раз Microsoft Edge в Турции ичин варсайылан арама мотору олду.Ayrıca Microsoft ile anlaşmalıdır. Microsoft’un haber sitesi MSN’deki arama motoru Yandex’tir.
Ayrıca 20 Mayıs 2020 tarihinde Huawei, Google kendisine ambargo uyguladığı için, Rusya ve Türkiye’de, telefonlarında varsayılan arama motoru olması için Яндекс ile anlaşmıştır. Bununla birlikte Huawei, kendi uygulama mağazası AppGallery’ye Яндекс.Нави, Браузер, Диск gibi Яндекс uygulamalarını entegre etmeye başlamıştır. [11]
Nisan 2014’te Yandex’in hikâyesini anlatan Startup adlı bir film yayınlandı [12]
Яндекс ismini, 1996 yılında, şirketin kurucuları İlya Segaloviç ve Arkadiy Voloj koymuştur.İngilizce «dizin oluşturmak» anlamına gelen «для индексации» fiilinden yola çıkarak «еще один индексатор» (bir dizin oluşturucu daha) ifadesinin kısaltılmış hali olan «Yandex» te karar kılmışlardı. Яндекс, Rusçada «Яндекс» şeklinde yazılır. «Я» харфи («Я» дийе окунур.) Кирил алфабесине özgü бир харфтир ве İngilizcede birinci tekil şahıs «бен» замирини ифаде эден «I» харфине каршылык гелир. [13]
Яндекс gelirinin büyük bir kısmını Яндекс.Директ adlı içeriğe dayalı reklamcılık sisteminden elde eder.Bu sistemde, reklamlar kullanıcıların arama motorunda yaptığı sorgularla eşleştirilir ve böylece istenilen kitlenin hedeflenmesi sağlanır. Reklamlar ayrıca Yandex’in çözüm ortağı olan web sitelerinde de gösterilir. Яндекс.Директ Rusya’da lider konumdadır.
мая 2011’de NASDAQ’da halka arz edilmiş olan Yandex’in gelirinin küçük bir bölümü de medya bazlı reklamcılık kaynaklıdır. Toplam gelirin% 95’i Rusya piyasasından elde edilmektedir. [14]
Яндекс, Eylül 2011’de İstanbul’da açtığı ofisle Türkiye pazarına açılmıştır. [15] «Türkiye’deki kullanıcılar ve Türkiye hakkında bilgi arayan herkes için geliştirilmiş» [16] olan yandex.com.tr ‘ nin kullanıcılarına sundadizu.
Bunun yanı sıra canlı trafik bilgisi ve Panoramik fotoğraflar içeren Yandex.Haritalar, haberler ve e-posta gibi birçok farklı servisi de sunmaktadır. Яндекс.Haritalar’ın Panorama adlı hizmeti kullanıcılara yüksek çözünürlüklü, 360 derecelik açıya sahip görüntüler sunarak İstanbul, Ankara, İzmir ve daha birçok san şehirdeı şehirdeı â [17]
— ° ´ ° ‡ ¸ ¼ ° ˆ¸½½¾³¾ ¾ ± ƒ ‡ µ½¸ — [PDF-документ]
.
20 2016.
Интернет-2003. . . . 2007 г. . . . 2016 г. . . . 0
() 20 2016. 2/55
.1, Цифровая региональная сеть Hearst Shkulev.
1 http://techno.ngs.ru/ () 20 2016 г. 3/55
http://techno.ngs.ru/
N1.RU
N1.RU
N1.RU2. , 42, Цифровая сеть Херста Шкулева3.
2 http://n1.ru/3http: //www.hearst-shkulev-media.ru/projects/rn/
() 20 2016 г. 4/55
http://n1.ru/http://www.hearst-shkulev-media.ru/projects/rn/
,,.
ru.wikipedia.org
,,,.
() 20 2016. 5/55
:,. . .
() 20 2016. 6/55
:.. .
() 20 2016. 7/55
:
() 20 2016. 8/55
::
(структурированное обучение). . .
:. . .
(обучение с подкреплением). . .
() 20 2016. 9/55
X -, Y -, (), x X () y Y, f: X Y
« x X y Y
() 20 2016. 10/55
,
() 20 2016.11/55
() 20 2016. 12/55
() 20 2016. 13/55
, (/)
OLAPa
ahttps: //en.wikipedia.org/wiki/Online_analytical_processing
,
() 20 2016 г. 14/55
https://en.wikipedia.org/wiki/Online_analytical_processing
REST, прибыль
() 20 2016 г. 15/55
() 20 2016.16/55
() 20 2016. 17/55
() 20 2016. 18/55
() 20 2016. 19/55
, —
() 20 2016. 20/55
?
!
() 20 2016. 21/55
: возраст = год текущий год постройки: exists_balcony = I [| балконы | + | лоджии | > 0]: area =
жилая | комнаты |
().. .
() 20 2016. 22/55
0 1
0
1000000
2000000
3000000
4000000
5000000
6000000цена
Boxplotgroupedbyexists_balcony (
) 23/55
0,2 0,0 0,2 0,4 0,6 0,8 1,0 1,2 цена 1e7
0
1
2
3
4
5
6
7
1e 7
среднее значение 7
.pricei = Dj = 1
(wjxij) + w0
argminw
Ni = 1
Dj = 1
(wjxij) + w0 pricei
2 + Dj = 1
w2j
203() 25/55
() 20 2016. 26/55
4
4 http://www.r2d3.us/ () 20 2016 г. 27/55
http://www.r2d3.us/
площадь
цена = 10000003
цена = 150000050
() 20 2016.28/55
XGBoost5,
5 https://github.com/dmlc/xgboost () 20 2016 г. 29/55
https://github.com/dmlc/xgboost
() 20 2016 г. 30/55
0,2 0,0 0,2 0,4 0,6 0,8 1,0 1,2
1e70.2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1e7
02 R0,2 0,0 0.2 0,4 0,6 0,8 1,0 1,2
1e70.2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1e7
R 2 = 0,885078686709
31/55
0,2 0,0 0,2 0,4 0,6 0,8 1,0 1,2
1e70.2
0,0
0,2
0,4
0,6
0,8
1,0
1,2
1e7
= 0,R
() 20 2016.32/55
0
() 20 2016. 33/55
()
() 20 2016. 34/55
() 20 2016. 35/55
.
, a
Caffeb
ahttps: //en.wikipedia.org/wiki/Convolutional_neural_networkbhttp: //caffe.berkeleyvision.org/
() 20 2016 г. 36/55
https://en.wikipedia.org/wiki/Convolutional_neural_networkhttp://caffe.berkeleyvision.org/
«
«
,.
6
Amazon Mechanical Turk7
,
6 https://toloka.yandex.ru/7 https://www.mturk.com/mturk/welcome
() 20 2016 г. 37/55
https://toloka.yandex.ru/https://www.mturk.com/mturk/welcome
«
() 20 2016. 38/55
«
«
класс 3452 ванная 1415 кухня 1250 фасад 1048 просмотр 555 план 456 вход 260
() 20 2016.39/55
«
() 20 2016. 40/55
«
8k, 100k (Fine-tuning8), ImageNet с полным подключением 1000 7
8 http://caffe.berkeleyvision.org/gasted/examples/finetune_flickr_style.html () 20 2016. 41/55
http://caffe.berkeleyvision.org/golated/examples/finetune_flickr_style.html
«
«
NVIDIA QuadroM400024 0,9964 0,92
() 20 2016 г.42/55
() 20 2016. 43/55
() 20 2016. 44/55
() 20 2016. 45/55
() 20 2016. 46/55
() 20 2016. 47/55
() 20 2016. 48/55
, 7 ()
() 20 2016. 49/55
() 20 2016. 50/55
() 20 2016.51/55
200k + a
70k + 20«
a (/)
() 20 2016. 52/55
,
,
,
() 20 2016. 53/55
,
() 20 2016. 54/55
!
?
[email protected] https://www.facebook.com/alexey.sibirtsev https://ru.linkedin.com/in/alexeysibirtsev
() 20 2016 г.55/55
[email protected] https://www.facebook.com/alexey.sibirtsevhttps: //ru.linkedin.com/in/alexeysibirtsev
N1.RU
,,
,
𝐌𝐚𝐱𝐚𝐦𝐮𝐮𝐝 Cagasaydh 【M】 【m】 【j】, Togdheer Region (+252634291274)
Maxamuud Cagasaydh Mmj — Главная | Facebook
m.facebook.com
Sidee Soomaaliddu ugu midoobi kartaa qadiyaddaha guud sida arrinta Badda ee kala dhaxeysa Kenya? La wadaag saaxiibadaa.Как могут сомалийцы объединиться с общим …
Сомалиленд воскей гаартай виксии ау … — Максамууд Кагасайд Ммдж …
www.facebook.com
Максамууд Кагасайд Ммж … Только в июле, аль- Шабааб нацелился на главу вооруженных сил Сомали и за один день нанес удары по пяти различным целям …
сомали — Wikipedia-statistik — Таблицы
stats.wikimedia.org
Эти показатели представлены в столбцах F, I, J , K, M, N, O, P, Q, R из первой таблицы.См. Также определения показателей … Maxamuud Cagasaydh mmj 1 · UC, 539.
BBCSomali.com | Варарка | Maxamed Maxamuud Guuleed oo is casilay
www.bbc.com
MM Guuleed · Maxamed Maxamuud Guuleed Waxaa Ra’iisul Wasaare u magacaabay Madaxweynaha …
Яндекс.Толока статистика — Общая информация о входе 9014 Войти 9014 Вход в систему. co.uk
Статистика Википедии — Таблицы — Сомали — Статистика Викимедиа… Maxamuud Cagasaydh mmj 1 · UC, 539 … 4, 4, 3, 3, 24 декабря 2018 г., 6, -, -, -, -.
Maxamuud M Xasan ihn | Heestii Haasawaha Adigan ku Hoday …
m.youtube.com
Продолжительность: 5: 32Опубликовано: 29 марта 2021 г.
Axmed Cumar Cagasaydh | Flickr
www.flickr.com
Axmed Cumar Cagasaydh. Следовать. Дайте Pro. cagasaydh2. 5 подписчиков • 0 подписок. 132 Фото. Присоединился к 2014. О проекте · Фотопоток · Альбомы · Любимые · Галереи…
Фактическая причина, по которой Галмудуг сражается в Галкайо, объясняет TGS …
www.somalinet.com
24 ноя 2015 · С момента окончания гражданской войны Кумар Максамуд расширился … mj расширились на своей стороне там, где раньше были базы СНС …
Яндекс — Википеди
Яндекс (Rusça: Яндекс) 1997 yılında kurulan Rusya merkezli çok uluslu bir firmadır. Yandex başta internet tabanlı ürünler ve hizmetleri kapsamak üzere ulaşım, e-ticaret, navigasyon, mobil uygulama ve reklamcılık gibi birçok alanda hizmet veren butmişten fazla servise sahiptir.Яндекс в ana pazarı Rusya ve Bağımsız Devletler Topluluğu’dur. Rusya’nın en büyük teknoloji şirketidir ve% 60,09 pazar payıyla arama motoru pazarının lideridir. [3] Яндекс dünya çapında 17 ülkede 30 office sahiptir, ancak şirketin kurucuları ve çalışanlarının çoğu Rusya’da bulunur. Google ве Baidu’nun ardından dünyanın en büyük 3. arama motorudur. [4]
Türkiye’de% 15,83 [5] pazar payı ile Türkiye’de en çok kullanılan 2. arama motoru olmuştur. Irketin amacı kullanıcıların sorularına doğrudan veya dolaylı cevap verebilmektir. [6]
Yandex.ru ana sayfası Rusya’da en çok ziyaret edilen internet sitesi olmuştur. [7] Яндекс, tüm dünyada 56 milyondan fazla kullanıcıya ulaşmaktadır. [8] Rusya’nın yanı sıra Беларусь, Казахстан, Украина ве Türkiye’de de hizmet vermektedir. [9] Tamamen Yandex’e ait olan alt birim şirketi, Yandex Labs ise San Francisco Körfez Bölgesi’ndir ve bir ar-ge labratuvarı görevi görmektedir.
Яндекс, 30 марта 2015 г. десять раз Mozilla Firefox’un [10] ве 13 Эким 2015 г. десять раз Microsoft Edge в Турции ичин варсайылан арама мотору олду.Ayrıca Microsoft ile anlaşmalıdır. Microsoft’un haber sitesi MSN’deki arama motoru Yandex’tir.
Ayrıca 20 Mayıs 2020 tarihinde Huawei, Google kendisine ambargo uyguladığı için, Rusya ve Türkiye’de, telefonlarında varsayılan arama motoru olması için Яндекс ile anlaşmıştır. Bununla birlikte Huawei, kendi uygulama mağazası AppGallery’ye Яндекс.Нави, Браузер, Диск gibi Яндекс uygulamalarını entegre etmeye başlamıştır. [11]
Nisan 2014’te Yandex’in hikâyesini anlatan Startup adlı bir film yayınlandı [12]
Яндекс ismini, 1996 yılında, şirketin kurucuları İlya Segaloviç ve Arkadiy Voloj koymuştur.İngilizce «dizin oluşturmak» anlamına gelen «для индексации» fiilinden yola çıkarak «еще один индексатор» (bir dizin oluşturucu daha) ifadesinin kısaltılmış hali olan «Yandex» te karar kılmışlardı. Яндекс, Rusçada «Яндекс» şeklinde yazılır. «Я» харфи («Я» дийе окунур.) Кирил алфабесине özgü бир харфтир ве İngilizcede birinci tekil şahıs «бен» замирини ифаде эден «I» харфине каршылык гелир. [13]
Яндекс gelirinin büyük bir kısmını Яндекс.Директ adlı içeriğe dayalı reklamcılık sisteminden elde eder.Bu sistemde, reklamlar kullanıcıların arama motorunda yaptığı sorgularla eşleştirilir ve böylece istenilen kitlenin hedeflenmesi sağlanır. Reklamlar ayrıca Yandex’in çözüm ortağı olan web sitelerinde de gösterilir. Яндекс.Директ Rusya’da lider konumdadır.
мая 2011’de NASDAQ’da halka arz edilmiş olan Yandex’in gelirinin küçük bir bölümü de medya bazlı reklamcılık kaynaklıdır. Toplam gelirin% 95’i Rusya piyasasından elde edilmektedir. [14]
Яндекс, Eylül 2011’de İstanbul’da açtığı ofisle Türkiye pazarına açılmıştır. [15] «Türkiye’deki kullanıcılar ve Türkiye hakkında bilgi arayan herkes için geliştirilmiş» [16] olan yandex.com.tr ‘ nin kullanıcılarına sundadizu.
Bunun yanı sıra canlı trafik bilgisi ve Panoramik fotoğraflar içeren Yandex.Haritalar, haberler ve e-posta gibi birçok farklı servisi de sunmaktadır. Яндекс.Haritalar’ın Panorama adlı hizmeti kullanıcılara yüksek çözünürlüklü, 360 derecelik açıya sahip görüntüler sunarak İstanbul, Ankara, İzmir ve daha birçok san şehirdeı şehirdeı â [17]
Понимание взаимодействия ИИ и человека для стимулирования творческих усилий
В то время как многие могут подумать, что творчество станет ключевым человеческим потенциалом по мере того, как рабочие процессы становятся все более автоматизированными, приложения ИИ также становятся более креативными: например, портреты, нарисованные ИИ, продаются по непомерным ценам, поп-хиты включают музыку, созданную ИИ, и мейнстрим. СМИ «нанимают» AI-журналистов для публикации тысяч статей в неделю. Как AI-приложение на рабочем месте повлияет на творческие процессы, имеющие решающее значение для инноваций и организационного развития, — важный вопрос, требующий пристального научного внимания.
Что исследования могут привнести в сферу творчества с искусственным интеллектом?
Research может помочь найти способы стимулировать творческую работу и инновации, дополненные многочисленными возможностями искусственного интеллекта. Нам нужны исследования, которые объясняют, как мы можем создавать и адаптировать искусственных агентов и организовывать рабочие процессы таким образом, чтобы сотрудникам не приходилось защищаться от ИИ и быть более креативными.
К настоящему времени мы узнали, что многие люди считают, что искусственные агенты — это, например, приложения с искусственным интеллектом, такие как Siri или Alexa, или социальные роботы, которых вы можете увидеть в аэропорту, — не подходят для творческой работы или работы, требующей дипломатия и навыки суждения.Итак, обычно люди не заботятся об искусственном интеллекте, пытающемся сочинить симфонию или написать роман, если они верят, что люди творчески превосходят их. Но мы также знаем, что когда ИИ участвует в творческой работе — например, создает предложения изображений или даже создает логотипы в дизайн-студии, люди часто отвергают его результаты и оценивают их ниже, даже если ИИ объективно работает так же хорошо, как и человек. .
Это проблема, потому что, когда сотрудники считают, что ИИ не должен быть творческим, а оказывается, что это именно так, они могут чувствовать угрозу от него, опасаясь, что он может заменить их, и эти чувства обычно не очень способствуют творчеству.Кроме того, в случае угрозы сотрудники будут пытаться защитить себя — в конце концов, мы хотим чувствовать, что мы, люди, творческий вид, уникальны. Следовательно, это также может мешать творческой работе.
Как ваше исследование может помочь в управлении творческими взаимодействиями человека и ИИ?
Вместе с моим научным руководителем профессором Матисом Шульте мы исследуем различия в том, как люди работают над творческими и нетворческими задачами, когда они сотрудничают с ИИ, соревнуются с ним или используют результаты его работы в качестве эталона для собственной производительности.Мы также исследуем, чем эти взаимодействия отличаются от тех же ситуаций, в которых участвует человек, а не агент ИИ.
Творческое взаимодействие с ИИ — это зарождающаяся область управленческих знаний, и мы рады внести свой первый вклад в ее развитие. Мы показываем, например, что люди используют одни и те же психологические механизмы, сравнивая себя с агентами ИИ, даже если они считают, что эти агенты не могут реально конкурировать с людьми творчески. Мы также показываем, что то, что мы думаем о себе и об ИИ, имеет значение, и хотя одни убеждения могут заставить сотрудников усерднее работать над творческими задачами, другие могут демотивировать их.Знание этих конфигураций поможет менеджерам наладить сотрудничество таким образом, чтобы ИИ использовался на полную мощность, а люди процветали в творческой работе.
Мы показываем, например, что люди используют одни и те же психологические механизмы при сравнении себя с агентами ИИ, даже если они считают, что эти агенты не могут реально конкурировать с людьми творчески.
Итак, какие основные различия вы видите между творческими взаимодействиями человек-человек и человек-ИИ?
Прежде всего, мы увидели, что люди не тратили столько времени на работу над творческой задачей — то есть они не прилагали таких усилий — когда они сотрудничали с ИИ, как когда они сотрудничали с коллегой.Это не относилось к нетворческой задаче, в которой люди работали в среднем в одно и то же время как с ИИ, так и с сотрудником-человеком. Чтобы проиллюстрировать, в одном из наших экспериментов творческая задача заключалась в том, чтобы предложить идеи переработки медицинской маски (эта задача могла быть, например, вызовом на инженерном конкурсе или темой для развлекательной статьи, которая была установка в нашем эксперименте). Некреативная задача заключалась в том, чтобы найти слова, связанные с переработкой, в матрице слов, которые нужно было протестировать как игру для публикации в Интернете.
Матрица поиска словЛюди не так усердно работали над творческой задачей, когда они сотрудничали с ИИ, как когда они работали с коллегой.
Мы также обнаружили, что производительность ИИ не имеет значения при таком уменьшении усилий. В другом эксперименте мы попросили участников предложить идеи о том, как мотивировать своих коллег больше двигаться или лучше питаться. Затем мы показали им либо список бессмысленных идей (который на самом деле был текстом, созданным алгоритмом!), Либо список разумных идей.Мы сказали участникам, что список, который они видят, был создан ИИ или кем-то еще, кто также участвовал в эксперименте. В результате одни люди видели бессмысленный список идей и думали, что он был предложен ИИ, а другие думали, что тот же список был предложен человеком. Что касается списка разумных идей, третья группа увидела разумный список, который якобы был написан искусственным интеллектом, и последняя группа подумала, что это было предложение человека. Затем мы снова попросили участников предложить идеи по одной из тем.Мы обнаружили, что независимо от того, имели ли идеи смысл или нет, участники, которые смотрели на идеи, которые были представлены так, как были предложены другими людьми, занимали второе задание почти на полминуты дольше, чем те, кто считал, что идеи были созданы искусственным интеллектом.
Интересно, что так было и в нетворческой задаче, в которой участники искали конкретного персонажа на старорусской бересте, смотрели на результаты работы ИИ или человека и снова искали другого персонажа. .Хотя мы этого и не ожидали, участники, которые увидели результаты работы ИИ, как хорошо, так и не удалось, во втором раунде потратили меньше времени на работу над задачей.
Результаты этих двух экспериментов показывают, что во многих случаях, особенно когда мы думаем, что ИИ не место в творческой работе, у нас может быть меньше мотивации прилагать к нему усилия, чем при совместной работе с другим человеком.
Во многих случаях у нас может быть меньше мотивации прилагать усилия к творческой работе при участии ИИ, чем при совместной работе с другим человеком.
Итак, в каких условиях ИИ может побудить нас усерднее работать над творческой задачей?
Этим мы занялись в следующем эксперименте. В нем мы снова предложили участникам подумать о творческих идеях использования медицинской маски или медицинских перчаток. Но, в отличие от первого эксперимента, мы сначала незаметно заставили половину участников вспомнить, что творчество — это то, что делает людей уникальными, в то время как другая половина не видела такого напоминания.Мы также сказали участникам, что либо ИИ, либо человек придумал либо много творческих идей, либо всего несколько. Результаты этих манипуляций были ошеломляющими: в то время как люди, которым напомнили, что творчество — это уникальная человеческая черта, и увидели, что ИИ придумал 20 идей, работали в среднем почти полные пять минут, те, кому также напоминали об уникальности творчества, но видели, что это Человек, придумавший 20 идей, работал над задачей всего за 3,5 минуты. Мы также увидели, что когда высокая творческая производительность ИИ была неожиданной, людям этот ИИ гораздо больше угрожал.
Какое значение эти выводы имеют для практики?
Эти выводы имеют очень важное практическое значение: что мы должны рассказывать сотрудникам об ИИ-приложениях, которые можно использовать в творческой работе, чтобы они не отвлекались, поскольку им нечего доказывать против якобы некреативного ИИ? Как мы мотивируем их к творчеству, не пугая их искусственным интеллектом? Это вопросы, которые я с нетерпением жду решения в моей будущей работе.
Вы используете необычные онлайн-сервисы для проведения исследования.Можете описать, как вы набираете участников и почему эти услуги так привлекательны?
Люди, которые участвовали в этих экспериментах, набирались либо на Prolific, довольно популярном британском сервисе академических исследований, либо на Яндекс.Толоке, российском сервисе для найма отдельных сотрудников для выполнения таких мини-задач, как разметка данных.
Использование обеих платформ — большое преимущество. Во-первых, я могу проверить, универсальны ли предполагаемые мной эффекты для разных культур и национальностей.Во-вторых, поскольку специализированные платформы в последнее время подвергаются критике за качество данных, люди, которых я нанимаю в Яндекс.Толоке, которая в основном используется бизнесом для краудсорсинга, наивны для экспериментальных исследований и, поскольку большинство этих задач являются довольно механическими и скучными, они внутренне мотивированы участвовать в моих экспериментах — я получил довольно много сообщений от участников, в которых говорилось, что им понравилось «задание» и они были бы готовы сделать это снова. Хотя, к сожалению для этих участников, это не может не поставить под угрозу целостность исследования, я думаю, что это многое говорит о том, что люди вряд ли будут саботировать участие.
Я могу проверить, универсальны ли предполагаемые мной эффекты для разных культур и национальностей.
Наконец, Яндекс.Толока предлагает отличный гендерный баланс в выборке (51% участников, которых я набираю случайным образом, — женщины), люди принадлежат к разным слоям общества и в большинстве своем имеют довольно большой опыт работы — их средний возраст почти 36 лет.